
インテルは、5nmプロセス・ノードをベースとし、エヌビディアのH100 GPUと直接競合する次世代AIアクセラレータ「Gaudi 3」をついに発表した。
インテルGaudi 3 AIアクセラレータがNVIDIAに戦いを挑む、40%の効率化を実現しながら平均50%高速なAIパフォーマンスを提供
IntelのGaudi AIアクセラレータは、AI分野でNVIDIAのGPUに代わる唯一の選択肢であり、大きな競争相手となっている。
私たちは最近、Gaudi 2とNVIDIA A100/H100 GPUのベンチマーク比較で、NVIDIAが性能面でAI全体のリーダーであり続ける一方で、Intelはその強力なperf/$リードを見せつけました。
そして今、インテルのAIの旅の第3章が、その詳細が明らかになったGaudi 3アクセラレーターとともに始まる。

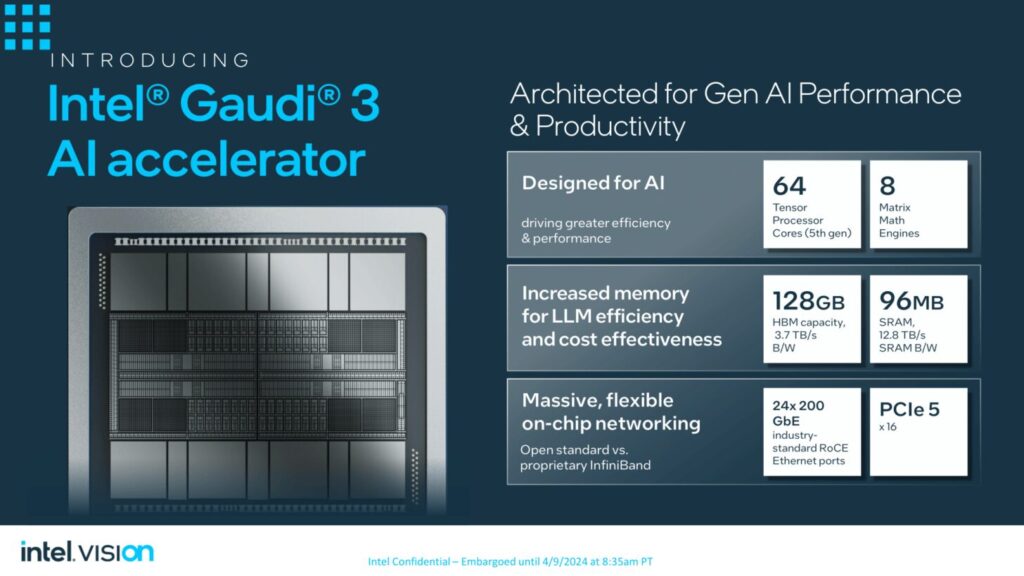
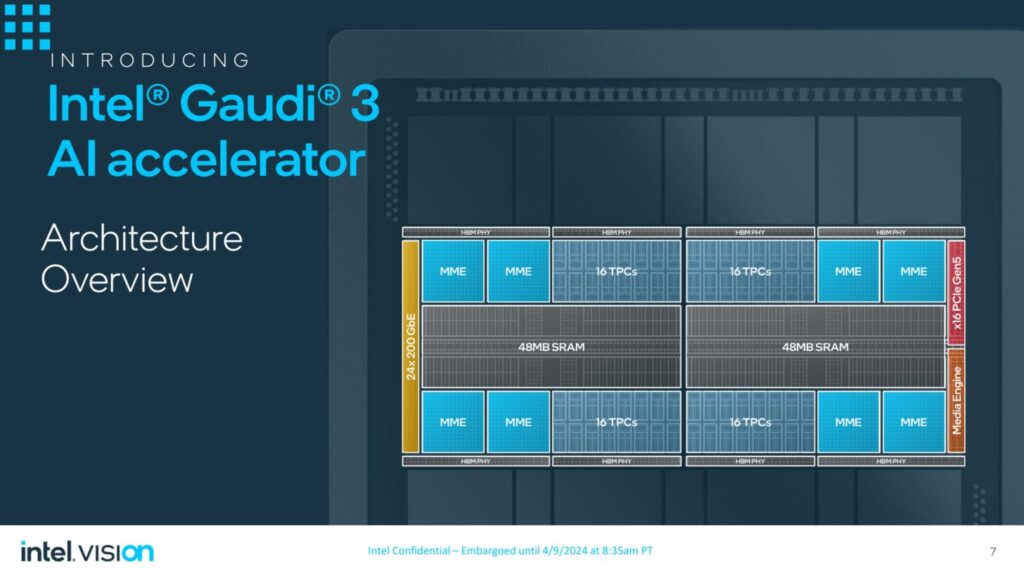
同社はGaudi 3アクセラレータを発表した。このアクセラレータは最新(第5世代)のTensor Coreアーキテクチャを採用し、2つのコンピュート・ダイに合計64個のテンソルコアが搭載されている。
GPU自体には、両方のダイで共有される96MBのキャッシュ・プールがあり、それぞれ最大128GBの容量と最大3.7TB/秒の帯域幅を持つ16Gb HBM2e DRAMの8-hiスタックを備えた8つのHBMサイトがある。チップ全体はTSMC 5nmプロセス・ノード技術で製造され、合計24本の200GbE相互接続リンクがあります。


インテルGaudi 3 AIアクセラレータは、最大900Wの標準仕様と900W超の液冷仕様のMezzanine OAM(HL-325L)フォームファクタと、フルハイト、ダブルワイド、長さ10.5インチのPCIe AICの両方で提供される。Gaudi 3 HL-338 PCIeカードはパッシブ冷却で、OAMバリアントと同じ仕様でTDP 600Wまでサポートします。



また、最大8基のGaudi 3アクセラレータを搭載できる独自のHLB-325ベースボードとHLFB-325L統合サブシステムも発表した。このシステムのTDPは7.6キロワットで、サイズは19インチである。
Gaudi 3へのフォローアップは、2025年に予定されているFalcon Shoresの形で行われ、Intel oneAPI仕様に基づいて構築された単一のGPUプログラミング・インターフェイスにGaudiとXeの両方のIPを統合する予定です。
プレスリリース: インテルは、Intel Visionにおいて、Intel Gaudi 3 AIアクセラレーターを発表します。
このアクセラレーターは、前モデルと比較して、BF16で4倍のAIコンピュート、1.5倍のメモリー帯域幅の増加、大規模なシステム・スケールアウトのための2倍のネットワーク帯域幅を実現します。
インテル Gaudi 3アクセラレーターは、これらの要件を満たし、オープン・コミュニティー・ベースのソフトウェアとオープンな業界標準イーサネットを通じて汎用性を提供し、企業がAIシステムとアプリケーションを柔軟に拡張できるよう支援します。
カスタム・アーキテクチャがGenAIのパフォーマンスと効率性を実現する方法: 効率的な大規模AIコンピューティングのために設計されたIntel Gaudi 3アクセラレータは、5ナノメートル(nm)プロセスで製造され、前世代よりも大幅に進化しています。 マトリックス乗算エンジン(MME)、テンソル・プロセッサー・コア(TPC)、ネットワーキング・インターフェース・カード(NIC)など、すべてのエンジンを並列に起動できるように設計されており、高速で効率的なディープラーニングの計算とスケールに必要なアクセラレーションを可能にします。主な特徴は以下のとおりです:
AI専用コンピュート・エンジン:インテル Gaudi 3アクセラレーターは、高性能で高効率なGenAIコンピュート向けに設計されています。 各アクセラレーターは、64個のAIカスタム・プログラマブルTPCと8個のMMEで構成されるヘテロジニアス・コンピュート・エンジンを独自に備えています。各Intel Gaudi 3 MMEは、驚異的な64,000並列演算が可能で、高度な計算効率を実現し、ディープラーニング・アルゴリズムの基本である複雑な行列演算の処理に優れています。このユニークな設計により、AIの並列演算の速度と効率が加速され、FP8やBF16を含む複数のデータタイプをサポートしています。
LLMの容量要件に対応するメモリ・ブースト: 128ギガバイト(GB)のHBMe2メモリ容量、3.7テラバイト(TB)のメモリ帯域幅、および96メガバイト(MB)のオンボードスタティックランダムアクセスメモリ(SRAM)は、より少ないIntel Gaudi 3で大規模なGenAIデータセットを処理するための十分なメモリを提供します。エンタープライズGenAIのための効率的なシステムスケーリング:24個の200ギガビット(Gb)イーサネットポートがすべてのIntel Gaudi 3アクセラレータに統合されており、柔軟でオープンスタンダードなネットワーキングを提供します。これにより、大規模なコンピュート・クラスターをサポートするための効率的なスケーリングが可能になり、独自のネットワーキング・ファブリックによるベンダーロックインを排除します。Intel Gaudi 3アクセラレータは、GenAIモデルの拡張要件を満たすために、単一ノードから数千ノードまで効率的にスケールアップおよびスケールアウトできるように設計されています。
開発者の生産性を高めるオープンインダストリーソフトウェア: Intel GaudiソフトウェアはPyTorchフレームワークを統合し、最適化されたHugging Faceコミュニティベースのモデルを提供します。これにより、GenAI開発者は、使いやすさと生産性、ハードウェアの種類を超えたモデルの移植を容易にするために、高い抽象化レベルで操作することができます。
Gaudi 3 PCIe:Gaudi 3ペリフェラル・コンポーネント・インターコネクト・エクスプレス(PCIe)アドインカードが新たに製品ラインに加わりました。低消費電力で高効率を実現するこの新しいフォームファクターは、微調整、推論、RAG(retrieval-augmented generation)などのワークロードに最適です。600Wのフルハイト・フォームファクターを備え、メモリ容量は128GB、帯域幅は毎秒3.7TBです。

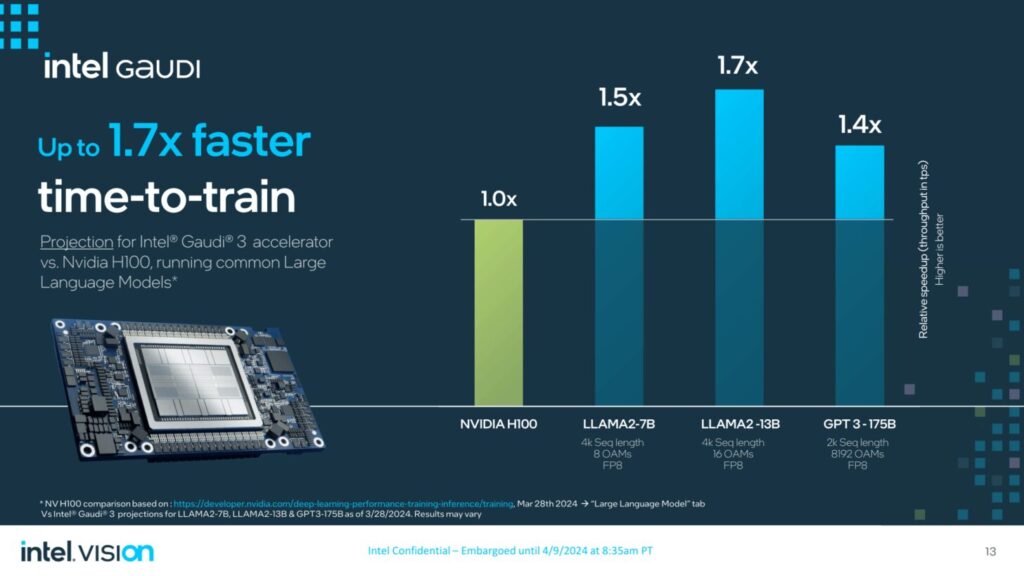
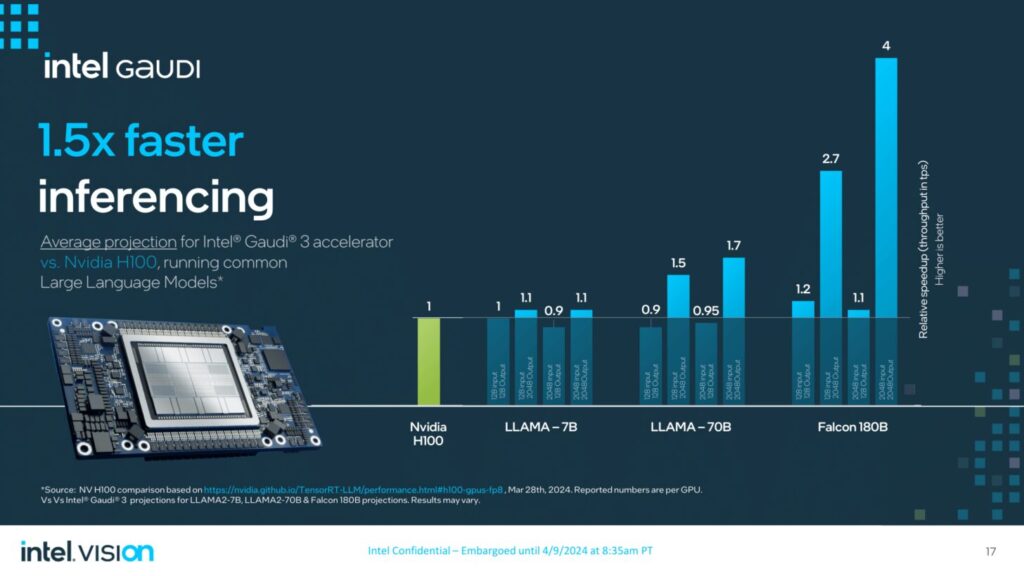
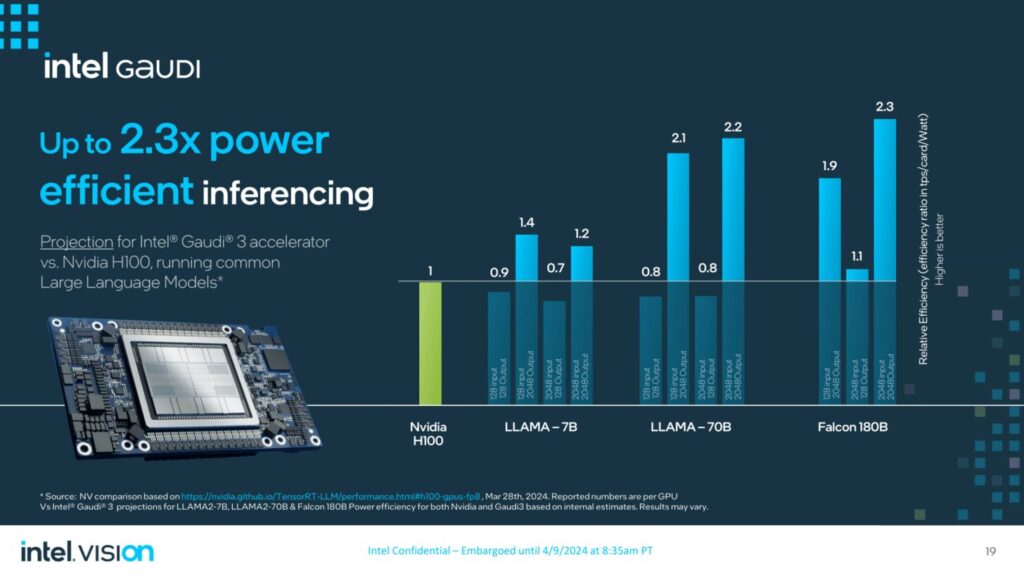
インテルGaudi 3アクセラレータは、主要なGenAIモデルのトレーニングおよび推論タスクにおいて、大幅な性能向上を実現します。
具体的には、Intel Gaudi 3アクセラレータは、NVIDIA H100と比較して、平均して次のような性能を発揮すると予測されています:
- Llama2 7Bおよび13Bパラメータ、GPT-3 175Bパラメータモデルにおいて、time-to-trainを50%高速化。
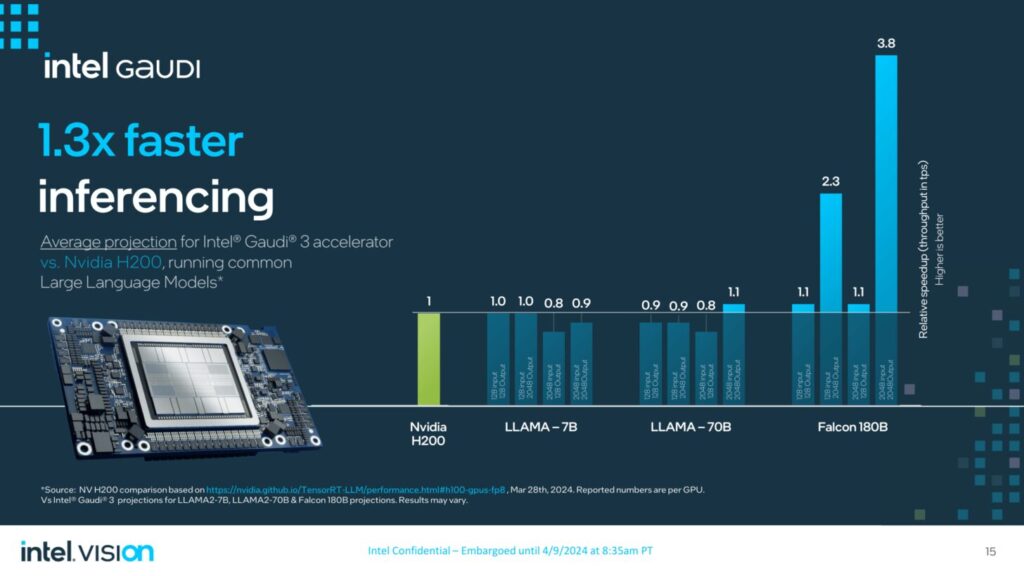
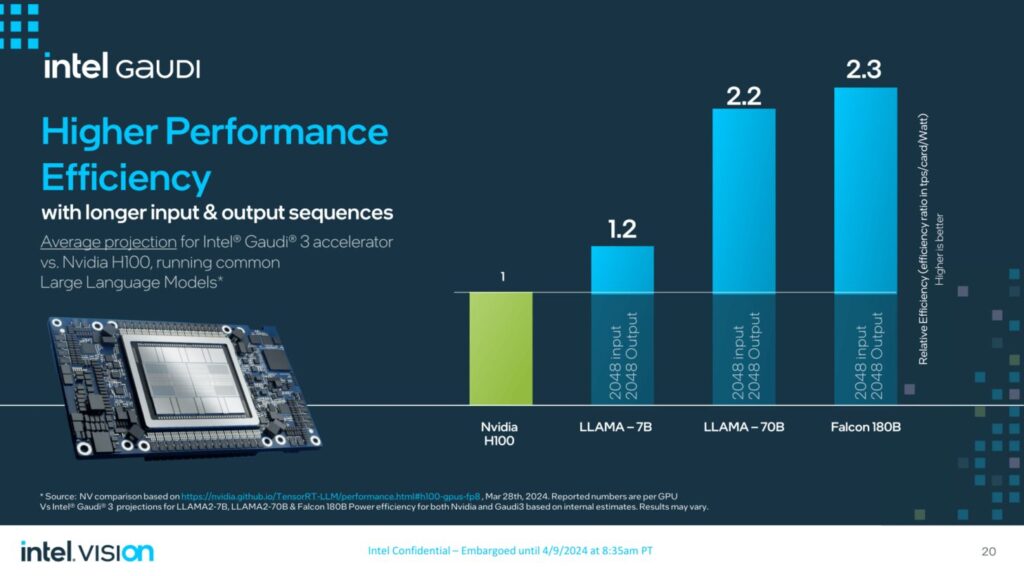
- Llama 7Bおよび70Bパラメータ、Falcon 180Bパラメータモデルにおいて、推論スループットが50%高速化し、推論の電力効率が40%向上。より長い入出力シーケンスにおける推論性能の優位性。
- NVIDIA H200に対して、Llama 7B、70Bパラメータ、およびFalcon 180Bパラメータモデルで30%高速な推論。



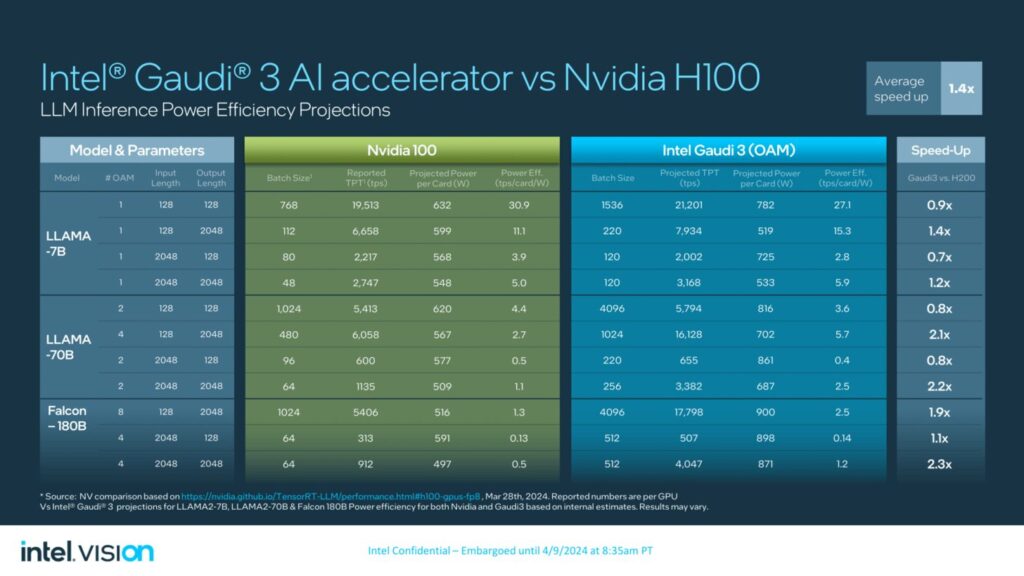
市場への導入と提供について: インテルGaudi 3アクセラレータは、ユニバーサル・ベースボードとオープン・アクセラレータ・モジュール(OAM)の業界標準構成で、2024年第2四半期に相手先商標製品メーカー(OEM)に提供される予定です。
Gaudi 3を市場に投入する注目すべきOEM企業には、Dell Technologies、HPE、Lenovo、Supermicroが含まれる。
Intel Gaudi 3アクセラレーターの一般販売は2024年第3四半期、Intel Gaudi 3 PCIeアドインカードは2024年最終四半期と予想されています。

インテルGaudi 3アクセラレーターは、トレーニングや推論用のいくつかのコスト効率の高いクラウドLLMインフラにも電力を供給し、NAVERを含む組織に価格性能の優位性と選択肢を提供する。
解説:
Intel Gaudi 3はAMD MI300の後に続けるか?
データセンター向けのAI/MLハードウェアアクセラレーターのIntel Gaudi 3が発売されるようです。
40%効率化と50%の性能向上とされています。
わたくしは残念ながらIntelのGPUは全く使ったことがありませんので使い勝手に関しては想像がつかないです。
CUDAの動作をそっくり再現するZLUDAと違ってIntelはOneAPIという方法でCUDAと似たような動作を実現しようとしています。
AMDはROCmを使ってCUDAと同じような動作を実現しています。
実際に使ってみると、完全に同じとはいいがたいところがありますが、ロンチされてからしばらくたっていることもあって現在では使い勝手も向上しています。
OneAPIはそのあたりはどうなのでしょうか。
ipexはCPU版のエクステンションという形をとっている都合上、推論の結果が若干異なることもあって、その点は完全にコンパイルする必要のあるROCmのほうが良いのかなと思います。
いずれにしても、開発力のあるIntelが複数のベンダーを組んで推進している規格ですから、我々(一般のホビーユーザー)が不通に使うようになる時期もそのうち来るのではないかと思います。
現在のところ、わたくしがアクセスできるようなレベルで存在感を発揮しているとはいいがたい状況です。
[st_af id="28818"]