※クリックで別Window・タブで拡大します。
私たちのフレンドリーなチップの巨人は、2桁のパフォーマンスの向上に悩まされていますが、Cerebras Systemsと呼ばれるスタートアップは前進し、現在利用可能な最高のチップであるNVIDIA V100よりも5600%の信じられないほどのトランジスタ数の増加を提供するプロトタイプを披露しました。
トランジスタ数は211億から2.1兆に増加し、このスタートアップは他の誰もできなかった重要な技術的課題を解決し、世界初のウェーハスケールプロセッサを実現しました。
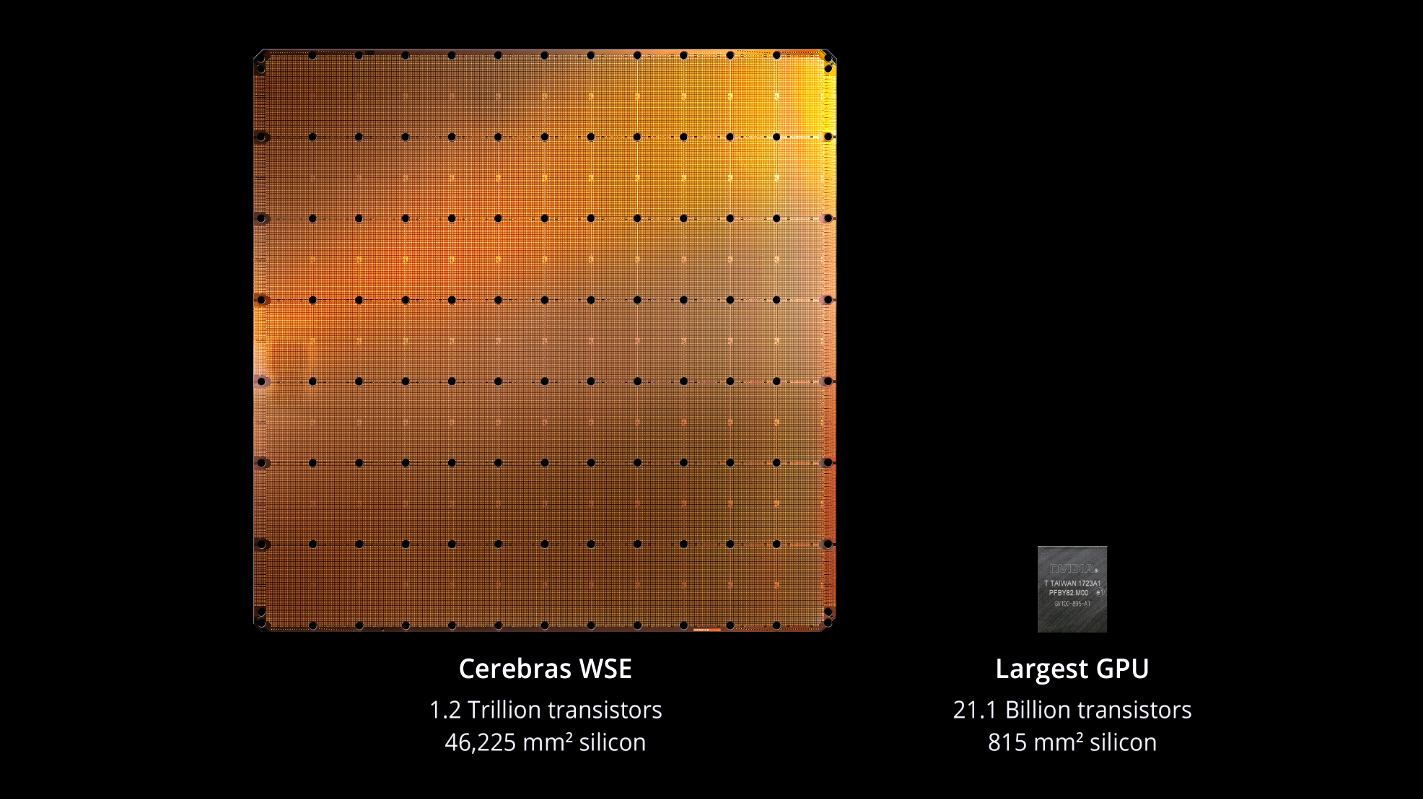
Cerebras Systemsのウェーハスケールエンジン(WSE):世界初の1兆トランジスタカウントチップ
Cerebras Wafer Scale Engineは、世界初のウェーハスケールプロセッサです。
他の誰もこれほど明白なことをしていない理由を疑問に思うかもしれません。その理由は、クロススクライブ回線通信の重要な技術的課題が他の誰によっても克服されなかったからです。
現在のリソグラフィ機器は、ウェーハ上の小さなプロセッサをエッチングするように設計されています。
ウェーハ全体でプロセッサ全体を作成することはできません。
これは、スクライブラインが何らかの方法で存在し、個々のブロックがこれらのラインを介して何らかの方法で通信できる必要があることを意味し、これはCerebrasが最初の1兆トランジスタカウントプロセッサの王位を主張できるように解決したものです。
Cerebras WSEは46,225mm²の面積を占有し、1.2兆個のトランジスタを収容しています。
すべてのコアはAIワークロード向けに最適化されており、チップは15 KWの電力を消費します。
すべての電力も冷却する必要があるため、この冷却システムは電力システムと同じくらい革新的である必要があります。
垂直冷却に関する彼らのコメントに基づいて、私は、この獣を飼いならすことができるのはおそらく、動きの速いフレオンを備えた水中冷却システムだけだと考えています。
また、電源システムは非常に堅牢である必要があります。

※クリックで別Window・タブで拡大します。
Cerebrasによると、通信はフープ(相互接続、DIMMなど)を介してジャンプするのではなく、スクライブラインを介して行われるため、チップは従来のシステムよりも約1000倍高速です。
WSEには、400,000個のスパース線形代数(SLA)コアが含まれています。 各コアは、柔軟でプログラム可能で、ほとんどのニューラルネットワークを支える計算用に最適化されています。
プログラマビリティにより、コアは常に変化する機械学習分野ですべてのアルゴリズムを実行できます。
WSEの400,000コアは、帯域幅100 Pb / sの2DメッシュのSwarm通信ファブリックを介して接続されています。
Swarmは、グラフィック処理ユニットをクラスター化するために使用される従来の技術のわずかな消費電力で、画期的な帯域幅と低遅延を提供する大規模なオンチップ通信ファブリックです。
完全に構成可能です。 ソフトウェアは、WSE上のすべてのコアを構成して、ユーザー指定のモデルのトレーニングに必要な正確な通信をサポートします。
Swarmは、各ニューラルネットワークに対して、一意で最適化された通信パスを提供します。
WSEには18 GBのオンチップメモリがあり、すべて単一のクロックサイクル内でアクセスでき、9 PB / sのメモリ帯域幅を提供します。
これは、主要な競合他社よりも3000倍の容量と10,000倍の帯域幅です。
より多くのコア、より多くのローカルメモリにより、より低いレイテンシでより少ないエネルギーで、高速で柔軟な計算が可能になります。
これにより、AIアプリケーションの大幅な高速化が可能になり、トレーニング時間が数か月からわずか数時間に短縮されます。
これは本当に革命的であり、約束を果たすことができ、すぐに顧客にこれを提供し始めることができれば、疑いの余地はありません。
Cerebras WSEは、16nmプロセスを使用してTSMC 300mmウェーハで製造されています。これは、これが最先端技術であり、NVIDIAなどの巨人の背後にある1つのノードであることを意味します。
もちろん、400,000を超えるコアを収容する84個の相互接続されたブロックがあるため、製造プロセスは重要ではありません。
Cerebras WSEの収量とビニングは非常に興味深いものになります。
たとえば、ウェーハ全体をダイとして使用している場合、設計が欠陥を吸収できる場合は100%の歩留まりを、不可能であれば0%を取得します。
明らかに、プロトタイプが作成されたため、設計は欠陥を吸収することができます。
実際、CEOは、設計では機能表面積の約1%から1.5%の欠陥を想定しており、マイクロアーキテクチャは使用可能なコアに合わせて単純に再構成すると述べています。
さらに、パフォーマンスの損失を最小限に抑えるために、チップ全体に冗長コアが配置されています。
現在、ビニングに関する情報はありませんが、これが世界で最もビニング可能なデザインであることは言うまでもありません。
また、現在、ウェーハスケールプロセッサを処理するためのツールが設計されていないことを考慮して、同社は独自の製造およびパッケージングサイエンスを設計しなければならなかったと言われています。
それだけでなく、ソフトウェアを書き換えて、1つのプロセッサで1兆個以上のトランジスタを処理する必要がありました。
Cerebras Systemsは明らかに、信じられないほどの可能性を秘めた企業であり、Hot Chipで発生したスプラッシュを見ると、これらのWafer Scale Engineからのテスト結果を見るのが待ちきれません。
解説:
Cerebras Wafer Scale Engineという常識外れの巨大なGPUがお目見えしました。
このGPUはnVidiaの Tasla V100の56倍のサイズを誇り、2.1兆トランジスタという今までになかったスケールのGPUになります。
Wafer Scale Engineの名の通り、1ウェハーに1GPUで、通常のチップで歩留まりになって反映される不良部分に関しては、チップ全体に冗長性を持たせて、無効化することによって解決しているようです。
まだプロトタイプですので、最終製品がいくらになるのかわかりませんが、まあ、個人で買えるようなものでないことだけは確かでしょう。
製造プロセスは1世代前の16nmを使うようです。
ウェハー中で不良部分というのは出てくると思いますので、基本的には一点物のGPUになるんじゃないでしょうか。
主に機械学習用途を見込んでいるようですが、可能なのかどうかもわかりりませんが、誰か購入してゲーム用として試しに使ってくれませんですかね(笑