
ほぼすべてのAmpere仕様をほとんど一人で流しているリーカー(@ kopite7kimi、Videocardz経由)によると、NVIDIAは数学者Ada Lovelaceに基づく次世代GPUアーキテクチャに取り組んでいます。
同時に、MCMベースのHopperアーキテクチャは、今のところどこにも見当たらず、Lovelaceアーキテクチャが代わりにその地位を占めるかもしれないので、延期されているようです。
NVIDIAの5nmベースの次世代Lovelaceアーキテクチャ、Hopper MCM GPUが遅延

多くの点で、Ada Lovelaceには世界初のコンピュータ愛好家と考えられています。
彼女は、チャールズ・バベッジによって提案された分析エンジンが純粋な計算を超えた応用があることに気付いた最初の人物であり、また、そのような機械によって運ばれることを意図した最初のアルゴリズムと考えられるものを発表しました(最初のコンピュータ・プログラマーになる)。
これは、アラン・チューリングが彼らの仕事を終え、第二次世界大戦中に汎用コンピュータを発明するほぼ半世紀前のことでした。
NVIDIAは、著名な物理学者、数学者、科学者、Ada Lovelaceに氏のアーキテクチャをベースにしていることで知られていますが、Ada Lovelaceに氏も同様です。Videocardzは、実際にNVIDIA自身のグッズストアで、Lovelaceアーキテクチャが同社の次世代GPUであることについてのこの噂を確認するように見える主要なヒントを見つけることに成功しました。
GTCの2018年キーノートで紹介されたヒーローたちを見ると、Ada Lovelaceだけでなく、NVIDIAの将来のアーキテクチャのコードネームがすべて含まれている可能性があることがわかります。
Jensen氏は、GTC'18のキーノートでこっそりと将来のロードマップ(コードネームに関しては)をすべて残していたのかもしれない。

現在、Lovelaceアーキテクチャが5nmプロセスをベースにしたものになるのではないかと思われる複数の噂が出ている。
NVIDIAはSamsungのファウンドリに移行したので、5nmがTSMCのプロセスを指すのか、Samsungのプロセスを指すのかは不明である。
しかし、韓国からの最近のレポートでは、NVIDIAからの6nmの注文も確認されていることに留意してください - つまり、Lovelaceの前にNVIDIAからの別の世代があるか、または6nmプロセスはリフレッシュラインナップのためのものだったということです。
5nm is right
— kopite7kimi (@kopite7kimi) December 21, 2020
Ampere関連のリークの大半を流しているリーカーのKopite氏は、Lovelaceが5nmプロセスをベースにすることも明言している。
さらに、HopperとNVIDIAのMCMベースのGPUは今のところ延期されているとも述べている。
真に性能の境界線を押し広げるにはMCM GPUが必要になるため、これはテックファンにとっては大きな痛手だ。モノリシック設計のままでは、歩留まりが大きな問題になりそうだ。
I'm afraid the Next-Gen GPU (Hopper) based on MCM was delayed. Is Jensen going to draw a new roadmap instead? It looks very probable.
— kopite7kimi (@kopite7kimi) December 10, 2020
この点を説明するために、私は勝手に次のような計算をしてみました:484mm²(例:Vega 64)を測定したダイは、22mm x 22mmのダイに相当します。
このモノリシックダイを4x11mm x 11mmに分割すると、同じ純表面積(484mm²)が得られ、歩留まりも向上します。
どのくらい?見てみましょう。概算では、300mmのウェハで114個のモノリシックダイ(22x22)または491個の小さなダイ(11x11)を製造することができます。
1つのモノリシック部品に等しい4つの小さいダイが必要なので、最終的には122個の484mm²のMCMダイが必要になります。これは7.6%の歩留まり向上になります。
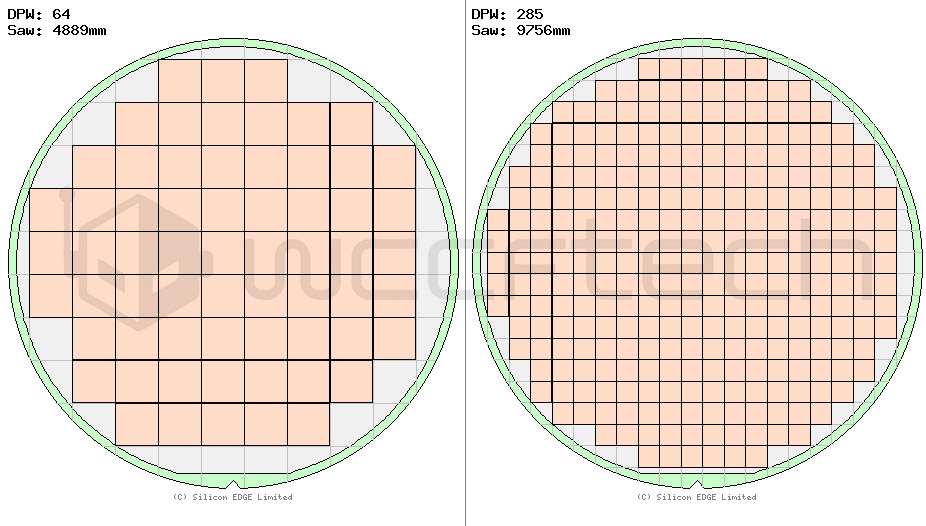
歩留まりの向上は、より大きなチップではさらに大きくなります。リソグラフィ技術の上限は(合理的な歩留まりで)約815mm²です。
1枚の300mmウェハで、これらのうち約64個(28.55x28.55)または285個の小さなダイ(14.27x14.27)を得ることができます。
これにより、合計71個のMCMベースのダイが得られ、歩留まりは約11%向上します。これは非常に大雑把な近似値であり、パッケージングの歩留まりや長方形のダイ、ウェーハの他の形状ベースの最適化など、いくつかの要因を考慮に入れていませんが、基本的な考え方は十分に保持されています。
逆に、廃棄物の削減による利益の増加も考慮に入れていません - 欠陥のある815mm²のモノリシックダイは、203mm²の単一ダイよりもはるかに廃棄物が多いのです! つまり、このアプローチには、不良品の影響を最小限に抑えるという付加的な利点があるということです。
いずれにしても、NVIDIAのLovelaceアーキテクチャについては、コードネームとプロセス以外にはあまり知られていません。
この投稿は、いくつかの未確認の発言が含まれているため、噂とされています - Kopite氏がまだ間違っているわけではないことを指摘しておきます。
解説:
噂:5nmの新アーキテクチャーがリークか?
Hopperの代わりにLovelaceと言う新アーキテクチャーが用意されているとリークしました。
HopperはMCMになると言われていますが、このLovelaceがどうなるのかは不明です。
5nmと言われていますが、Appleにほぼ独占されて供給量がひっ迫しているTSMCのFabで賄えるのかどうか、まず真っ先に疑問に感じるところです。
そのため、元記事ではnVidiaはSamsungに移行するのではないかとも噂されています。
私もちょっと驚いていますが、新GPUであるAmpereが発売されたばかりで、過去の事例を考えてもこれほど早く次のGPUアーキテクチャーが噂されることは近年ありませんでした。
一体なぜnVidiaはこれほど慌てているのか?
では、一体なぜnVidiaはこんなにも慌てているのか?(少なくともそのように見えるのか)ですが、やはりBig Naviの性能が予想以上だったからではないかと思います。
RX6800XTはほぼ完全にRTX3080を抑え、RTX3090に迫る性能があります。
RTX3090は価格が全く違います。
発売されたばかりですぐに値下げは出来ないため、nvidiaにとってはかなり厳しい状況だと思います。
今一つ、nVidiaのプライドを傷つけたのはスマートアクセスメモリでしょう。
nVidiaが新しい技術を取り入れ、AMDが後を追うというのが近年の流れでしたが、今回のBig NaviではAMDからもゲームによってはかなり性能が伸びるSAMが発表されました。
プラットフォームホルダーであるAMDの動向はnVidiaの心胆を寒からしめるのに十分だったのではないかと思います。
個人的にはRDNA3は5nmに移行するのではないかと思っていますので、Big Naviの1.5-2倍程度の性能になるのではないかと思っています。
単純に5nmにシュリンクしただけでも性能(クロック)は20%程度は上がるのではないかと思っています。
インフィニティキャッシュによって見かけ上のメモリ帯域幅を大幅に上げることが出来るようになった点から考えても、nVidiaが危機感を持ってもおかしくはないです。
現時点ではまだ名前が明らかになった程度ですが、ポストAmpere世代のGPU競争は激しさを増しそうな気配です。
[st_af id="7964"]