
IntelのXe3グラフィックスアーキテクチャが正式に発表され、Panther LakeのiGPUに搭載される予定です。さらに将来的にはXe3Pモデルも搭載される予定です。
Intel、Panther LakeのiGPU向け第3世代Xeアーキテクチャ、Xe3グラフィックスを発表:最大50%のパフォーマンス向上、Xe3Pへのアップグレードも後日提供開始
昨年、IntelはXe2アーキテクチャを発表しました。このアーキテクチャは、Lunar Lakeの「Core Ultra 200」CPUのiGPUと、Arc Bシリーズの「Battlemage」ディスクリートグラフィックスカードという2つのクライアント製品に統合されました。
Xe2は、Xe1アーキテクチャとArc Alchemist Aシリーズファミリーで得た知見を活かし、両プラットフォームで大きな成功を収めました。



※ 画像をクリックすると別Window・タブで拡大します。
同社はソフトウェア部門でも大きな進歩を遂げており、ゲームだけでなく、コンテンツ制作、レンダリング、AIワークロードにも最適なグラフィックスアーキテクチャ向けの優れたドライバーサポートを提供しています。
最近発売されたArc Proシリーズも、Battlemage GPUと同じドライバーブランチでサポートされています。

ここ数ヶ月で注目すべき点は、Intelがグラフィックス分野で堅実なアップデートを提供してきたことです。
アーキテクチャは向上し、ソフトウェアはそれをより適切に最適化し、活用する能力が向上しています。
そして、Panther Lakeの「Core Ultra 300」シリーズが間もなく登場し、Xe3というコードネームで呼ばれる、Xeアーキテクチャの全く新しい世代が登場します。
Xe3 iGPUはArc BシリーズiGPU、次世代Xe3Pも発表
Intel Xe3では、Xe2アーキテクチャをベースに、グラフィックスを大規模構成に拡張し、よりスループットに最適化された設計を提供しています。
注目すべき点はたくさんありますが、そのついでにXe3 iGPUがArc Bシリーズとしてブランド化されることもお伝えしておきます。
Arc Bシリーズの他のファミリーであるBattlemage dGPUはXe2アーキテクチャに基づいており、Panther Lake iGPUはXe3アーキテクチャに基づいていますが、Intelによると、Xe2とXe3はいくつかの点で類似しているため、統合型とディスクリート型全体で単一の統合製品スタックを持つことにしたとのことです。
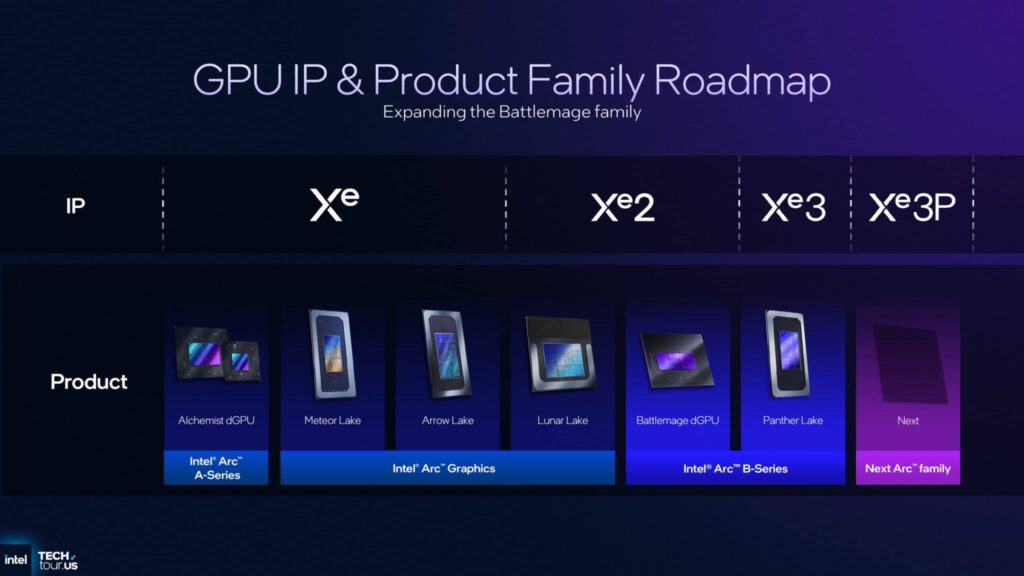
とはいえ、Intelはすでに新しいArcファミリーを計画しており、Xe3Pと呼ばれるアップデートされたXe3 GPUアーキテクチャを採用する予定です。
これは大きな前進と言えるでしょう。
詳細は発表されていませんが、IntelはXe4に直接移行するのではなく、将来の製品(統合型かディスクリート型かは問いません)に向けてXe3をさらに最適化していくようです。
情報筋によると、Xe3PはdGPUソリューションとして実装される可能性があるようですが、Nova Lake CPU向けのハイエンドiGPU構成としても採用される可能性もあるため、今後の動向に注目が集まります。
また、Xe3P GPUは、Battlemage dGPUやPanther Lake iGPUのようにArc Bシリーズには搭載されず、次期Arcファミリー、つまりArc Cシリーズに搭載されるのでしょうか?それでは、Xe3の詳細を見ていきましょう。
Xe3 - iGPUのスケールアップによるパフォーマンスとパワーの向上
さて、Xe3についてですが、Intelが新しいアーキテクチャで最初に行ったのは、レンダースライスのスケールアップです。
Xe2は、レンダースライスあたり4つのXeコアと4つのレイトレーシングユニットで構成されていました。

Xe3では、レンダースライスあたり最大6基のXeコアと6基のレイトレーシングユニットを搭載します。
これは、レンダースライスあたりのコア数とレイトレーシングユニット数が50%増加したことを意味します。

これにより、IntelはPanther Lake SoC内で多様なGPUタイル構成を活用できるようになります。
これについては、こちらの詳細な分析で詳しく説明しています。8Cおよび16Cダイには4 Xe GPU構成があり、最上位の16Cダイには12 Xe GPU構成があります。
Arrow LakeとLunar Lakeはどちらも、それぞれXe1およびXe2アーキテクチャに基づいて最大8個のXeコアを搭載しているため、興味深い比較になるでしょう。
Panther Lakeは8Cおよび16C SKUで4個のXeコアを使用しているため、これは現在のラインナップの半分の量ですが、グラフィックスアーキテクチャの改善により競争力は維持されるはずです。

それでは、2つの構成について見ていきましょう。1つ目は4 Xeコアダイです。これは2種類あり、8Cは「Intel 3」プロセステクノロジーで製造され、16Cは「TSMC N3E」プロセステクノロジーで製造されています。構成は以下の通りです。
- 4 Xeコア(Xe3アーキテクチャ)
- 1 レンダースライス
- 32 XMXエンジン
- 4 MB L2キャッシュ
- 1 ジオメトリパイプライン
- 4 サンプラー
- 4 レイトレーシングユニット
- 2 ピクセルバックエンド

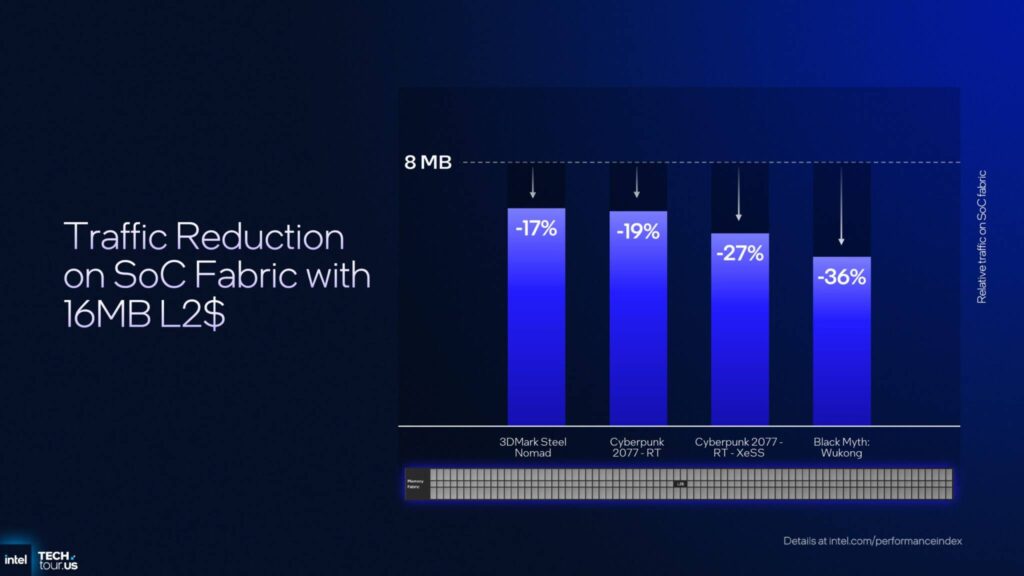
4MBのL2キャッシュを搭載した4Xe iGPU構成は、8MBのL2キャッシュを搭載したLunar LakeのXe2 iGPUの半分の容量です。
しかし、最上位の12Xe iGPU構成では、L2キャッシュが2倍になります。
キャッシュの2倍化はSoCファブリック上のトラフィック削減に役立ち、ゲーム中のトラフィックを最大36%、平均で25%削減できます。
ここで、Xe3 アーキテクチャ内で実装されたアーキテクチャの変更について説明します。

第 3 世代 Xe コアには、8 つの 512 ビット ベクター エンジン (XVE)、8 つの 2048 ビット XMX エンジン、および 33% 以上の共有 L1/SLM キャッシュが搭載されています。
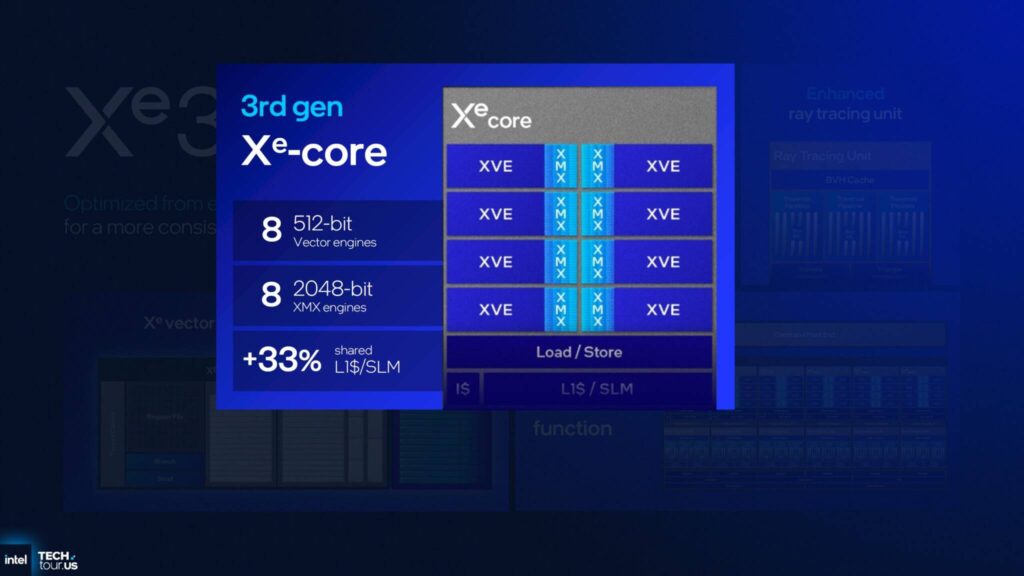
Xeベクトルエンジンは、Xe3アーキテクチャにおいて、最大25%のスレッド数増加、可変レジスタ割り当て、FP8逆量子化サポートにより、利用率を向上しました。
SIMD16ネイティブALU、3ウェイ同時発行、拡張演算ブロックとFP64ブロック、そしてXeマトリックス拡張で構成されています。

Xe3 XMXエンジンはAIアクセラレーションを担っています。最大96基のXMXエンジンを搭載した12Xe iGPUは、最大120TOPSの演算性能を発揮します。
この計算では、4Xe iGPUは最大40TOPSの演算性能を発揮します。
Xe2アーキテクチャに基づく8Xe iGPUは最大67TOPSの演算性能を発揮しました。
同じ計算を用いると、8Xeコアを搭載したXe3 iGPUは67TOPSのAI演算性能を発揮でき、これは25%の向上となります。

Xeコアあたりのオペレーション数/クロックは以下の通りです。
- XMX TF32: 1024オペレーション/クロック
- XMX FP16: 2048オペレーション/クロック
- XMX BF16: 2048オペレーション/クロック
- XMX INT8: 4096オペレーション/クロック
- XMX INT4: 8192オペレーション/クロック
- XMX INT2: 8192オペレーション/クロック
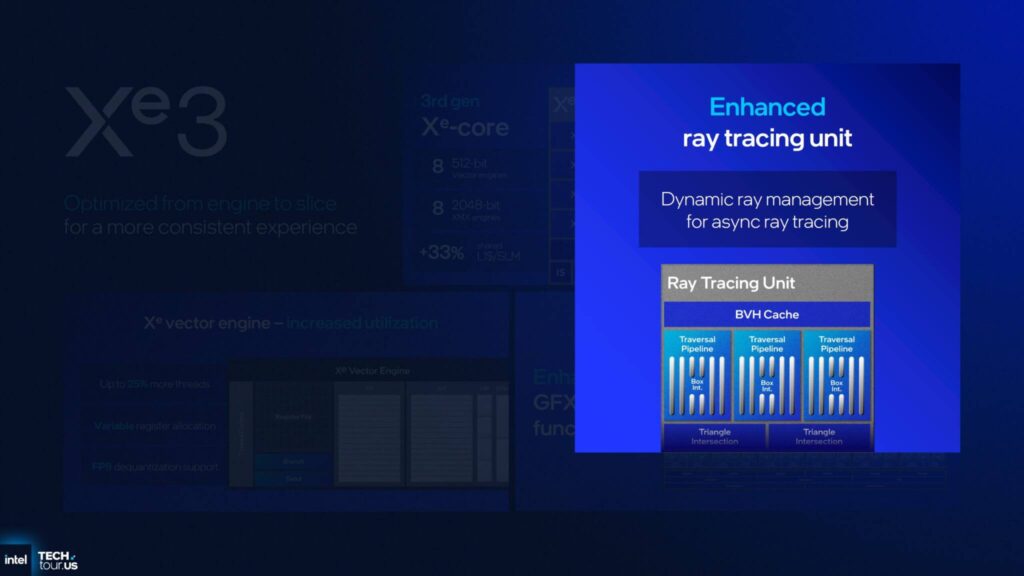
Intelは、非同期レイトレーシングのための動的なレイ管理機能を備えた、新たに強化されたレイトレーシングユニットも採用しています。
RTユニットには、複数のトラバーサルパイプライン、2つの三角形交差ユニット、そしてBVHキャッシュが含まれています。
これらの改善は、レイがパイプラインを移動する方法に起因しています。
これは、新しいレイのディスパッチ速度を低下させることで、スレッドソーティングユニットを通過する際にパイプライン内でのレイの遅延を防ぐことで実現されています。

もう一つの大きな改良点は、新しいURBマネージャーです。これにより、全体を肉付けするのではなく、部分的な更新が可能になります。
URBは、GPU内で結果が渡される構造です。
新しいアーキテクチャは、最大2倍の異方性フィルタリングと最大2倍のステンシルテストレートも備えています。
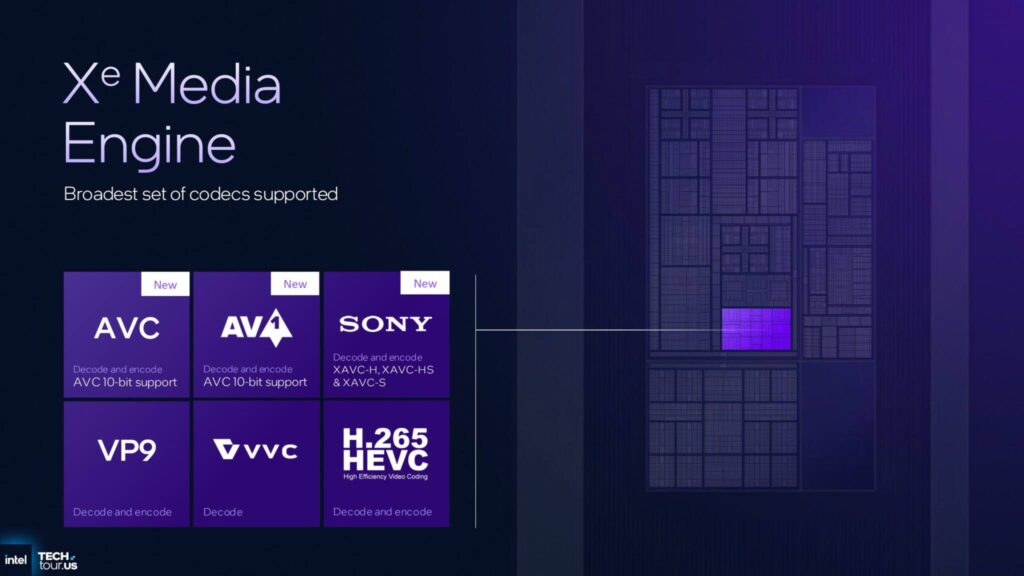
最後に、メディア面では、IntelはAV1エンコード/デコード、VVCデコード、そしてeDP 1.5テクノロジのサポートを備えています。
これらすべてが組み合わさって、Panther Lake向けのXe3を実現しています。
新たに追加された機能としては、AVC 10ビットサポート、Sony XAVC-H、XAVC-HS、XAVC-Sサポートなどがあります。
IntelはXe3でGPUパフォーマンスのスケールアップと向上を継続
Intelは、Xe3 GPUの初期パフォーマンス指標(基本的にはマイクロベンチマーク)もいくつか公開しています。
これらの指標は、GPUマイクロアーキテクチャの個々のセグメントを評価し、前年比でどれだけのパフォーマンス向上が見られるかを示すものです。
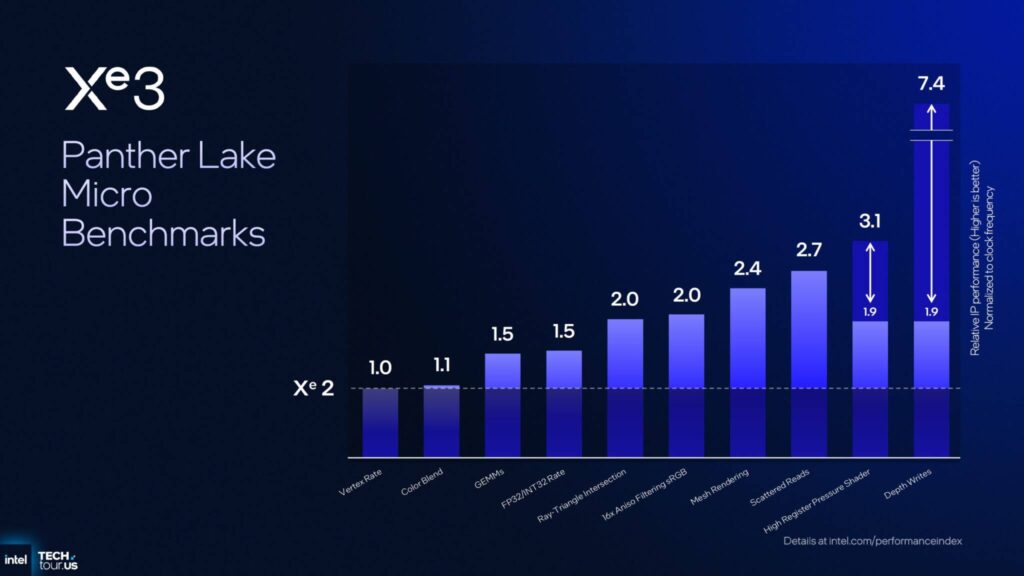
まず、ブレンドとバックエンドのパフォーマンス指標ですが、Xe3ではこれらに割り当てられるリソースが変更されていないため、ほとんど変化がありません。
GEMMのFP16指標は50%の改善が見られ、これはGPUの規模に比例しています。
Xe3はXe2よりも50%大きいため、これらのマイクロベンチマークはアーキテクチャの能力を最大限に活用できるため、この改善がもたらされています。
次に、異方性レート、メッシュレンダリングレート、分散読み取り、R/T交差などのマイクロアーキテクチャの強化が挙げられますが、これらは2倍から2.7倍の改善が見られます。
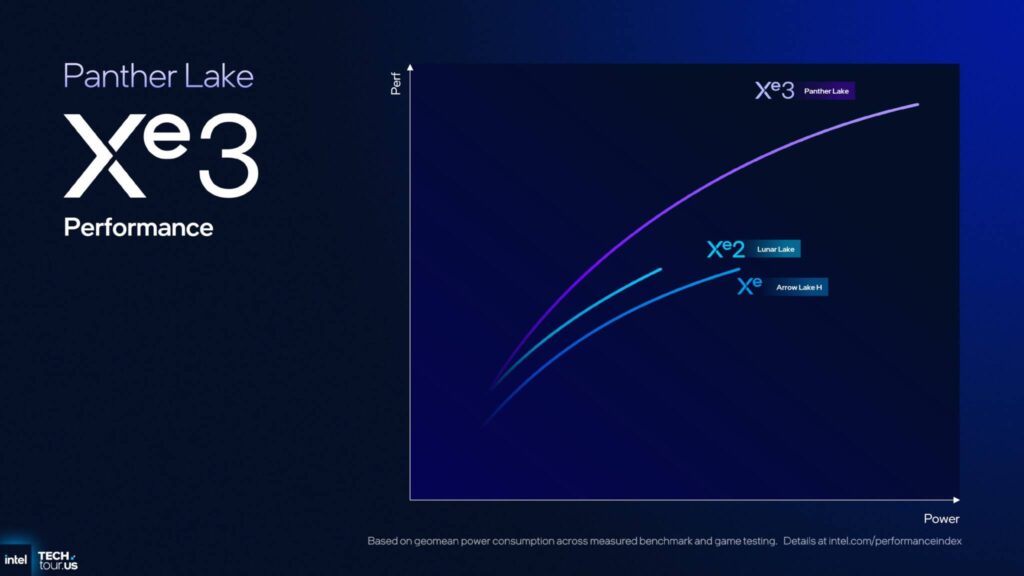
Intel はまた、深度テストやレジスタを多用するアプリケーションなど、Xe3 で行われたいくつかの大きな改善点を示しており、これらは前世代と比較して 7 倍以上の向上が見込まれます。
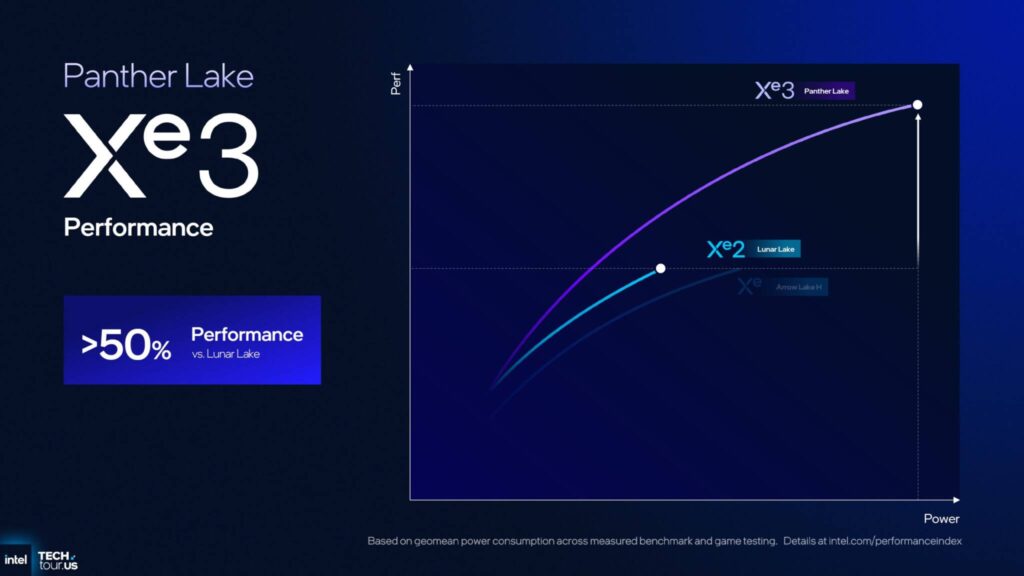
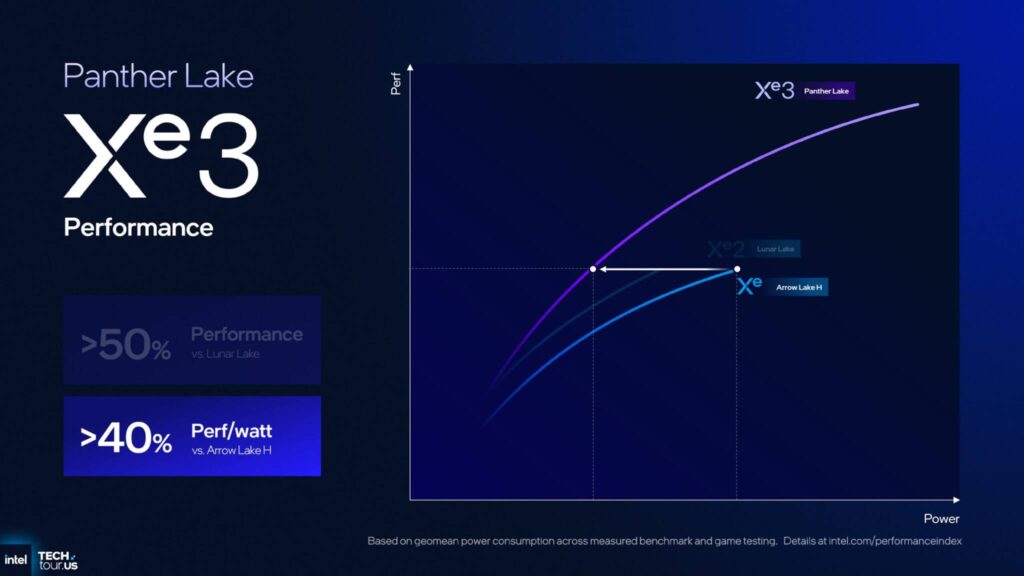
次に、Panther Lake 上の Xe3、Lunar Lake 上の Xe2、Arrow Lake-H 上の Xe+ の実際のパフォーマンス指標を見てみましょう。
Xe3 は、ピーク電力で Lunar Lake と比較して 50% 以上のパフォーマンスを提供し、Arrow Lake-H と比較してワットあたりのパフォーマンスが 40% 以上向上しています。
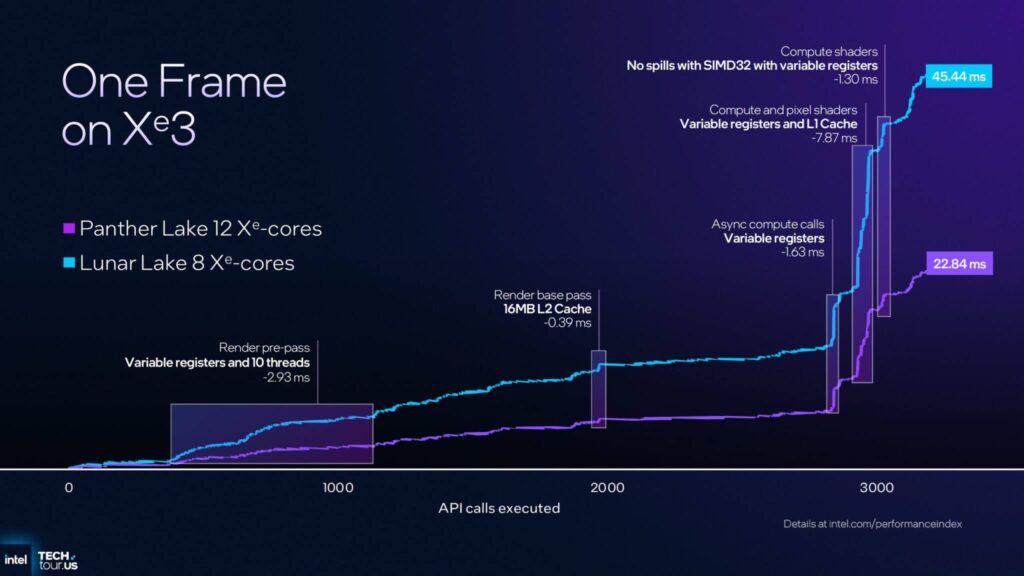
以下は、Xe3 と Xe2 でレンダリングされたフレームの比較です。
さらに、IntelはWindows Graphics Software Stackにソフトウェアの最適化を追加しています。
まず、IGCを通じて提供されるコンパイラーのアップデートに加え、重要なアップデートとして、変数レジスター割り当ての改良も行いました。
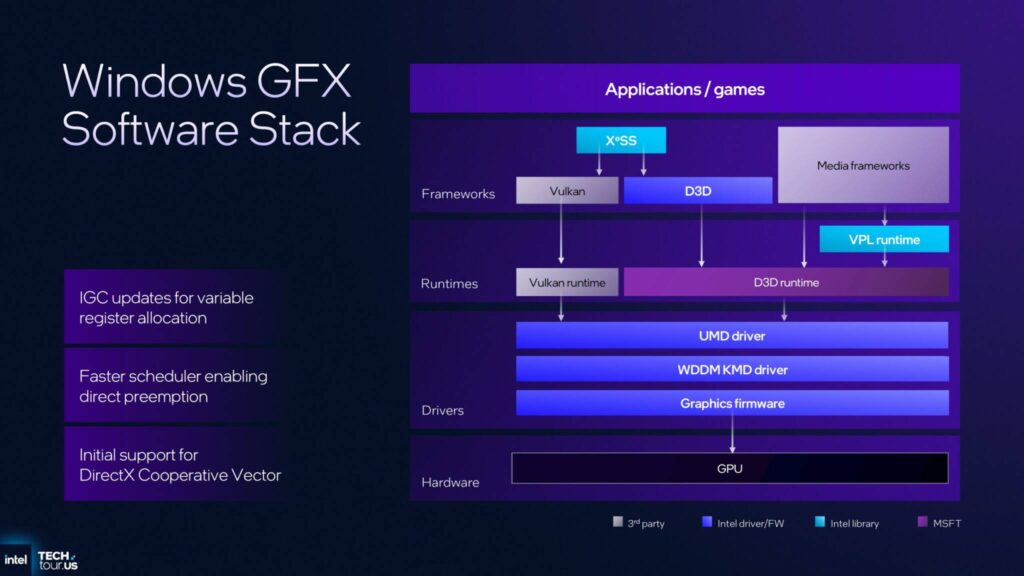
さらに、ダイレクトプリエンプションによる高速スケジューリングにより、フラッシュなしでコンテキスト間の切り替えが可能になり、DirectX Cooperative Vectorsもサポートされています。
Intelは、Cooperative Vectorsを活用した「Neural Radiance Field」のデモも披露しました。

Intel Xe3 iGPUは、既存のXe2アーキテクチャからの確実なアップグレードと言えるでしょう。
Xe2アーキテクチャは現在、メインストリームノートPC向けとしては最速のRDNA 3.5 iGPU(Radeon 890Mや880Mなど)と同等の性能を備えています。
より大規模なRDNA 3.5を実装したハイエンドのStrix Haloと同等の性能レベルに必ずしも達するわけではありませんが、最近のIntelとNVIDIAのカスタムSoCパートナーシップによって、このセグメントをカバーできる可能性が高まっています。
解説:
Xe3の情報が出てきました。
PantherLakeがOEMから酷評されているというリークが以前ありましたが、Xe3は「ドライバの出来が悪い」というものでした。
ドライバの出来に関しては発売までに改善される可能性は高い(何なら発売後でも改善される可能性はある)ので、一定期待はできるのではないかと思います。
また、Xe3はXe3無印とXe3Pとに分かれ、Xe3はiGPUとしてまたARC Bシリーズに含まれるとされています。
Xe3Pに関してはARC Cシリーズに含まれるのかどうかについて明言されていません。
この話を聞くとIntelのGPU事業に関して何かあまり前向きではない印象を受けます。
GPU事業を積極展開するならば、Xe3はBattlemageとは完全に切り離し、Celestialとして扱うべきだと思うのですが・・・・
元記事の話を見ているとXe3ではなく、Xe2.5のような印象を受けるのですが・・・・
元記事を見ると、Xe3はXe2との様々な性能向上をアピールしています。
しかし、現時点でのリークを見るとあまり芳しい噂は聞こえてこず、実際にはどうなるのかちょっと疑問を感じるところです。
Xe3は8CがIntel3、16CがTSMCN3Eを使うようです。
こちらは両方ともすでに採用実績のあるプロセスですから、Intel18Aのように製品がまだ出てないわけではありませんので動作クロックに関してはある程度の実績は担保されていると考えてよいと思います。
NVIDIAとの提携によって俄然、先行きが不透明になってきたintelのGPU事業です。
Druidくらいまではすでにある程度まで手かけていてもおかしくないと思います。
しかし、それ以降、NVIDIAとの提携によって小規模RTXが搭載されるとなれば、Intelは未来の可能性を失うことになりかねません。
より大規模なRDNA 3.5を実装したハイエンドのStrix Haloと同等の性能レベルに必ずしも達するわけではありませんが、最近のIntelとNVIDIAのカスタムSoCパートナーシップによって、このセグメントをカバーできる可能性が高まっています。
という表現がありますが、大規模なGPUといえばdGPUもそうなので、NVIDIAとの提携によって、大規模なGPU製品の設計を取りやめ以前のようなiGPUのみに戻ってしまうのではないか?という懸念を拭えません。
もっとはっきり言えばintelの将来のx86CPUに搭載されるGPUの設計はこれからであるならば、そこにNVIDIAのGPUが割り込んでも何ら不思議はないのかなと思います。
理由はNVIDIAの投資は実質的なIntel救済策に過ぎないと思うからです。
また、ユーザーの側からみてもiGPUがARCである必然性というのはありません。
Geforceは圧倒的なブランドであり、AIアクセラレーターで市場を席巻しているため先進的なイメージもあります。
iGPUにRTXが滑り込めば今まで手を出せなかったiGPUの市場を席捲できるわけで、デファクトスタンダードを得られるメリットは多いように感じます。
また、規模の大きいXe3 16Cは結局IntelファウンドリではなくTSMC N3Eというのも一抹の不安を覚えるところです。
これらの懸念もPantherLakeが発売されiGPUがどのような性能を発揮するのかが判明すればある程度はっきりしてくるのではないかと思います。