
インテルは、第5世代EPYC Turin CPUのデータセンターAI性能に関するAMDの主張を追認し、第5世代Xeonの方が適切な最適化により高速であると述べた。
AMDはZen 5コアを搭載した第5世代EPYC Turin CPUがAIベンチマークで第5世代Xeonチップを上回ることを示したが、Intelは適切な最適化が使用されれば第5世代がEPYCに対してリードすると述べている。
[アップデート - 6/18/24] - AMDはインテルのベンチマークに関するアップデートを提供し、Turinとインテルの第5世代Xeonチップを比較するテストにおいて、どのようなハードウェアとソフトウェアスタックが使用されたかに関する関連データが巻末の注に記載されていることを共有した。
また、「Intel Xeon」プラットフォームは、その時点で公開されている最新のソフトウェアを使用している一方、インテル自身は6月7日にリリースされたソフトウェア最適化ライブラリに基づく数値を公表していたとしている。以下はAMDからの引用である:
COMPUTEXでAMDは、第5世代インテルXeonプロセッサーと比較したAIワークロードにおける「Turin」のリーダーとしてのパフォーマンスを、AMDと競合他社の両方について、その時点で入手可能な最新の公開ソフトウェアを使用して強調しました。インテルがブログで取り上げた「Emerald Rapids」のデータは、当社のComputexイベント後の6月7日に公開されたソフトウェア・ライブラリを使用しています。 また、新しいソフトウェア・スタックはIntelプラットフォームのみに使用され、パフォーマンスの最適化はAMDプラットフォームには適用されなかったことにも注意が必要です。第4世代EPYC CPUは引き続きパフォーマンス・リーダーであり、「Turin」が今年後半に発売される際にも、幅広いワークロードでリーダーとしてのパフォーマンスを発揮すると期待している。
WccftechへのAMD広報

Computex 2024において、AMDは最新のZen 5コア・アーキテクチャを採用した第5世代EPYC CPUファミリー(コードネーム:Turin)を正式に発表した。
同社は、コードネームEmerald Rapidsと呼ばれるインテル第5世代Xeonファミリーに対して、特にAIスループット・ワークロードで大きな数字を打ち出したが、インテルは現在、これらのベンチマークはXeonファミリーに対する適切な最適化なしで実施されたものであり、それらを実装すれば、第5世代XeonであってもAI性能で第5世代EPYC Turinを容易に上回るはずであることを明らかにしている。
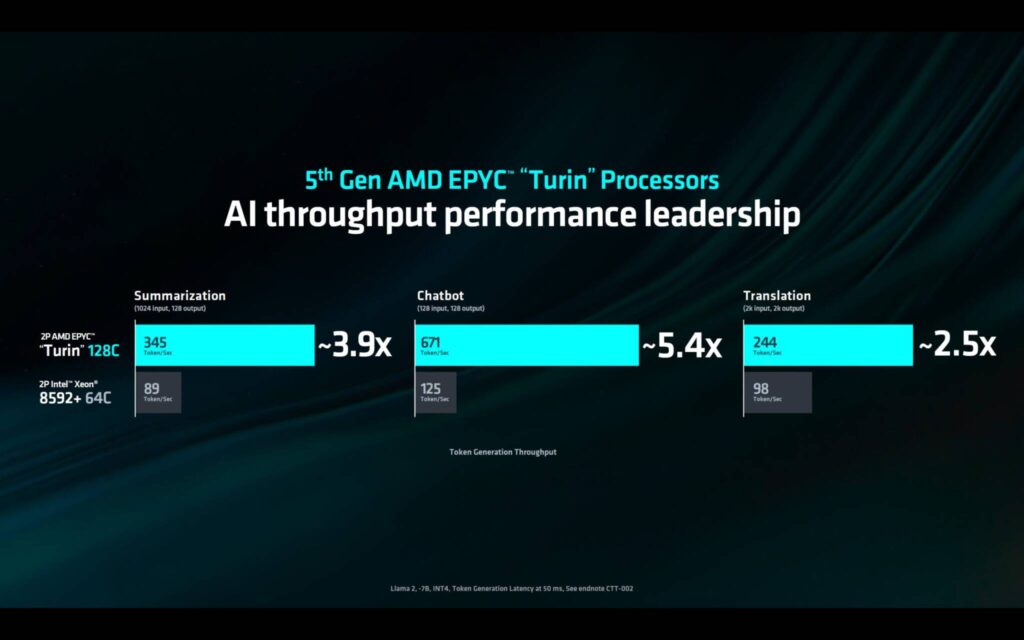
インテルが特に強調したベンチマークはLlama2-7B Chatbotで、INT4の推論スループットをベースにしており、50msのレイテンシーで実施された。
AMDは、各128コアの第5世代EPYC CPUが2S(デュアルソケット)構成で最大671トークン/秒の性能を発揮する一方、同じデュアルソケット構成で動作する各64コアのインテルの第5世代Xeon Platinum 8592+チップの出力はわずか125トークン/秒にとどまることを示した。
これは、AMD EPYC Turin CPUの5.4倍の大幅な向上である。
インテルは、ベンチマークは第5世代Xeon SKU用の適切なソフトウェア・スイートなしで実施されたとしており、AMDは脚注にインテルの構成に関する詳細を記載していない。
ブルー・チームは現在、同じAIワークロードでパフォーマンス・ベンチマークを実施しており、結果は根本的に異なるようだ。
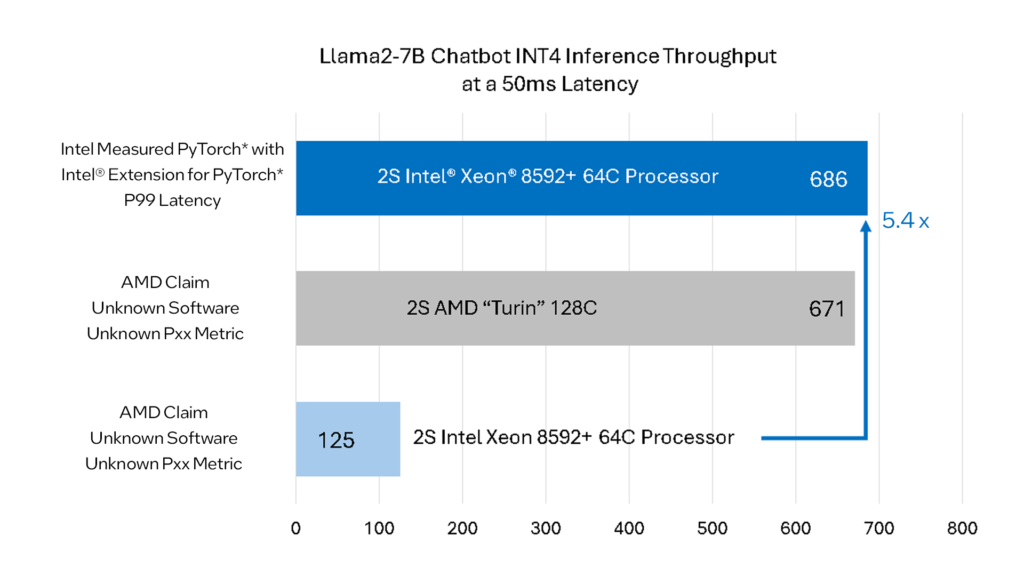
Intel Extension for PyTorch (P99 Latency)を使用することで、第5世代Emerald Rapids Xeon CPUは、AMDが展示したものよりも5.4倍優れたパフォーマンスを出力することができます。
686トークン/秒の出力は、AMDの第5世代EPYC Zen 5 CPUの性能を上回る。
これは、Llama2に対するインテルのソフトウェア最適化だけでなく、第5世代Emerald Rapidsファミリーに追加されたAIハードウェア・アクセラレータのおかげでもある。
インテルはこれだけにとどまらず、他の2つのワークロード、TranslationとSummarizationでは、AMDがComputex 2024のプレゼンテーションで使用した結果と比較して、1.2倍から2.3倍の性能向上が見られたとしている。
さらに重要な点は、これらのベンチマークはメモリに大きく依存しており、次世代EPYC Turinファミリーは12チャネルのDDR5インターフェイスを搭載することだ。
Intelの現行世代Xeon「Emerald Rapids」CPUのピークが8 DDR5メモリ・チャネルであるのに対し、次世代Granite Rapids「Xeon 6700P/6900P」CPUは、同じ「最大12チャネル」メモリ・インターフェースを搭載するだけでなく、2025年初頭に登場するXeon 6900Eファミリーと同じ128コア数のPコアと最大288のEコアを搭載する。
Granite Rapids Xeon 6700P CPUは、2024年第3四半期に最大86個のPコアを搭載して発売される。
現在AIビジネスに携わっているすべての主要企業は、性能の主張だけでなく、他企業が披露していることにも非常に真剣であるように見える。
NVIDIAとAMDは数カ月前、レッドチームがHopperのラインナップに対してMI300Xの数値を発表した際にも同様の戦いを繰り広げ、それ以降は一進一退の攻防が続いた。
同様に、AI PCの面でも、AMD、Intel、Qualcomm、NVIDIAの各社は、AI TOPが話題となる非常に激しい戦いを繰り広げている。
ハイテク業界全体でAIに対する需要が高まっているため、これらのハイテク企業はいずれも、自社製品を使用してくれる顧客を増やし、高性能なハードウェアに対する増え続けるニーズを満たすために多くのユニットを出荷しようとしている。
解説:
AI性能をめぐるXeonとEPYCの仁義なき戦い
ComputexでEPYC TUlinがXeonより高性能だとPRすれば、今度はIntelが最適化した環境で使えばXeonのほうが優れていると反論したようですね。
CPUでAI/ML性能を語るのはあまり意味がないように感じます。
このあたり、CPU込みのシステムとGPU単体をXeonなどのCPUに組み合わせたものの出荷の割合がわからないと何とも言えないですね。
データとしてそういったものは見たことがないので判断はできないです。
しかし、現在ではAI/ML性能は時代の花形ですから、少しでもPRして競合退社より優っていることをアピールするのはマーケティング的には重要なことなのかもしれません。
実際のところ、AMDもIntelもAI/ML関連の売り上げではNVIDIAには遠く及んでいませんから、何とか存在感を示せるところまでは売り上げを伸ばしたいのでしょうね。
一般向けのAI PCも販売が開始され、どのくらい市場に存在感を示せるのかが焦点になっていますが、サーバー向けCPUにもAI/ML機能が内臓され始めているということなのでしょう。
システム一括で販売するのが一般的なサーバーでどんな風に使われるのかは謎ですが・・・。