台湾の大手技術誌が本日、NVIDIAのニュースをスクープしました:同社が次世代Hopper GPUに使用するために、TSMCから5nmの容量を事前予約したことを確認したとのことです。
すでに取り上げたレポートによると、AMDの7nmへの積極的なアプローチはNVIDIAを驚かせ、その問題を是正するために、Hopper GPU用にTSMCの5nmをすでに予約しているとのことです。
TSMCの注文は確定しているが、NIVDIAがSamsungに5nmプロセスを求めているという噂も聞いたことがあるので、もしかしたら注文を分割しているのかもしれない。
NVIDIAは2021年にHopper GPU用にTSMCの5nm容量を予約していた
現在のロードマップでは、NVIDIAは7nmプロセスに1世代だけを費やしていることになるので、これは大きなニュースです(Hopperが遅れてAmper-refreshアーキテクチャが投入されない限り、その可能性は十分にあると認めざるを得ません)。
すでに取材したレポートによると、AMDはNVIDIAの7nm化に驚きを隠せず、同社は将来の成長を守るために非常に積極的になっている。
TSMCの主要な5nmプロセスを倍増させることは、この戦略の一環である。
Digitimesのレポートの関連部分、@chiakohua経由(許可を得て転載)。
Hopperアーキテクチャをベースにした次世代GPUについては、Nvidiaはすでに2021年にTSMCの5nm生産能力を予約しており、サムスンと少量の注文についても協議中である...
... AMDがこれ以上大きくなるのを防ぐために、NvidiaはTSMCの7nmと5nmのEUVノードを採用することで、AMDに追いつき、さらには飛躍的にAMDを追い越すことを決めた。(DigiTimes)
Hopperは今はただの名前であり、NVIDIAは将来的には何でもHopperと呼ぶことにすることができることを覚えておいてください。
ここで、NVIDIAは以前にシングルノードで少なくとも数年を費やしてきたが、AMDが積極的になってきたことで、同社は実際には多くの選択肢を持っていないかもしれないことを意味している。
もしAMDが再び5nmに移行することを決定した場合、NVIDIAは7nmプロセスにとどまることはできない。
そうすれば、同社のブランド価値が低下し、GPU技術のリーダーとしての地位を確立することが難しくなるだろう。
解決策は、AMDができないように、5nmの容量を事前に予約しておくことで、問題にお金を投入することです。
これは、NVIDIAがはるかに大きな現金を手にしていること、TSMCが金を拒否しないことを考えると、戦略的なものである。
もし、あなたが事実の世界に留まりたいと思っていて、経験から割り出した憶測があなたの趣味ではないのであれば、今すぐ読むのを止めてください。
Recap:NVIDIAのHopper GPUアーキテクチャとMCM哲学を探る
警告:NVIDIAのHopperアーキテクチャにおけるMCMの使用は確認されていない。割り引いて考えることを忘れないでください!
NVIDIAのアーキテクチャは、常にコンピュータの先駆者をベースにしており、これも例外ではないようです。
NvidiaのHopperアーキテクチャは、コンピュータ科学の先駆者の一人であり、ハーバードマーク1の最初のプログラマーの一人であり、最初のリンカーの発明者でもあるグレース・ホッパーに基づいている。
彼女はまた、機械に依存しないプログラミング言語のアイデアを広め、今日でも使用されている初期の高レベルプログラミング言語であるCOBOLの開発につながりました。
彼女は海軍に入隊し、第二次世界大戦中のアメリカの戦争活動に貢献しました。
現在、ほとんどのEUVスキャナのレチクルサイズに制限されていることを考えると、MCMベースの設計は、GPUの進化の次のステップであることは間違いありません。
アーキテクチャの改善とMCM設計は、次の論理的なフロンティアであり、AMDはすでにCPUフロントでそれを実行しているので、GPUが彼らの壮大な計画の次のステップになることは理にかなっています - これは、NVIDIAがそれをすべてから先取りして、彼らを打ち負かしたいと思う理由を説明することができます。
リークは有名なTwitterアカウントから発生し、その後ツイートは削除されましたが、Twitteratiがそれをキャッチして投稿しました(3DCenter.orgで公開)。
AMDはすでに、MCMベースの製品を作ることで例外的に優れていることを証明している。
ThreadripperとRyzenシリーズは、HEDT市場に絶対的な破壊をもたらしました。
通常は6コアで非常に高価だったものを、MCMパッケージを使用して16コアの手頃な価格のコンボにしたのです。
サーバーとXeonsのパワーは、最終的に平均的な消費者の手に渡りました。
NVIDIAがMCMの哲学を使ってスキャナのレチクルサイズを打ち負かし、正味表面積1000mm²を超える本当に巨大なGPUを構築することができることは、すでにご存知だと思いますが、他にも利点はあるのでしょうか?

※ クリックすると別Window・タブで開きます
理論的に言えば、シリアルデバイスであるCPUよりもパラレルデバイスであるGPUの方が、あらゆる面で優れた動作をするはずです。
それだけでなく、モノリシックダイの代わりにMCMベースのアプローチに移行するだけで、歩留まりが大幅に向上します。
単一の巨大なダイでは、歩留まりが悪く、生産にコストがかかり、通常は無駄が多くなります。
同じダイサイズのチップを合計した複数のチップを使用すれば、すぐに歩留まりを向上させることができます。これは、NVIDIA Hopper GPUを支持する大きな論拠です。
画像出典:wccftech
シリコンエッジツールを使って大まかな近似をしてみたところ、瞬時に歩留まりが向上したことに驚きはありませんでした。
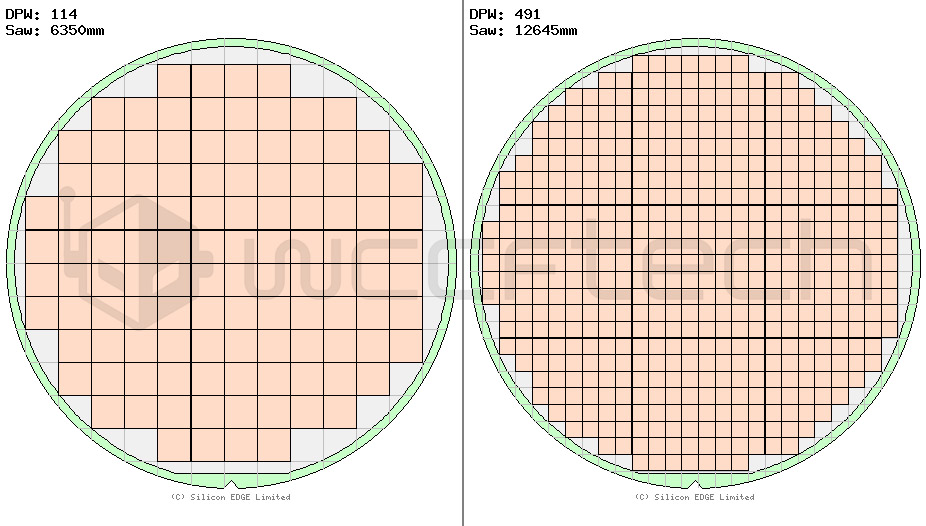
ダイの寸法が484mm²(例:Vega 64)の場合、ダイの寸法は22mm x 22mmに相当します。
このモノリシック・ダイを4x11mm x 11mmに分割すると、同じ純表面積(484mm²)が得られ、歩留まりも向上します。
どのくらい?見てみましょう。概算では、300mmのウェハで114個のモノリシックダイ(22x22)または491個の小さいダイ(11x11)を製造することができます。
1つのモノリシック部品に等しい4つの小さいダイが必要なので、最終的には122個の484mm²のMCMダイが必要になります。
これは7.6%の歩留まり向上になります。
画像出典:wccftech
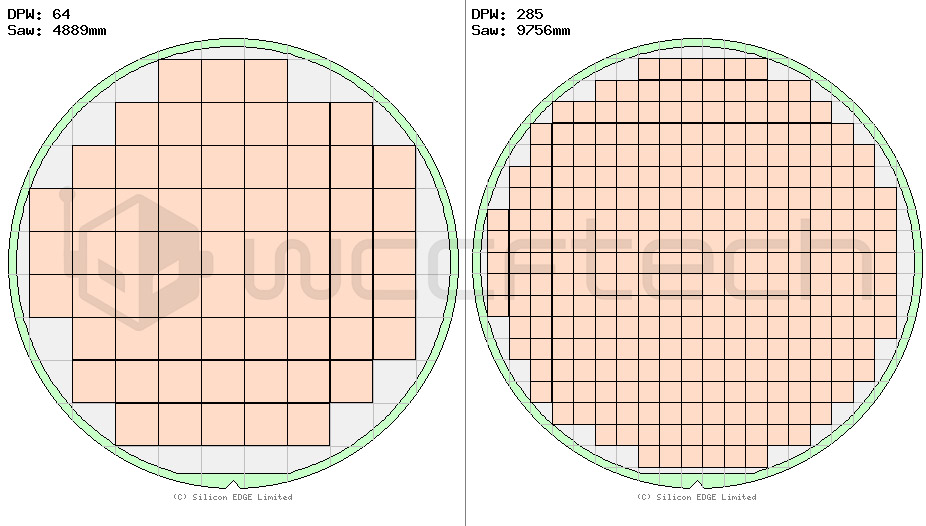
歩留まりの向上は、より大きなチップではさらに大きくなります。リソグラフィ技術の上限は(合理的な歩留まりで)約815mm²です。
1枚の300mmウェハで、これらのうち約64個(28.55x28.55)または285個の小さなダイ(14.27x14.27)を得ることができます。
これにより、合計71個のMCMベースのダイが得られ、歩留まりは約11%向上します。
これは非常に大雑把な近似値であり、パッケージングの歩留まりや長方形のダイ、ウェーハの他の形状ベースの最適化など、いくつかの要因を考慮に入れていませんが、基本的な考え方は十分に保持されています。
逆に、廃棄物の削減による利益の増加も考慮に入れていません - 欠陥のある815mm²のモノリシックダイは、203mm²の単一ダイよりもはるかに廃棄物が多いのです! つまり、このアプローチには、不良品ダイの影響を最小限に抑えるという利点がありますが、これは、使用不能なダイを考慮に入れると、歩留まりの数字に上乗せされます。
長い話をすると、NVIDIAはMCMベースのGPUを作ることが完全に可能であり、Hopper GPUのためにこれを選択した場合には、歩留まりの面でも大きなメリットを得ることができるということです。
7nmノードがEUVで成熟した段階に入ったことを考えると、エッチングは非常に明確になり、このようなコンセプトを簡単にサポートできるようになるはずだが、レチクルサイズによってはまだ制限されている。
MCMベースの設計に切り替えれば、NVIDIAは815mm²以上のダイサイズを持つ巨大なGPUを構築することができます(AMDが証明しているように、MCMでは限界があります)。
したがって、これまで成功を収めてきた非線形な性能向上の傾向を継続したいのであれば、これを採用する以外の選択肢はないかもしれません。
ソース:wccftech - NVIDIA’s Hopper Architecture Will Be Made On TSMC’s 5nm Process, Launching 2021
解説:
TSMC5nmの予約とHopper GPUに関する怪しげな情報
nVidiaが2021年にTSMCとSamsungの5nmを予約しているというのはほぼ確定といってもよいようですが、このHopper GPUというのがどのような位置づけになるのかが理解に苦しみます。
RTX3000シリーズは2020年の9月というような情報も流れていますが、2021年からの5nmというのは明らかに時期がずれており、一体これを何に使うのかというのが疑問として残ります。
nVidiaがMCMベースのチップを計画しているのではないかという憶測が書いてありますが、私はそこまで夢見がちな説を唱えられません。(笑
HopperがGeforceに関係があるのかないのか現時点ではやはりはっきりしません。
一説によるとSwitch2用のSoCに使うのではないかといわれていましたが、さすがにTSMCとSamsungの両方の5nmを予約しているというのはちょっと規模が大きすぎると思います。
こうした動きは型落ちのプロセスを使って巨大なモノリシックチップを偏執的に構築してきたnVidiaのこれまでの動きとは正反対のものです。
Samsungの10nmを使って安上がりの巨大チップを作るという噂が以前流れていましたが、そっちのほうがまだ説得力があったと思います。
MCMを使ってGPUをGPUブロックに分けて、製造コストを安く抑えるというのはなかなか説得力のある話ですが、いまだ想像の域を出ません。
ただ、nVidiaが安上がりな枯れた製造プロセスを使うのをやめたならば、やはりMCMが関係しているのではないかと推測するのは妥当だとは私も思います。
どっちにしても、nVidiaとはコストにシビアな会社であり、事実Turingでは、時期的な問題があったにせよ、圧倒的な優位性のある7nmを使うのをやめて枯れ切った12nmを使ったほどですから、最新の5nmを一体何に使うのかはちょっと想像がつきませんし、興味が尽きないところではあります。
今回の内容は憶測に憶測を建て増ししたものであり、話半分どころか1/4くらいに聞いておいてください。
[st_af id="7964"]