
NVIDIAのGTC 2020が近づくにつれて、Ampere GA100 GPUの新しい仕様がリークされました。これは、グリーンチームの次世代GPUアーキテクチャがComputeの強力な存在になることを改めて示しています。
NVIDIA Ampere GPU仕様には、8192 CUDAコア、最大48 GBのHBM2eメモリ、および2 GHzを超えるコアクロックがフラッグシップGA100チップに搭載されると噂されています
最新の仕様は、以前にリークを投稿することを知っているユーザーが、主要なAmpere GPUであるGA100の主要な詳細をリストアップしたStage1中国語フォーラムからのものです。
NVIDIAのAmpere GPUファミリはしばらく前から知られていますが、NVIDIAがまだ一般に公開していないものです。
GA100自体など、さまざまなリークが発生したAmpereファミリのGPUがいくつかありますが、AmpereがNVIDIAがHPC / Data Centerセグメントのために次に導入するGPUファミリーの名前であるかどうかについて、決定的な証拠はありませんでした。
フォーラムのメンバーによると、主力のAmpere GPUはGA100であり、予想通り、フル構成には128のストリーミングマルチプロセッサユニットまたは8192のCUDAコアが搭載されます。
NVIDIAがどのプロセスノードを使用しているかは不明ですが、以前のレポートでは7nmが強調されています。
新しいプロセスとGPUアーキテクチャを利用して、このチップはGPUコアで最大2.2 GHzの最大ブーストクロックを搭載すると噂されています。
これは、Quadro GV100グラフィックスカードに搭載されているGV100 GPUよりも少なくとも35%速いクロック速度の大きな性能向上です。
Quadro GV100は、1627 MHzでGV100 GPUの最速のクロックを備え、16.6 TFLOPsのFP32演算性能を提供します。

GA100 GPUのコア数とブーストクロックに基づいて、文字通り型破りなFP32演算の36 TFLOPの大規模なパフォーマンスを見ています。
これはFP32演算性能の2倍以上の向上であり、これらの数値が合法である場合、現代のGPUが処理できるFP64の数値をはるかに上回る18のFP64演算性能の異常なTFLOPに注目します。
GPUは300W TDPを搭載し、HBM2eメモリを搭載し、24 GBモデルと48 GBモデルの2つのフレーバーで提供されると規定されています。
これらのメモリ構成は、32 GB HBM2eメモリを備えた他の製品も見られたため、上位製品のみに対応している可能性があります。 NVIDIAは、新しいAmpere GPUでTensorコアを2倍にするという噂もあります。
現在の5120 CUDAコアVolta GV100 GPUは640個のTensorコアを備えているため、8192 CUDAコアを備えたAmpere GPUは、Tensor処理用に1024個のコアを備えています。
しかし、NVIDIAはTensorコアの数を2倍に増やす可能性があるとの噂があるため、8192 CUDAコアチップ用の2048個のTensorコアを検討します。
先週リークした他のモデルの仕様は以下のとおりです。
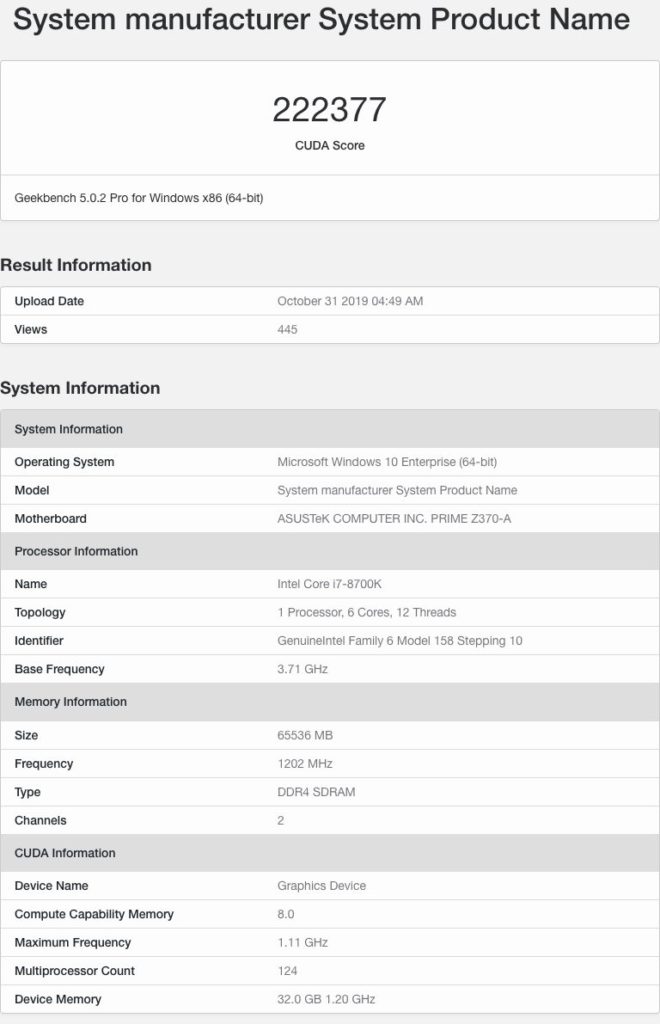
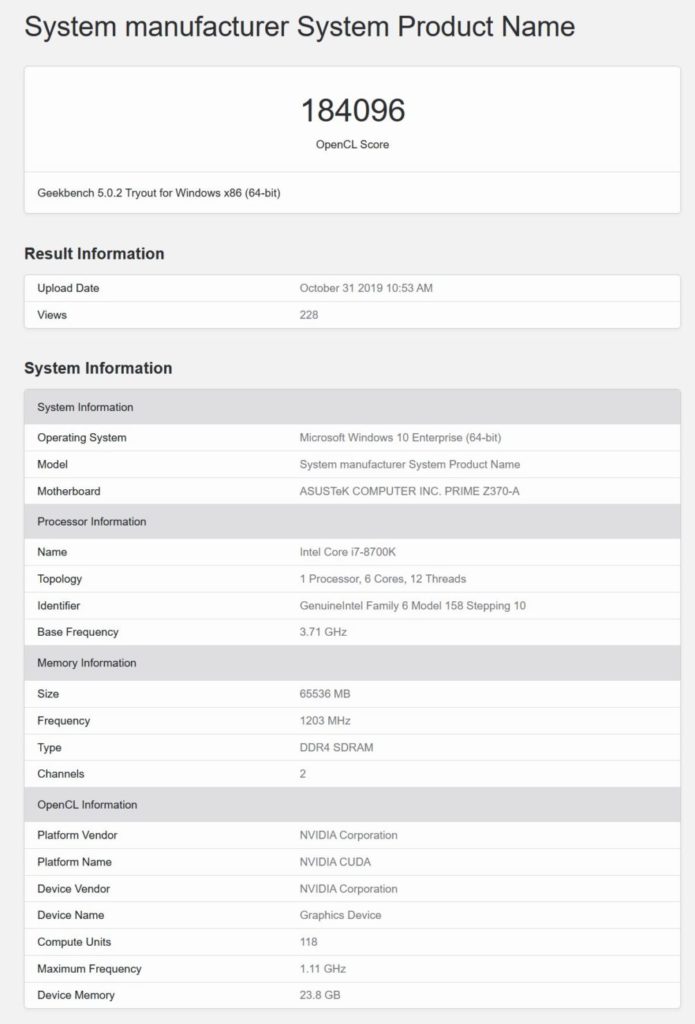
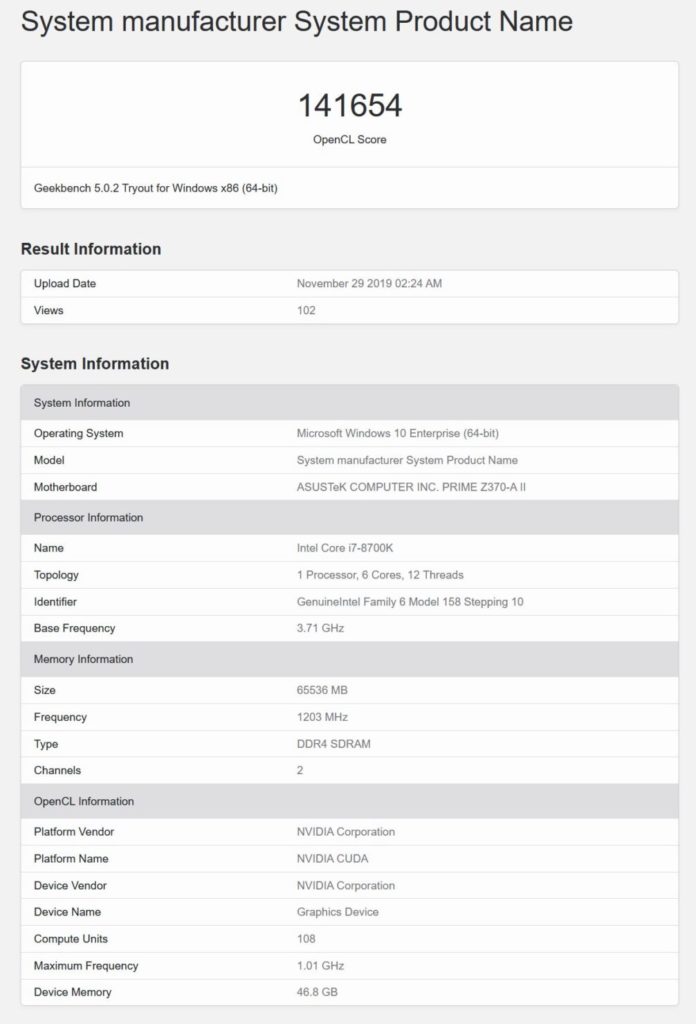
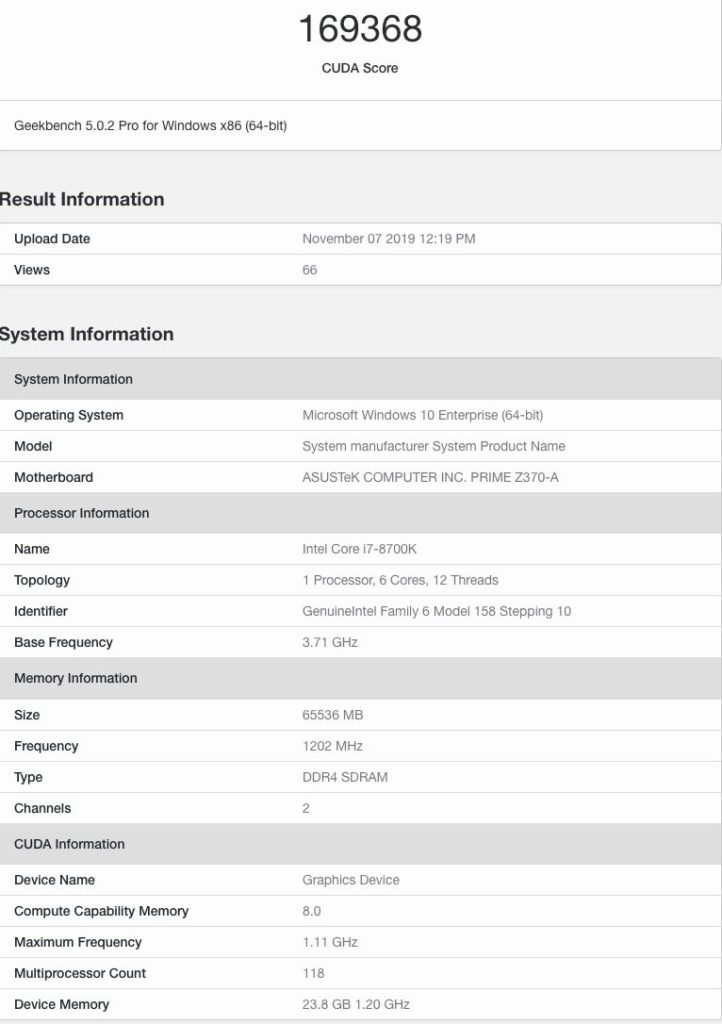
NVIDIAの次世代GPU#1の仕様とパフォーマンス
NVIDIAのプロフェッショナルGPUアーキテクチャには、ストリーミングマルチプロセッサごとに64 CUDAコアデザインが付属しているため、この最初のGPUの合計SMカウントは124で、7936 CUDAコアに相当します。
これは、Tesla V100の5120コアを超えるCUDAコアの55%の増加です。 GPUの最大クロック速度は1.1 GHzであり、この最終化されていないクロックで、約17.5〜18 TFLOPのFP32演算性能を発揮します。
1200 MHzで32 GBのHBM2eメモリクロッキングを搭載し、4096ビットのバスインターフェイス上で動作します。
私がHBM2eに言及する理由は、それが最新の標準であり、NVIDIAが発売時にHPC製品で最も高度なメモリを標準で使用することが知られているためです。
コアおよびメモリの仕様に加えて、GPUは32 MBのL2キャッシュをパックします。これは、わずか6 MBのL2キャッシュをパックするVolta GV100 GPUの5.33倍の増加です。
膨大な量のキャッシュを考えると、NVIDIAの次世代GPUでの長年の開発により、パフォーマンスが大幅に向上し、アーキテクチャが大幅に変更されることが予想されます。
パフォーマンスに関する限り、Geekbench 5のOpenCLベンチマーク(CUDA)でGPUは222377ポイントを獲得しています。
プラットフォームはCUDA 8.0を実行しており、テスト時にGPUがCUDA 8.0に対して完全に最適化されていなかった可能性が高いです。
そうは言っても、このカードの仕様は文字通り非常識に見えるので、他の2つのバリエーションに取り掛かりましょう。
NVIDIAの次世代GPU#2仕様とパフォーマンス
2番目のGPUには、合計118個のSMまたは7552 CUDAコアが搭載されています。 これは、80個のSMと合計24 MBのL2キャッシュに5120個のCUDAコアが詰め込まれたTesla V100よりもCUDAコアが47.5%増加したことです。
また、このGPUは1.10 GHzの最大速度でクロックされ、1200 MHzのクロック速度で3072ビットのバスに沿って実行される24 GBのHBM2eメモリを備えています。
これらの速度では、このチップは合計で約16.7 TFLOPの理論上の計算馬力を提供するはずですが、再び、クロック速度は間違いなく最終的に見えず、それより高くなる可能性があります。
NVIDIAの次世代GPU#3仕様とパフォーマンス
最後に、108 SMまたは6912 CUDAコアバリアントがあり、報告されているクロック速度は1.01 GHzであるか、3つのGPUの中で最も低速です。
GPUにより、Tesla V100よりもCUDAコア数が35%増加し、46.8 GBのHBM2eメモリを搭載しているようです。
これは、Geekbenchベンチマークが合計メモリをどのように認識するかに関するエラーである可能性があり、実際には48 GBである可能性があり、これはより理にかなっています。
このGPUはGeekbench 5(CUDA)ベンチマークで141654ポイントを獲得しますが、これもまたクロック速度が遅いために最終スコアではありません。
NVIDIA Teslaグラフィックカードの比較
| Tesla GPU カード名 | NVIDIA Tesla M2090 | NVIDIA Tesla K40 | NVIDIA Telsa K80 | NVIDIA Tesla P100 | NVIDIA Tesla V100 | NVIDIA Tesla Next-Gen #1 | NVIDIA Tesla Next-Gen #2 | NVIDIA Tesla Next-Gen #3 |
| GPU アーキ テクチャー | Fermi | Kepler | Maxwell | Pascal | Volta | Ampere? | Ampere? | Ampere? |
| 製造 プロセス | 40nm | 28nm | 28nm | 16nm | 12nm | 7nm? | 7nm? | 7nm? |
| GPU名 | GF110 | GK110 | GK210 x 2 | GP100 | GV100 | GA100? | GA100? | GA100? |
| ダイ サイズ | 520mm2 | 561mm2 | 561mm2 | 610mm2 | 815mm2 | 不明 | 不明 | 不明 |
| トランジスタ数 | 30億 トランジスタ | 70.8億 トランジスタ | 70.8億 トランジスタ | 150億 トランジスタ | 211億 トランジスタ | 不明 | 不明 | 不明 |
| CUDA コア数 | 512 Ccs (16 CUs) | 2880 Ccs (15 CUs) | 2496 CCs (13 CUs) x 2 | 3840 CCs | 5120 CCs | 6912 CCs | 7552 CCs | 7936 CCs |
| クロック | Up To 650 MHz | Up To 875 MHz | Up To 875 MHz | Up To 1480 MHz | Up To 1455 MHz | 1.08 GHz (Preliminary) | 1.11 GHz (Preliminary) | 1.11 GHz (Preliminary) |
| FP32 演算能力 | 1.33 TFLOPs | 4.29 TFLOPs | 8.74 TFLOPs | 10.6 TFLOPs | 15.0 TFLOPs | ~15 TFLOPs (Preliminary) | ~17 TFLOPs (Preliminary) | ~18 TFLOPs (Preliminary) |
| FP64 演算能力 | 0.66 TFLOPs | 1.43 TFLOPs | 2.91 TFLOPs | 5.30 TFLOPs | 7.50 TFLOPs | 不明 | 不明 | 不明 |
| VRAM 容量 | 6 GB | 12 GB | 12 GB x 2 | 16 GB | 16 GB | 48 GB | 24 GB | 32 GB |
| VRAM 種類 | GDDR5 | GDDR5 | GDDR5 | HBM2 | HBM2 | HBM2e | HBM2e | HBM2e |
| メモリ バス幅 | 384-bit | 384-bit | 384-bit x 2 | 4096-bit | 4096-bit | 4096-bit? | 3072-bit? | 4096-bit? |
| メモリ 速度 | 3.7 GHz | 6 GHz | 5 GHz | 737 MHz | 878 MHz | 1200 MHz | 1200 MHz | 1200 MHz |
| メモリ 帯域幅 | 177.6 GB/s | 288 GB/s | 240 GB/s | 720 GB/s | 900 GB/s | 1.2 TB/s? | 1.2 TB/s? | 1.2 TB/s? |
| 最大TDP | 250W | 300W | 235W | 300W | 300W | 不明 | 不明 | 不明 |
昨日、AMDは、NVIDIAがPascalアーキテクチャ以来行ってきた方法と同様に、GPUを個別のゲームセグメントとコンピューティングセグメントに分割することを発表しました。
新しいCDNA GPUファミリは今年発売が予定されており、NVIDIAのHPCラインナップに反して、7nmプロセスノードに基づいています。
情報技術担当バイスプレジデントおよびインディアナ大学の最高情報責任者によると、今年の夏にビッグレッドスーパーコンピューターを導入すると、NVIDIAの次世代GPUが既存のVoltaベースのGPUに比べて75%のパフォーマンスを大幅に向上させることが明らかになりました 。
過去に聞いたことがありますが、GPUが最大50%のパフォーマンス向上と2倍の効率性を提供するという報告もあります。
NVIDIAは、次世代のGPUとまったく新しいアーキテクチャを備えたAMDと同等のプロセスであるため、実際の破壊的なパフォーマンスを確認できます。
これらは間違いなくNVIDIAの次世代GPUの噂で報告されているいくつかの大きな仕様と数値ですが、読者には割り引いて考えることをお勧めします。
3月22日に開催されるGTC 2020オンラインキーノートで、NVIDIAによる次世代GPUの本格的な「公式」発表が確実に期待できます。
解説:
GA100(?)の仕様がリークか?
今回目新しい情報はあまりないです。
そのため、取り上げるかどうか迷いましたが、新型Geforceにつながる情報ですので、取り上げることにしました。
8192CUDAコアというのは少しGeforceの仕様を見慣れた人ならば想像がつく数字であり、予想通りの仕様だなといった感じです。
今回HBM2eメモリを使い、ハイクロックまで回しているのが印象的です。
GDDR6ではバス幅を増やしたとしてもここまでの帯域は出せないはずですので、クロックを落として省電力性に振り、性能の向上は50%にとどめるというのが一つの方向性ではないかと思います。
HPC向け(GA100?)・・・・75%性能向上、HBM2eメモリ搭載、TDP300W
ゲーム向け(GA102?)・・・50%性能向上、GDDR6メモリ搭載、TDP170-180W程度
凡そのイメージでこのくらいになるのではないかと思います。
RTX3080Ti(?)と目されるモデルは高くなりすぎたRTX2080Tiよりも若干安くなるではないかといわれており、GDDR6メモリになる可能性は非常に高いです。
メモリを増量して帯域幅を増やすという方向性なのと、大量にGDDR6メモリを使うPSとXboxの新型機を生産しているこの2020年に「本当に安くできるのかなあ」と思いますが、この辺はもう祈るしかないです。(笑
コストを度外視できるTITANにはHBM2eメモリを使ってくる可能性は0ではないですが、少なくともその他のゲーム向けモデルはGDDR6になるのではないかと思います。
[st_af id="7964"]