
AMDは、AIと開発者の生産性をさらに加速させるオープン・ソフトウェア・スタック技術の次世代バージョン「ROCm 7」を正式に発表しました。
AMD、ROCm 7を発表:AI推論にフォーカスした次世代オープンスタック・ソフトウェア・イノベーション
ROCm 7の発表により、AMDはついにROCm 6ソフトウェア・スタックから前進する。
ROCm 6ソフトウェア・スタック自体は、ここ数年、AIコンピューティングの登場以来、さまざまなアップデートが行われてきた。
以下は、AMDがROCm 7で注力している主な機能の一部である:
- 最新のアルゴリズムとモデル
- AIを拡張するための高度な機能
- MI350シリーズのサポート
- クラスタ管理
- 企業向け機能

ROCmでは、AMDはソフトウェアスタック内の推論機能の強化にさらに注力しているという。
ROCm 7スタックには、vLLM v1、llm-d、SGLangなどの強化されたフレームワークが含まれるほか、分散推論、Prefill、Disaggregationなどのさまざまな最適化の提供にも注力する。
ROCm 7に搭載される新しいカーネルとアルゴリズムには、GEMMオートチューニング、MoE、アテンション、Pythonベースのカーネルオーサリングなどがある。

AMDはすでにMI350シリーズでFP6とFP4のサポートを発表しており、ROCm 7ではFP8、FP6、FP4、Mixed precisionといったこれらの高度なデータ型もフルサポートしている。
パフォーマンスに関してAMDは、推論がROCm 7の最大の焦点であり、AIワークロードで最大3.5倍のパフォーマンス向上を実現したと述べている。
性能向上の内訳は、ROCm 6と比較して、Llama 3.1 70Bで最大3.2倍、Qwen2-72Bで最大3.4倍、Deep Seek R1で最大3.8倍となっている。
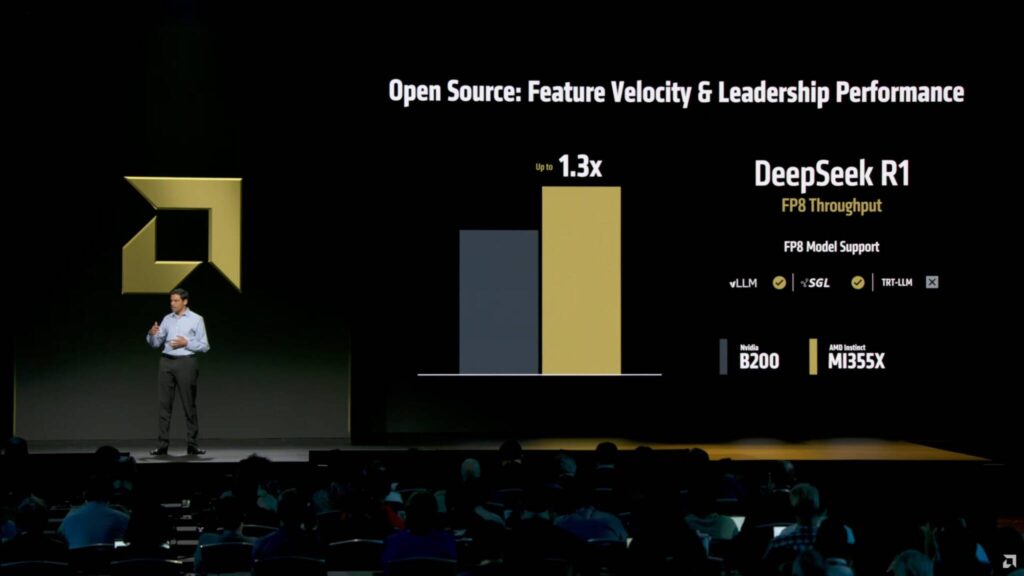
また、DeepSeek R1において、AMDはInstinct MI355X GPU上で動作するROCm 7スタックを、CUDAを実行するNVIDIA Blackwell B200プラットフォームと比較しています。
ROCm 7は、DeepSeek R1(FP8スループット)において、NVIDIAのCUDAに対して30%高速なスループット性能を達成しています。

トレーニングのパフォーマンスに関しては、ROCm 7はROCm 6を大幅に上回り、Llama 2 70B、Llama 3.1 8B、Quen 1.5 7Bで3倍の向上を達成した。

新しいROCmソフトウェアスタックは、完全なエンドツーエンドのソリューション、安全なデータ統合、導入の容易性を備えたエンタープライズAIにも拡張される。
このソフトウェアスタックはGPU、CPU、DPUと連携し、GenAIワークロードに重点を置いた様々なワークロードをサポートする。

最後に、AMDは今年後半にRyzenベースのラップトップとワークステーションでROCmサポートを開始し、今年後半にはインボックスLinuxとフルWindowsのサポートも開始する。
解説:
ROCm7.0の発表をAMDが行ったようです。
誤解のないようにお断りしておきますが、まだ公開されてません。
この記事を書いている現時点での最新版はROCm6.4.1になります。
ROCm7はROCm6.xと比較して3.5倍程度の性能を発揮するようです。
ただし、元記事を読むとFP4やFP6が強いようで、速度の恩恵はLLMが中心なのかなと思います。
私が配布しているStable Diffusion WebUI ZLUDAのバッチファイルは画像生成AIですからFP16やPF8が中心です。
そちらにはどのくらいの恩恵があるのですかね。
現在最新のFlux1.devはFP4/FP6/FP8がありますが、画質はFP8がギリギリといわれています。
ZLUDAを通じてHIPやROCmの限界を皆さんも知ったと思いますが、とりあえずすでに古くなっているCUDA11.8までにしか互換性がないという点は改善されるのだろうと思います。
ROCmはAMDが今一番力を入れている製品ですから、今後もかなり大幅な機能・性能が向上すると思います。
これらの性能向上は新世代の製品の機能を前提にされている可能性もあるので旧世代のユーザーは過剰な期待を抱かないようにしておいた方がよいと思います。
今最新のAIですから、よくも悪くも古いものはあまり価値がないですし、陳腐化が早いです。