
NVIDIAは、HBM4メモリを搭載した次世代GPU「Rubin R100」を2025年第4四半期までにTSMC 3nmノードで量産する見込みだ。
NVIDIAの次世代GPU「Rubin R100」はAI性能を高めつつ電力効率に注力、HBM4メモリとTSMC 3nmノードを採用へ
この新情報は、TF International Securitiesのアナリスト、Mich-Chi Kuo氏によるもので、同氏は、NVIDIAが、宇宙の暗黒物質の解明に大きく貢献し、銀河の回転率に関する先駆的な研究でもあった米国の天文学者、Vera Rubin氏にちなんで命名された次世代GPU、Rubin R100の基礎を築いたとしている。
クオ氏は、NVIDIA Rubin R100 GPUはRシリーズのラインアップの一部となり、2025年第4四半期に量産される見込みである一方、DGXやHGXソリューションなどのシステムは2026年前半に量産される見込みであると述べている。
NVIDIAは最近、次世代GPU「Blackwell B100」を発表した。
このGPUは、AI性能の大幅な向上を特徴としており、Ampere GPUでその基礎を築いた同社初の適切なチップレット設計となっている。
Four years ago, we split GA100 into two halves that communicate through an interconnect. It was a big move - and yet barely anyone noticed, thanks to amazing work from CUDA and the GPU team.
Today, that work comes to fruition with the Blackwell launch. Two dies. One awesome GPU. https://t.co/XuaUQPskkM pic.twitter.com/svRKhwPYEn
— Bryan Catanzaro (@ctnzr) March 18, 2024
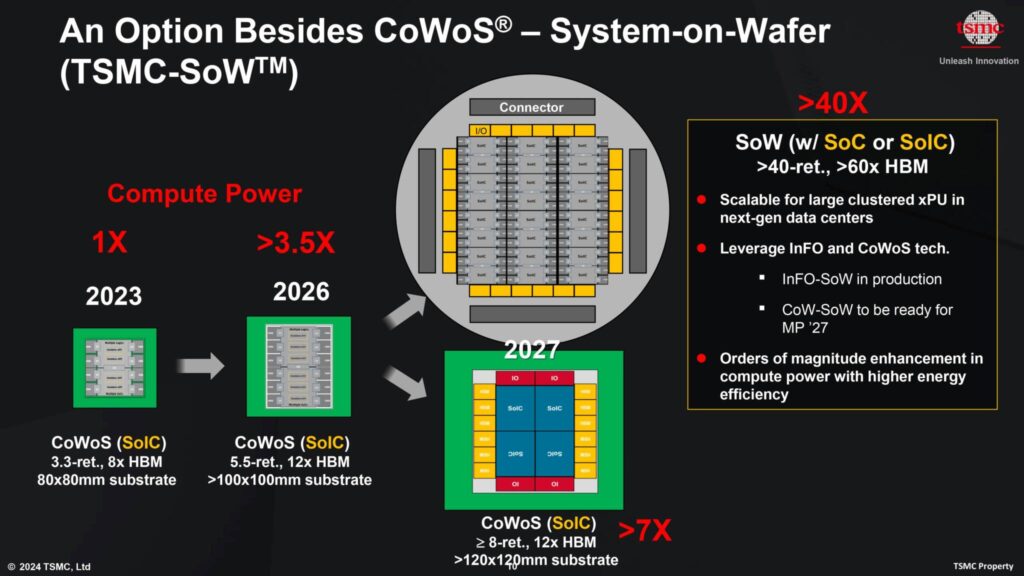
NVIDIAのRubin R100 GPUは、(Blackwellの3.3倍に対して)4倍のレチクル設計を採用し、N3プロセスノードのTSMC CoWoS-Lパッケージング技術を使用して製造されると予想されている。
TSMCは最近、2026年までに最大5.5倍のレチクルサイズのチップを製造する計画を打ち出した。
このチップは100x100mmの基板を採用し、現在の80x80mmパッケージの8HBMサイトに対し、最大12HBMサイトを可能にする。
この半導体会社はまた、120x120mmパッケージ構成で8倍以上のレチクルサイズを特徴とする新しいSoIC設計に移行する計画もある。
これらはまだ計画中であるため、Rubin GPUのレチクルサイズは4xレチクルの間のどこかであるとより現実的に予想できる。
その他の情報によると、NVIDIAは次世代HBM4 DRAMをR100 GPUに搭載する予定だという。同社は現在、B100 GPU向けに最速のHBM3Eメモリを利用しており、2025年後半にメモリソリューションが広く量産されるようになれば、これらのチップをHBM4モデルでリフレッシュする見込みだ。
これは、R100 GPUが量産体制に入ると予想される時期とほぼ同じになる。HBM4。サムスンとSKハイニックスの両社は、2025年に最大16Hiスタックの次世代メモリ・ソリューションの開発を開始する計画を明らかにしている。
NVIDIAはまた、TSMCの3nmプロセスをベースとする2つのR100 GPUとアップグレードされたGrace CPUを搭載するGR200 Superchipモジュール向けに、Grace CPUをアップグレードする予定である。
現在、Grace CPUはTSMCの5nmプロセスノードで製造されており、Grace Superchipソリューションには72コア、合計144コアが搭載されている。

エヌビディアが次世代GPU「Rubin R100」で最も注力するのは電力効率だ。同社は、データセンター向けチップの電力ニーズが高まっていることを認識しており、チップのAI機能を向上させながら、この部門で大幅な改善を提供する予定だ。
R100 GPUの登場はまだ先であり、来年のGTCまでお披露目されることはないだろうが、もしこの情報が正しければ、NVIDIAは間違いなくAIとデータセンター分野のために、たくさんのエキサイティングな開発を控えていることになる。
NVIDIA データセンター / AI GPU ロードマップ
| GPU コードネーム | X | Rubin | Blackwell | Hopper | Ampere | Volta | Pascal |
| GPUファミリー | GX200 | GR100 | GB200 | GH200/GH100 | GA100 | GV100 | GP100 |
| GPU SKU | X100 | R100 | B100/B200 | H100/H200 | A100 | V100 | P100 |
| メモリ | HBM4e? | HBM4? | HBM3e | HBM2e/ HBM3/ HBM3e | HBM2e | HBM2 | HBM2 |
| 発売年 | 202X | 2025 | 2024 | 2022-2024 | 2020-2022 | 2018 | 2016 |
解説:
2025年に発売予定のサーバー向けAI/MLアクセラレーターRUBINはTSMC3nmを使用する予定
本日のBalckwellの記事でも書きましたが、どうも大幅にトランジスタ密度が上がるTSMC3nmは先にRUBINに使われるようです。
残念ながらGeforceがTSMC3nmの恩恵を受けるのは早くても次々世代のRTX6000シリーズからになりそうです。
ぶっちゃけた話、TSMC4NPではクロックもあまり上がらなさそうですし、MCMでオンパッケージの規模を大きくできたとしても排熱の関係もあってそれほど性能は上げられないのではないかと思います。
450Wまで達したTDPはこれ以上上げるのは難しいでしょう。
今が上限とすると効率が上がらない限り性能も上がらないということになります。
あのIntelですらも14nmで足踏みしてAMDに苦杯をなめさせられた事実は記憶に新しいですが、基本的に製造プロセスが上がらなければいくら設計を改良したとしても上げられる効率には限度があるということです。
チップを大きくしても排熱の問題は解決できませんから、今度はクロックを上げるのが難しくなってきます。
例のAIで最適化して性能を上げましたということでもない限り、飛躍的に性能を向上させるのは難しそうです。
※ BlackwellがAI/ML設計を行っているかどうかはわかりません。例として話を挙げているだけですから注意してください。
AI/MLは儲かっていますから、利益の一部をサーバー向けのAI/MLアクセラレーターに還元するのは理解できますが、Geforceにも少しおこぼれがあっても罰は当たらないのではないかなあと思います。(苦笑。
ここ2-3年はAI/MLアクセラレーターを横目でちらちらと伺いつつ、ため息をつく日々が続きそうです。
いやあ、TSMC3nmへの道のりは遠いですねえ。
[st_af id="7964"]