
記事の冒頭にあるこれらの大胆な言葉に注目してください
完全に未検証のリークにあなたが興味を覚えない場合-今すぐ読むのをやめるのが最善でしょう。
しかし、残りの方のために、ここに噂のまとめ記事があります-そのほとんどはツイッターでKittyCorgiのものです。
これがうわさのタグが付けられている理由は、この特定のアカウントにはリークの履歴がなく、これまでに2、3のツイートしか投稿していないためです。
これはすべて完全なものであることが判明する可能性がありますが、私たちはこれを愛好家にとってカバーする価値があると考えました。
この時点で、この記事を実際のリークではなく、願いを叶えるための練習のように扱うのが最善かもしれません。
NVIDIA Ampere GPU 'GA100'フラッグシップには、826mm²の大規模なダイが搭載されます
NVIDIAの今後のAmpere GPUは、ハッタリと期待の五分五分に入り混じっています。
しかし、この噂が信じられるとすれば、NVIDIAの主力GPUには大規模な826mm²のダイとなります。
プロセスノードについては言及しませんでしたが、この大きさのダイは、12NFFのような古い、より成熟したノードである確率をわずかに高めます。
TSMC 7nmの成熟度にもよりますが、826mm²のような大きなダイは、限られた数量の生産でもまったく問題になりません。
以前のリークでは、Ampereを使用して同社が7nmに移行することを指摘していたため、この記事全体では、このアーキテクチャ全体が7nmに基づいていると想定しています。
7nmの826mm²のダイは、非常に巨大で非常に高密度になります。
これは、nVidiaがハイエンドパーツ(通常はワークステーションで使用され、TITANシリーズでは使用されないことが多い)でこの性能レベルと熱レベルを以前に使用していたことを考えると、同社の完全な特徴を示していないとは言い切れません。
この規模のGPUは、AMDが2020年の残りの期間に計画していたものを簡単に破壊してしまいます。
NVIDIA Ampere GPUは、再設計されたTensorコアにより、RTXが2倍高速になります
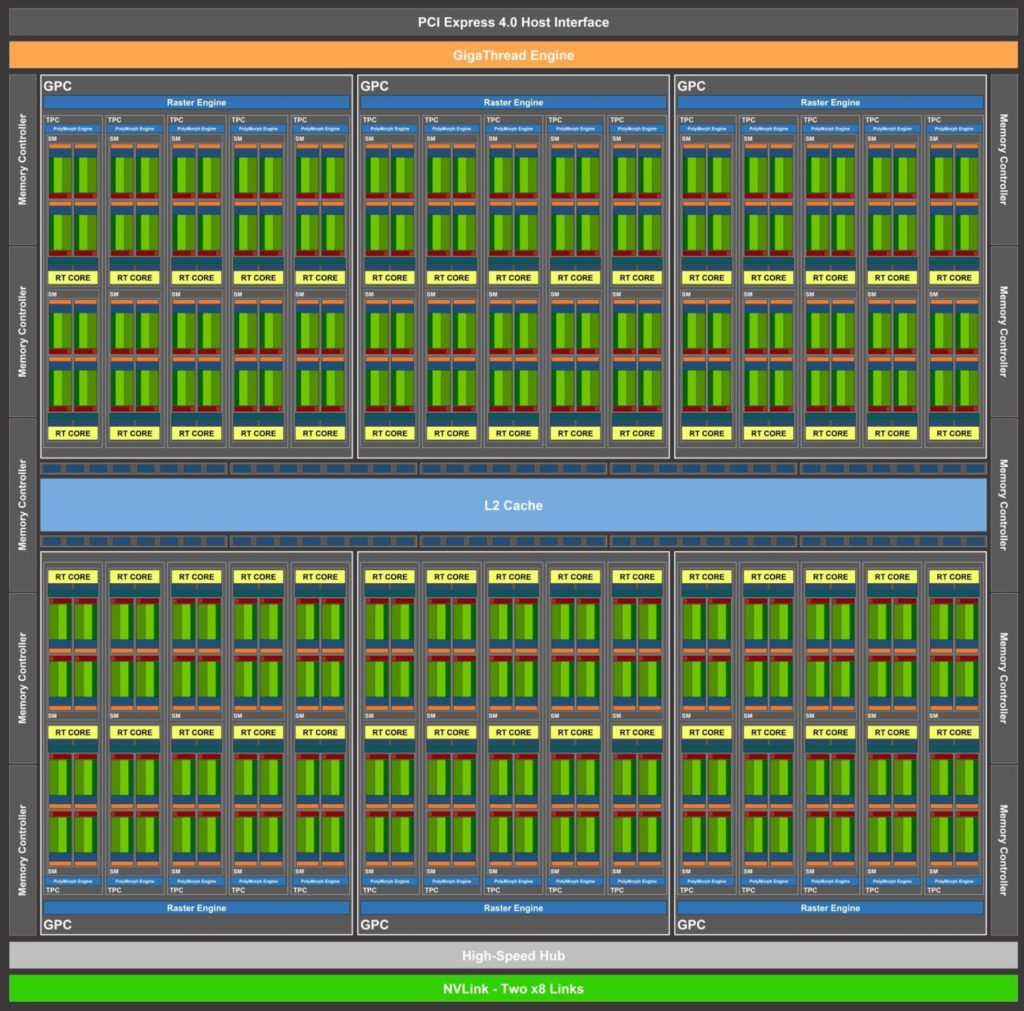
ここで興味深いことがありますが、噂には、アーキテクチャの改善とNVIDIAのRTX戦略の倍増を示すブロック図(KittyCorgiが作成したと思います)が含まれています。
最後の部分は、TuringのRTX部分が比較的小さく、RTXゲームのアプリケーションの規模が制限されていたため、特に驚くことではありません。

噂で提案された改善点のリストは次のとおりです。
- INT32ユニットは変更されません。
- シェーダーの割合については、FP32ユニットを2倍にします。
- 新しいTensorコアのパフォーマンスは2倍になりました。
- より包括的な機能のための拡張L1データキャッシュ。
- まったく新しいデザインのRT CORE ADVANCEDを使用したRTX GAMINGの真のアーキテクチャ。
最後の部分は、NVIDIAのマーケティング資料から直接聞こえるものであり、これが真実であることが判明するかもしれないと私に思わせるものです。
RT Core Advancedは、英語を母国語としない人にとっては非常に妥当な命名スキームでもあります。
まだ興味をそそられていると思いますが、これはかなり割り引いて考えることをお勧めします。
NVIDIA RTX 3080 Ti 'GA103' GPUには80個のSMと320ビット10GB / 20GBグラフィックメモリが搭載されます
噂はこれで終わりではありません。ツイッターではGA103およびGA104 GPUのブロック図も作成されました。
これは、メインストリームクライアントが起動後に実際に取得するグラフィックプロセッサになります。
これらは、ゲーマーが予算内でなんとか購入できる製品です。
最終的にRTX 3080 TiまたはNVがそれを呼ぶことにしたものであるハイエンドGA103部品については、60個のSMで、古い割合を想定した合計3840個のCUDAコア、またはSMあたり新しい128個のコアを想定した7680個のCUDAコアが見られます。(旗、BoroとPCMasterRaceに感謝!)。
参考までに、RTX 2080 Tiには4608 CUDAコアを備えた72個のSMがあります。
RTXコアの2倍のパフォーマンス(および結果として生じるDLSSスループットの増加)と組み合わせると、Turingの50%の範囲での実際のパフォーマンスの向上を簡単に確認できます。
NVIDIAが7nmプロセスに移行する場合、許容される電力しきい値内に十分に収まりながら、これらすべてを管理できます。
GA103 Ampere GPUは、10GB / 20GB vRAMと結合されます。
NVIDIA RTX 3080 'GA104' GPUには48個のSMと256ビット8GB / 16GBグラフィックスメモリが搭載されます。
次に、GA104 GPUがあり、48個のSM(古い割合に基づいた3072個のCUDAコア、新しい6144個)でRTX 2080の置き換え(RTX 3080?)になります。
これは、46 SMのRTX 2080よりもわずかに大きくなっています。 より高いパフォーマンススループットと2倍のRTXコアを組み合わせることで、これが真実であることが判明した場合、再び大幅なパフォーマンスの向上を期待しています。
噂によると、RTX 3080 GPUは8GB / 16GBのvRAMと256ビットのバス幅で結合されます。
この噂が真実であるかどうかはわかりませんが(ゲーマーとしてはそう思います)、お茶を飲みながら非常に興味深い読み物になります。
1つ確かなのは、NVIDIAのAmpere GPUのメディアによる大騒ぎは過去最高を記録しており、ジェンセンが個人的に報道関係者を招待することで、今年のGTC 2020でそれらを発表する準備が整ったことを示しています。
ソース:wccftech - RUMORS: NVIDIA Ampere GPU Massive Die Size, Specifications, Architecture and More!
解説:
きわめてうさん臭い情報
今回のもとになっているのはあるツイッターアカウントのツイートです。
それが上のアカウントですが、1月に開設されたばかりで、今回の情報を含めたツイートを数回ツイートしたのみとなっています。
フェイク情報のアカウントといわれてもおかしくありません。
この情報は今までの情報とは大きく異なっており、RT CoreとTensorコアの改良が主なように見えます。
また、メモリを増量して帯域幅を増やすという点がありません。
コスト的にはこちらのほうが説得力がありますが、このままの設計で出るとしたら、メモリがボトルネックになる可能性が大です。
少なくとも配信性能はあまり高くならないように思えます。
バス幅が256bitだつた場合、GDDR6メモリ帯域幅は以下のようになります。
- 12Gbps=384GB/s
- 14Gbps=448GB/s・・・Turingの多くのモデルで採用されている速度
- 16Gbps=512GB/s
- 18Gbps=576GB/s
これだと、18GbpsのGDDR6だった場合でも1.3倍弱の速度アップにとどまります。
メモリの帯域幅がすべてではありませんが、非常に分かりやすい要素の一つですので、何か現実味がないなあという感じです。
もう一つ現実味がないのが、ゲーマー向けのフラッグシップであるRTX3080Tiが3840CUDAコア、320bitのメモリバス幅という点です。
もっともこれは、CUDAコアの数が2倍の7680個になる可能性が指摘されています。
nVidiaがここまでAMDに対して「なめプ」する場合、Big Naviにブチ抜かれる可能性もあるのかなと思います。
また、GA100のダイサイズ826mm2って7nmで可能なの?というレベルです。
今回の情報はどれをとってもうさん臭い感じで、フェイクではないかなと思います。
まさしく絵にかいたような怪情報ですが、貴重なRTX3000シリーズの情報ですので、参考までに取り上げてみました。
判断は見ている方にお任せしますが、メモリが2倍になっても帯域が2倍になっているわけではないので、ぶっちゃけチップの性能向上に足回りがついて行ってなく、理にかなってないと私は感じます。
もし本当にこのしょぼいスペックで出るのだとしたら、Big Navi無双になる可能性も出てくるのかなと思います。
[st_af id="7964"]