
本日、英国のチップデザイナーARMから大きな発表がありました。 同社は、Cortex A77コアとまったく新しいGPUアーキテクチャを発表しました。
2019年の主力製品がクアルコムのSnapdragon 855によって供給されるため、これらの変更は来年から発売されるAndroidスマートフォンに電力を供給することになります。
IPとデザイン。 詳細は下記をご覧ください。
ARMのCortex A77コアは、同社がまったく新しいGPUアーキテクチャを発表したときに、前任者に重要な変更を加えました
2019年に解決するにつれて、スマートフォン市場の変化は確実になっています。
SoCが計算およびMachine Learningのワークロードをサポートする必要性が高まっており、ベンダーはそれに応じてソリューションを調整しています。
ARMはCortex A77と「Valhall」と名付けられた新しいGPUアーキテクチャを発表することによってこの傾向を追いかけました。
Cortex A77以降、ARMはCortex A76のパフォーマンスを維持しながら消費電力を削減することに注力してきました。
同社は分岐予測を2倍にし、フェッチ帯域幅を増やし、新しいALUパイプラインを追加し、そしてデコーダ幅を増やしました。
Cortex A77の分岐予測装置の実行帯域幅は、64B /サイクルに倍増しました。
ARMはまた、予測子のBTB(Branch Target Buffer)容量を8Kエントリに拡大しました。
IntelとAMDのx86設計に沿った素晴らしいアップグレードは、A77のフロントエンドにあるまったく新しいMacro-OP(Mop)キャッシュです。
モップはA77が10サイクルに分岐の誤予測待ち時間を減らすことを可能にします。
ARMはまた、命令がすでにMop内に存在する場合にコアがデコードステージをバイパスできるようにA77を設計しました。

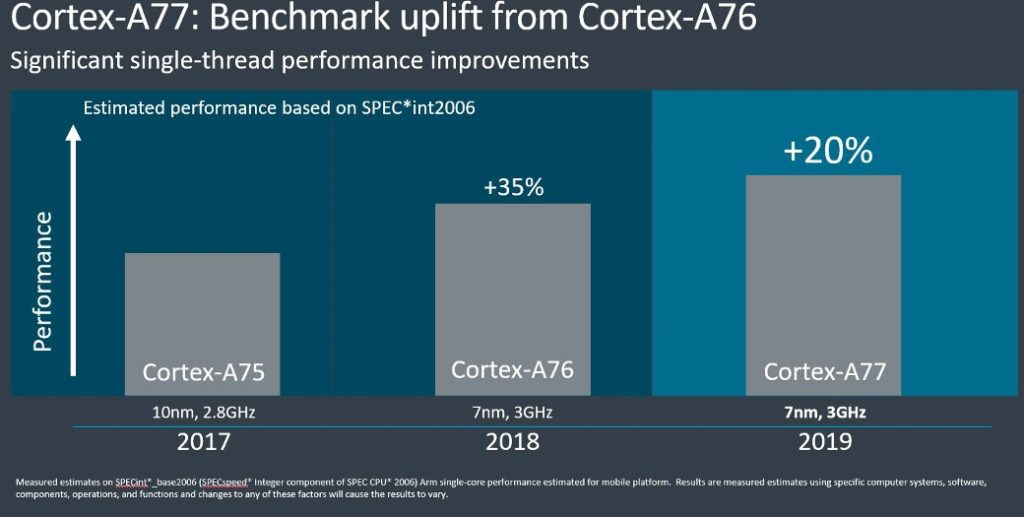
ARMのCortex A77 CPUは、シングルコアスコアで20%の向上、浮動小数点計算で35%の向上を約束
A77のバックエンドに新しいALUを追加するというARMの決定は、バックエンドのボトルネックを減らすことによってコアのパフォーマンスを向上させます。
A77のL1 / L2データキャッシュには、ストアデータパイプライン専用の発行ポートと、前述の電力効率に貢献するための改良されたエンジンがあります。
彼らの最も優れた改善はデータプリフェッチであり、そこで同社はコアがより多くの命令を管理し、メモリサブシステムの待ち時間に従って振る舞いを適応させることを可能にするために改善を行った。
しかし、A77のキャッシュサイズは今年も変わりません。
コアには64KBのL1キャッシュと256.512KBのプライベートL2 ECCキャッシュがあります。
性能面では、ARMはSPEC2006でA77が整数で23%、浮動小数点性能で35%向上することを約束します。
このチップはメモリの待ち時間も15%改善するでしょう、そして同社はA77がその前任者と同様に3.0GHzに達すると信じています。
ARMのValhall GPUアーキテクチャは、機械学習を60%、性能密度を30%、電力効率を30%向上させます。
ARMの最新のValhall GPUアーキテクチャは、現在のMali G76 GPUに存在する同社のBifrostアーキテクチャへのアップグレードです。
Valhallは、パフォーマンス密度(30%)、機械学習(60%)、および電力効率(30%)の大幅な向上を実現しています。
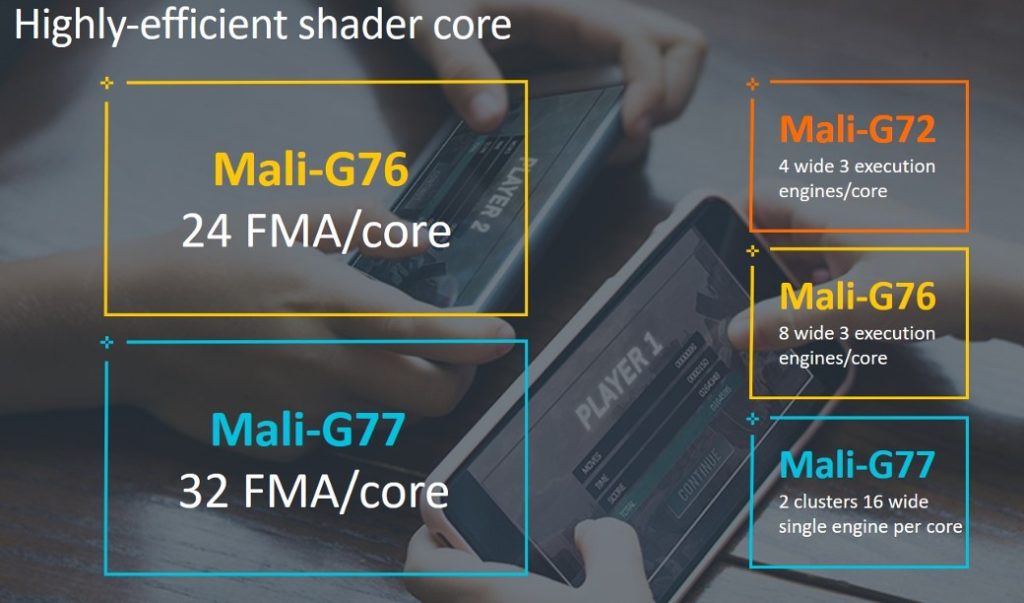
Valhallの実行コアは、AMDおよびNvidiaの製品に見られるものと似ています。
つまり、アーキテクチャにより、Mali G77は16ワイドワープ、各実行エンジンごとに1つの実行エンジンを持つ2つのシェーダコア、実行エンジンごとに16のFMAクラスタを備えています。
ARMは、ValhallとMali G77のパフォーマンス数値を発表した際に、GPUがG76よりも1mm²あたり1.4倍から1.6倍のパフォーマンス向上をもたらすと主張しています。
G77のシェーダーコアはG66のものと同じサイズです。 機械学習のために、G77はその前身の1.6倍の推論性能を持っています。
Mali G77のテクスチャマッピングユニットは、スループットが2倍になり、4バイリニアテクセル/クロック、2トリリニアテクセル/クロック、G76の2倍の異方性フィルタリング、およびテクスチャコンピューティングに重点が置かれています。
G77のコアサポートは現在のところ16コアに制限されていることに注意することが重要です。 G77には、前世代の実行エンジン用にリソースを統合する大きなIPブロックもあります。
ValhallとMali G77は、テクスチャが重いゲームでのパフォーマンスに最適化されており、グラフィックプロセッサでの固定問題スケジューリングはハードウェアによって処理されます。
ARMが新しいグラフィックアーキテクチャを重視しているのは実行コアです。
実行コアは、待ち時間を短縮し、テクスチャマッピングを改善するために最適化されています。
CPUとGPUの設計に加えて、同社はMLプロセッサと呼ばれるカスタムNPU(Neural Processing Unit)も発表した。
このプロセッサは、4 TOPS(1秒あたりの1兆オペレーション)と5TOPS / Wの電力効率を実現できます。 プロセッサは、単一のクラスタ内で最大8個のNPUと32個のTOPSを拡張でき、畳み込みニューラルネットワークとリカレントニューラルネットワークの両方をサポートします。
ARMからのこれらのアップデートは、将来のフラッグシップで一般的になるソフトウェアと一致しています。
機械学習は、やはり多くの異なるアプリケーションの中核です。
考えですか? 下記のコメント欄であなたが何を考えているかを私たちに知らせてください。 最新の情報をお知らせします。
解説:
intelがリーダーとなる高性能デスクトップの世界は二つのAに侵食されています。
一つはAMDでこちらはx86、一つはARMです。
今まではAMDについて触れてきましたが、今回はARMについて触れていきたいと思います。
性能的・技術的な面はあまり詳しく触れません。
原文の方を参照してください。
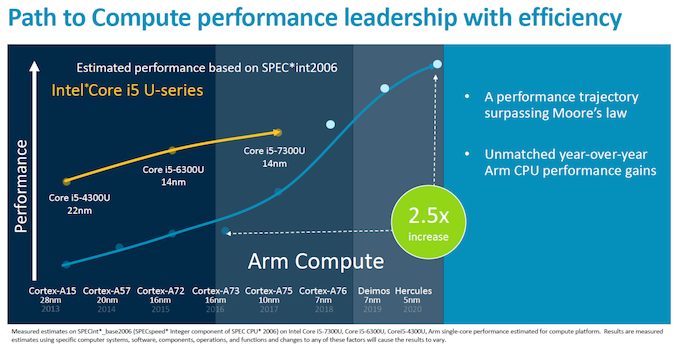
まず製造プロセスに関して言えば、一番最後の画像にありますが、2017年に10nm、2018年に7nm、2019年に7nmとありますが、2019年の7nmはEUVを使う7nm+になります。
(TSMCの)10nmというのは聞いたことが無いと思いますが、すでにデスクトップ向けのPCパーツでは使われない製造プロセスがあるということです。
こうしたモバイル向けのプロセスはモバイルに特化しているので、デスクトップ向けのチップを製造しても高クロックで回らなかったりします。
もはや高性能PCパーツはマジョリティではなくなっているというのがよくわかるのではないかと思います。
文中にNPUという言葉が出てきますが、これは人間の脳神経系を模したニューラルネットワークを組み込んだ人工知能専用のプロセッサーのことです。
nVidiaのTensorコアもそうですが、現在のトレンドは従来の延長線上の演算処理にシリコンを割かないというのが主流になっています。
こうしたプロセッサはスマホのカメラ機能で大きな威力を発揮します。
どこに焦点を合わせるかというのをこうしたプロセッサを使って実現しています。
人間の目は二つあることによって距離感を測定しますが、こうしたプロセッサで処理することにより一つのカメラで距離感があるのと同じ処理をしているということです。
デスクトップPC用として考えるとあまり恩恵のない機能ですが、Tensorコアのようにスーパーコンピューターで処理した中間データを用意することによって、理論値を超えた性能を出すことも可能ということです。
Naviの発表ではレイトレーシングもAI処理もありませんでした。
まあ、Naviに関しては6月のE3にも出てくるでしょうからまだ完全に無いと決まったわけではないですが、あるならばComputexのキーノートで発表するはずなので、ほぼ無いと考えてよいでしょう。
PS5やXbox、STADIAといった最新のコンシュマー向け処理に使われるGPUとしてはクラッシックなスタイルだと思います。
PCやスマホなどのIT機器の世界のシンギュラリティは5G
PCやスマホの世界を一変させるのは5Gの登場だと思います。
わかりやすく言うと、インターネットのスピードがどんどん速くなって、圧縮込みの実効速度がディスプレイのケーブルより速くなったら、もしくはPCI Expressの速度より早くなったら、PC内部に高性能なCPUやGPUを積む必要がなくなるということです。
ネットにつながってさえいればどこにあってもよいので、自宅にある必要すらもないです。
コンピューターのプロセッサをつないでいるバスの速度を超えるネット回線があれば、データセンターの向こう側にGPUやプロセッサがあって、画面だけ転送すればなんでもできるってことですね。
これがアフター5Gの世界で起きることです。
車もカーシェアなどが出てきていますが、GPUもシェアすることになるということです。
SLiなどがやりたければ特別な料金を払って2台分の処理能力を買えばよいだけの話になります。
GPUをシェアすることによって、地域によって昼間の時間が違いますので、夜の場所のデータセンターから昼の場所のデータセンターに演算能力が空いている地域に融通することも出来るでしょう。
また、ゲーム内に必ず見せられる3Dのキャラ・背景などによる演出はいちいち演算処理しないでキャッシュにしてそのまま配信すれば演算能力の節約になります。
個人個人が所有するよりはシェアしたほうが社会全体の効率としても圧倒的に良いのです。
今後はこういった感じで、ものを持つというより借りるという方向性にシフトしていくでしょう。
この辺はYoutubeにも動画を上げていくつもりです。
スマホのプロセッサが高性能化を志向するのも後しばらくで終わりかもしれません。
ネットが高速化すれば、ネットにつないでサーバーで処理したほうが効率がいいですから。
最終的にコンシュマーデバイスは全てシンクライアント化して、サーバーから送られてくる画像を処理するだけのデバイスになると思います。