![]()
AMD、EPYC x86でカムバックを受けました(ご容赦ください)。
訳注:pardon the pun=意図せず語呂合わせになったというニュアンスの慣用表現で、正確に翻訳するのはプロの翻訳者でも難しいです。
そして、2つのチップメーカー間のデータセンターの戦争は急速に熱を帯びています。
通常、ゲーム用チップとコンシューマ用チップは生産の大部分を占めていますが、収益の大部分を占めているのはデータセンターチップであり、アーキテクチャが成功したか失敗したかにかかわらず最大の効果を発揮します。
私はこのことについて、わたくしの意見は最低限度にして、(ベンチマークテストの)結果によって判断を示したいと思います。
前提:この記事に含まれる情報はIntelの広報担当者によって提供されたもので、含まれるすべてのテストは同じAWSインスタンスと設定を使用して個別に検証することができます。
クラウドサービス(IaaS)用のIntelとAMDのEPYC AWSインスタンスのパフォーマンス比較
Amazon AWS EC2は、2018年11月にAMD EPYCベースのインスタンスを発表しました。
これらのインスタンスは、EPYCプロセッサを搭載しており、Intelインスタンスと同じ数の仮想CPUとメモリ容量を備えています。
インスタンスは最小2つのvCPUから最大96のvCPUまで拡張できます。
ただし、一般的な基準では、AWSのAMDインスタンスはIntelインスタンスよりも10%安価です。
これらのインスタンスは、M5(Intel)とM5a(AMD)の汎用インスタンス、R5(Intel)とR5a(AMD)のインスタンスです。
今日は、クラウドインフラストラクチャのさまざまなユースケースを見て、これらのインスタンスを比較します(とにかく可能な範囲で)。
ただし、AMDのインスタンスがEPYCアーキテクチャ上で動作していることは確かですが、Intelのインスタンスはそうではないかもしれません(Amazonはアーキテクチャを説明していません)が、これらのテストのいくつかはAVX 512を必要とするので、我々はそれらが最新のものであると仮定することができます。
テストされたワークロードタイプの完全なリストは次のとおりです。
整数演算・浮動小数点演算 ワークロード:
- SPEC*rate2017_int_base 1 copy (Estimated)
- SPEC*rate2017_fp_base 1 copy (Estimated)
- SPEC*rate2017_int_base (Estimated)
- SPEC*rate2017_fp_base (Estimated)
メモリ帯域幅 ワークロード:
- STREAM_OMP Triad
Web / Java ワークロード:
- Server Side Java* 1 JVM
- WordPress* PHP/HHVM
データベース ワークロード:
- HammerDB PostgreSQL
- MongoDB
高性能演算 ワークロード:
- LAMMPS (Molecular Dynamics)
- High Perf. Linpack
それではさっそくベンチマークを見てみましょう。
- 2019/01/04の結果
- 16 vCPUインテル・インスタンスの設定をAMD 16 vCPUインスタンスと比較
- AWS EC2 MおよびRインスタンスで実行されたパフォーマンステスト。
- データベースのベンチマークでは、メモリ容量が大きいため、R5とR5aの比較を示しています。
最初のベンチマーク対決は、16個のvCPUクラスのインスタンス間です。
ベンチマークは、ICCコンパイラを使用してLinux 7.5で実行されています。
Intelのインスタンスは、Web / Java ワークロードの小さなリードと高性能演算 ワークロードの大幅なリードを持っています。
EPYCは2 x 128ビットのFMAを持ち、Skylake以上は2 x 512ビットのFMAを持っているという事実を考えるとこれは特に驚くべきことではありません。
※ FMA=積和演算命令のこと。積和演算とはコンピューターの演算処理で頻繁に処理される演算のこと。
ここで2つの注意点を述べたいと思います。
これらの例のいくつかは、サーバーサイドのもののように、GCCのような別のコンパイラを使用するとパフォーマンスが向上する可能性があり、広範囲の調整が必要になるため、NUMAにバインドされていません。
※ NUMA=プロセッサとメモリの対(これをノードと呼ぶ)が複数存在し、それらをインターコネクト(その詳細は問わない)で接続したもののこと。ノードをまたいだメモリへのアクセスは遅延することがある。Zenコアが採用している設計のことです。
それは広範囲の調整を必要とします。
パフォーマンス とは言っても、これらは高価な最適化ルートであり、サーバー側のデータのギャップを狭くする一方で(SPECのような他のベンチマークはすでにNUMAバインドされています)、Intelの同グレードインスタンスを上回るには不十分です。
- 2019/01/04の結果
- AWS EC2 MおよびRインスタンスで実行されたパフォーマンステスト。
- データベースのベンチマークでは、メモリ容量が大きいため、R5とR5aの比較を示しています。
- インスタンスのメモリ容量:m5.24xlarge and m5a.24xlarge:384GB,r5.24xlarge and r5a.24xlarge:768GB
同様の状況が96 vCPUインスタンスにも現れています。ここでも、Intelの対応物がAMDのものを支配しています。
HPCの違いはまた明らかですが、メモリ帯域幅は正規化されています。
- 96 vCPUインテル・インスタンスの性能/USドルをAMD 96 vCPUインスタンスと比較、16 vCPUインテル・インスタンスの性能/USドルをAMD 16 vCPUインスタンスと比較
- AWS EC2 MおよびRインスタンスで実行されたパフォーマンステスト。
- Perf / $の計算は、AWSインスタンスの標準価格設定-契約期間一年間前払い無し-($ / hr)に基づいています。
- データベースのベンチマークでは、メモリ容量が大きいため、R5とR5aの比較を示しています。
最後に、2019年1月12日の時点でのAWSの価格設定を使用した$比較あたりのパフォーマンスを示します。
これもまた相対的なものです。
平均して、Intelの同グレードインスタンスは、HPCを使用した場合、1.25倍から4.1倍までの範囲で、より高い価値を提供します。
これらのテストがここで言おうとしているのは、Intelのインスタンスがほとんどすべてのクラウドのユースケースにわたってより高い価値と絶対的なパフォーマンスの両方を提供するということです。
繰り返しになりますが、おそらく別のコンパイラを使用して専用のロード最適化(NUMAバインディングなど)を実行することでAMDの数値を少し上げることができますが、改善は根本的なハードウェアの違いを圧倒するには不十分です(MCM vs モノリシックおよびFMAの違いはHPCにとって非常に重要です。
これらの数字に基づいて、Intelはまだデータセンター市場を所有しているように見えます - そしてそれは大丈夫です - プロ/アマチュア/ビデオ市場はEPYCがIntel対応物のコストを考えると本当に輝くことができる市場だからです。
ソース:wccftech - First Look: Intel vs AMD EPYC AWS Cloud (IaaS) Benchmarks
![]()
![]()
解説:
EPYCとintelのサーバー向け最新システムのベンチマークの記事が出ていたので翻訳してみました。
結果は見ての通り、intelの圧勝です。
訳文は表現が難しすぎて意味不明に感じる人もいると思いますが、下手に意訳すると意味が違ってくる可能性があるのでわかりにくい表現でもそのままにしてあります。
これは主にFMAという積和演算の命令処理ユニットの性能の差とNUMAというRyzenが採用している設計方法のが原因です。
Ryzenの設計方法はコア数が簡単に増やせる代わりにメモリの速度に性能が左右されやすいという欠点があります。
NUMAとか最適化とかいう表現が出てきますが、これを理解するためにThreadripperを例に考えてみます。
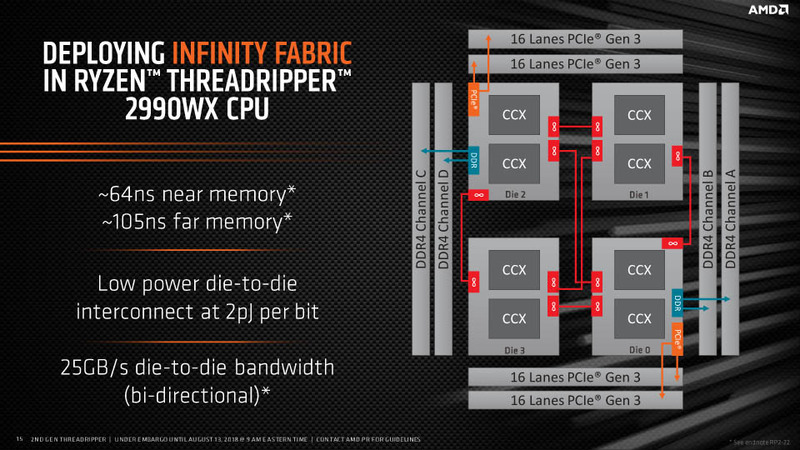
Threadripperは普通のRyzenが四つ組み合わされています。このうちメモリに直接つながっているのは上の画像から見てわかる通り、二つのコアだけです。
二つのコアがデュアルチャンネルのメモリとつながっていて(この組み合わせがノード)残りの二つはほかのコア経由でメモリにアクセスしています。
このほかのコア経由でメモリにアクセスするとペナルティ(?)が発生するというのがNUMAの特徴で高性能演算を行う場合はプログラムそのものを最適化する必要があるということです。
※ 表現的にはちょっとまずいところがあるかもしれませんが、まあ勘弁してください。
難しく書いてありますが、直接CPUコアにつながっていないメモリにアクセスするときは直接メモリにつながっているCPUコアと比べるとアクセスするのに時間がかかるということです。
厳密に表現するために「アクセスコストが均一ではない」とか「非対称性」とか難しい表現が使われていますが、言ってることは単純です。
※ ただし、最適化しても基本的な設計の違いによって差がついているFMA(積和演算命令)周りの処理はintelには追いつけないだろうということです。このFMAという奴はゲームにはほとんど影響を及ぼしませんので安心してください。(笑
じゃあなんで、AmazonはEPYCを採用したの?と疑問に感じる方もいると思います。
私もこの記事を読むまでは性能で勝っているからと思っていたのですが、おそらくですが、リスク分散のためとAMDを採用することによって独占市場となっているintelサーバーの導入コストを下げるためだと思います。
リスク分散に関してはintel CPUの脆弱性(Meltdown)が問題になったのが記憶に新しいです。
この問題は完全には解決していませんが、特定の会社のハードウェアに依存すると何かあったときに一気にダメになってしまう可能性があるので、一つの例ですが、そのためのリスク分散でしょう。
導入コストを下げる方は今nVidiaがGPUでやっているように、ライバルがいなければ基本的に言い値で買わされることになるのでその牽制のためでしょう。
どの市場でもライバルがいない製品の導入コストというのは高くなるものです。