目次
- あなたも感じているはずの「繰り返しの疲れ」
- 問題の本質:見えないコンテキストと蓄積されない知識
- 技術的背景:AIの「二重記憶」とその限界
- ブラウザの制約が生む壁
- 解決への第一歩:MCP(Model Context Protocol)
- MCPの本質:知識を外部化し、作業をオフロードする
- 現実的な期待値:「不完全な神様」との付き合い方
- 未来への展望:「完全な神様」への道
- まとめ:知識を資産に変える
1. あなたも感じているはずの「繰り返しの疲れ」
ChatGPTやClaudeといったAIアシスタントを使っていて、こんな経験はありませんか?
「また同じ説明をしている...」
1週間前:
あなた: 「プロジェクトの方針は○○で、
制約条件は△△で...」
AI: 「了解しました」
今日:
あなた: 「前回話した方針に基づいて提案して」
AI: 「申し訳ありませんが、その情報が見当たりません」
→ また最初から説明
結果:
→ 毎回、同じ説明を繰り返す
→ 知識が蓄積されない
→ 疲れる
「失敗から学べない」
先月:
あなた: 「この方法で進めよう」
AI: (実行)
結果: 失敗
今月:
あなた: 「提案して」
AI: 「この方法がいいと思います」
あなた: 「それ、前回失敗したやつ...」
結果:
→ 同じ失敗を繰り返す
→ 学習が蓄積されない
「毎回、徒手空拳」
作業のたびに:
1. ベストプラクティスを調べる
2. AIに説明する
3. 試行錯誤する
4. うまくいく方法を見つける
5. 終わる
次の作業:
→ また最初から
結果:
→ 知識が資産にならない
→ 効率が上がらない

これらの問題には、共通の原因があります。
AIが知識を蓄積できない。人間が毎回、徒手空拳で格闘している。
本記事では、この問題の技術的背景を解説し、それを解決する新しい技術「MCP(Model Context Protocol)」について、その本質と可能性を探ります。
2. 問題の本質:見えないコンテキストと蓄積されない知識
コンテキストウィンドウという制約
AIには「コンテキストウィンドウ」という制約があります。これは、AIが一度に処理できる情報の総量です。
想像してみてください。あなたが会話をしているとき、記憶できる内容には限界があります。AIも同じで、一度に扱える情報量には上限があります。
| AIモデル | コンテキストウィンドウ | 日本語換算 |
|---|---|---|
| Claude Sonnet 4.5 | 200,000 トークン | 約10万~20万文字 |
| GPT-4 | 128,000 トークン | 約6万~12万文字 |
| GPT-3.5 | 16,000 トークン | 約8千~1.6万文字 |
一見、十分な容量に見えます。しかし、このコンテキストウィンドウは、あなたの質問だけに使われるわけではありません。
コンテキストウィンドウの内訳
200,000 トークンのうち...
├ システムプロンプト: 3,000 トークン (1.5%)
│ → AIの基本的な動作ルール
│
├ 過去の会話: 60,000 トークン (30%)
│ → これまでのやり取り
│
├ あなたの質問: 20,000 トークン (10%)
│ → 今回の入力
│
├ AI の回答用: 60,000 トークン (30%)
│ → 出力のためのスペース
│
└ 空きスペース: 57,000 トークン (28.5%)
→ まだ余裕がある
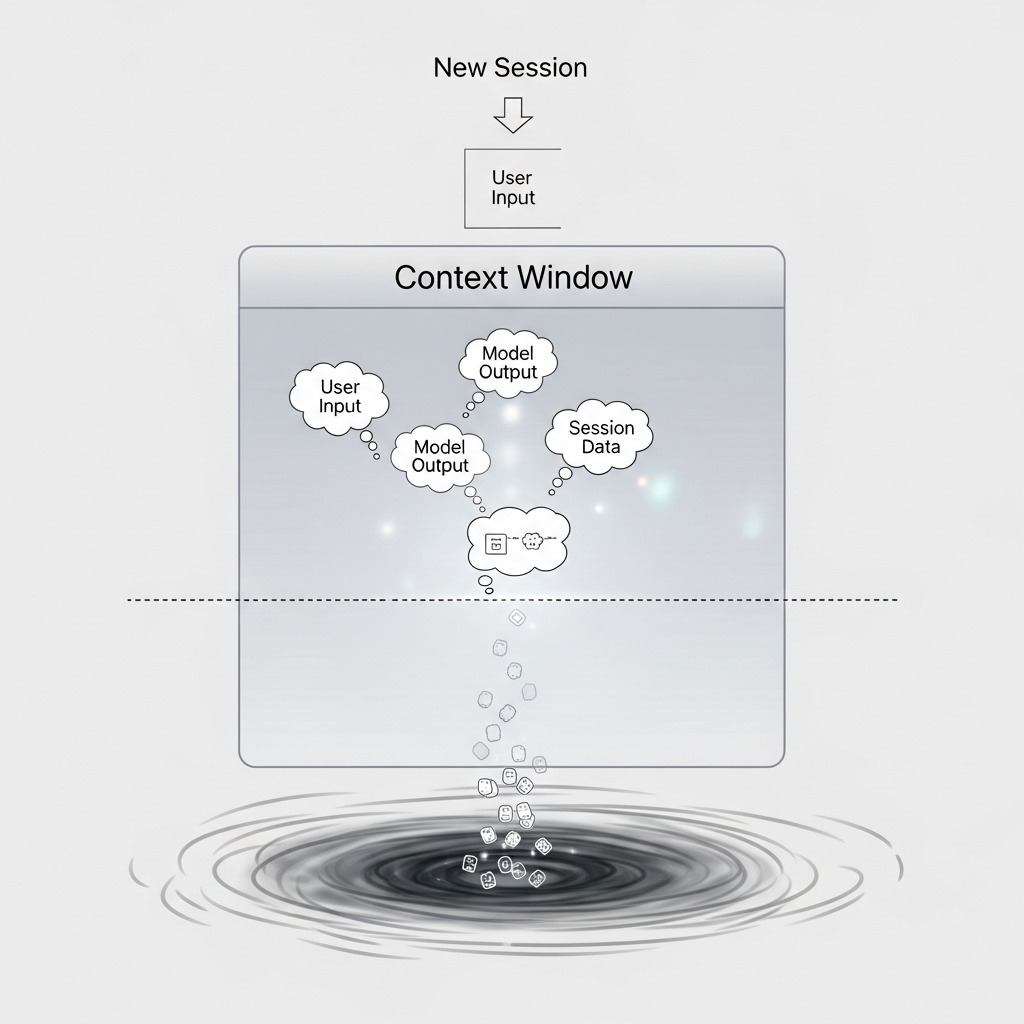
重要なのは、このコンテキストウィンドウがセッションごとにリセットされることです。
知識が蓄積されない仕組み
会話1(月曜日):
あなた: 「プロジェクトの方針を説明...」
AI: コンテキストに保存
↓
会話終了
↓
コンテキストクリア
会話2(水曜日):
あなた: 「前回の方針に基づいて...」
AI: 「前回の情報がありません」
↓
理由: コンテキストがリセットされたから
もちろん、AIサービスには「メモリ機能」や「過去チャット検索」がありますが、これらにも制約があります:
⚠️ 既存のメモリ機能の限界
✅ 自動要約:AIが勝手に要約する→重要な詳細が失われる
✅ 過去チャット検索:時間がかかる→リアルタイム性がない
✅ プロジェクト機能:ファイルをアップロード可能→でも参照が不透明
根本的な問題:ユーザーが制御できない
本当に必要なこと
私たちが本当に必要としているのは:
理想の状態:
✅ 知識をファイルとして保存
✅ 必要な時に明示的に参照
✅ ユーザーが内容を確認・編集できる
✅ チーム内で共有可能
✅ 長期的に蓄積
つまり:
「知識を資産化する」
これを実現するのが、MCPです。しかし、その前に、なぜこれまで実現できなかったのかを理解する必要があります。
3. 技術的背景:AIの「二重記憶」とその限界
実は、AIは2種類の記憶システムを使っています。これを理解すると、なぜ「思い出すのに時間がかかる」のかが分かります。
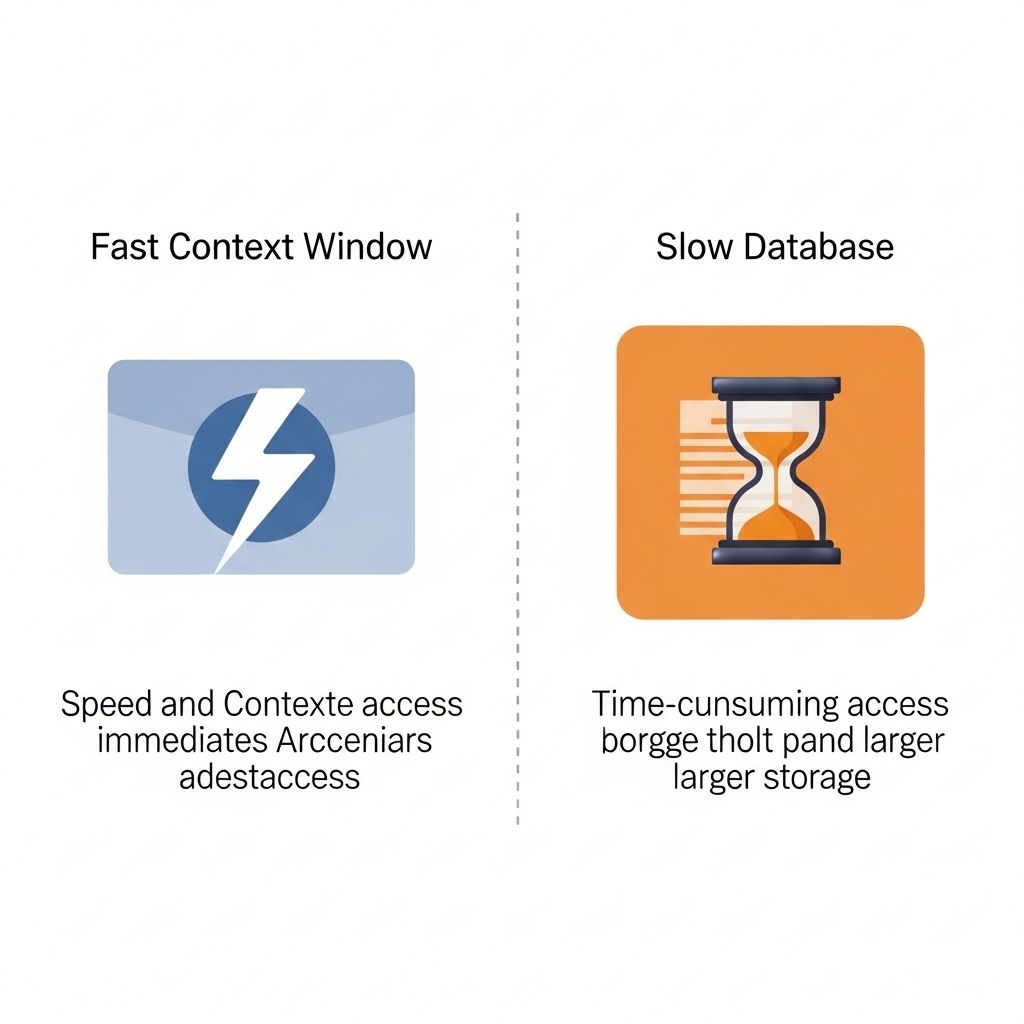
AIの二重記憶システム
【システム1:短期記憶(コンテキストウィンドウ)】
容量: 200,000 トークン(Claudeの場合)
場所: AIのメモリ内
速度: 瞬時
用途: 現在の会話
【システム2:長期記憶(データベース)】
容量: ほぼ無制限
場所: クラウドのデータベース
速度: 遅い(検索が必要)
用途: 過去の会話の保存
タイムラグの正体
過去の会話を参照するとき、こんな流れになっています:
あなた: 「前に話した○○について教えて」
↓
AI: この情報は短期記憶(コンテキスト)にない
↓
長期記憶(データベース)を検索
↓
【ここでタイムラグ】
↓
検索結果をコンテキストに挿入
↓
AI: 「はい、覚えています...」
このタイムラグは、検索処理の時間です。そして、ここに重要な問題があります。
「読み捨て」の真実
多くの人は、こう考えています:
誤解:
「コンテキストから溢れた会話は忘れられる」
実際:
「コンテキストから消えても、
データベースには残っている」
つまり、完全に忘れられるわけではなく、別の場所に保管されているのです。
しかし、ここに問題があります:
❌ ユーザーから見えないもの
・どの情報がコンテキスト内にあるか
・どの情報がデータベースにあるか
・検索が実行されているか
・何が見つかって、何が見つからなかったか
すべてがブラックボックス
根本的な課題
この二重記憶システムは、技術的には合理的な設計です。しかし:
課題1: 透明性の欠如
→ 何が起こっているか見えない
課題2: 制御不能
→ ユーザーが管理できない
課題3: 知識の非蓄積
→ セッションをまたいで活用できない
これらの課題を解決するには、根本的に異なるアプローチが必要です。
4. ブラウザの制約が生む壁
「AIが自動的にファイルに保存してくれたら便利なのに」
そう思ったことはありませんか? しかし、現在のブラウザ版AIサービスでは、これができません。
ブラウザサンドボックスという防護壁
Webブラウザには「サンドボックス」という仕組みがあります。これは、Webサイトがあなたのパソコンを勝手に操作できないようにする安全装置です。
サンドボックスの役割:
インターネット
↓
Webサイト(AIチャット)
↓
ブラウザのサンドボックス
┌─────────────────┐
│ ここで実行 │
│ 外には出られない│
└─────────────────┘
↓ ❌ 遮断
あなたのパソコン
├ ファイル
├ 写真
├ 文書
└ 個人情報

なぜこの制約があるのか
もしWebサイトが自由にファイルを読み書きできたら:
悪意のあるサイトができること:
❌ あなたの写真をすべて盗む
❌ 重要な文書を削除
❌ ウイルスをインストール
❌ パスワードを盗む
このようなセキュリティリスクを防ぐため、ブラウザは厳格な制約を課しています。
しかし、この制約が、善良なAIサービスにとっても壁となっています:
AIサービスができないこと:
❌ ローカルファイルの作成
❌ 自動的な知識の保存
❌ ファイルベースの知識管理
💡 重要な理解
ブラウザの制約は「技術的限界」ではなく
「セキュリティのための意図的な設計」
→ 悪意のあるサイトからユーザーを守るため
→ しかし、善良なサービスも制約を受ける
→ これが知識の蓄積を難しくしている
この壁を越えるために、新しいアプローチが必要でした。それがMCPです。
5. 解決への第一歩:MCP(Model Context Protocol)
MCPとは何か
MCP(Model Context Protocol)は、2024年11月にAnthropic(Claudeを開発している会社)が発表した、AIが外部システムと安全に通信するための標準規格です。
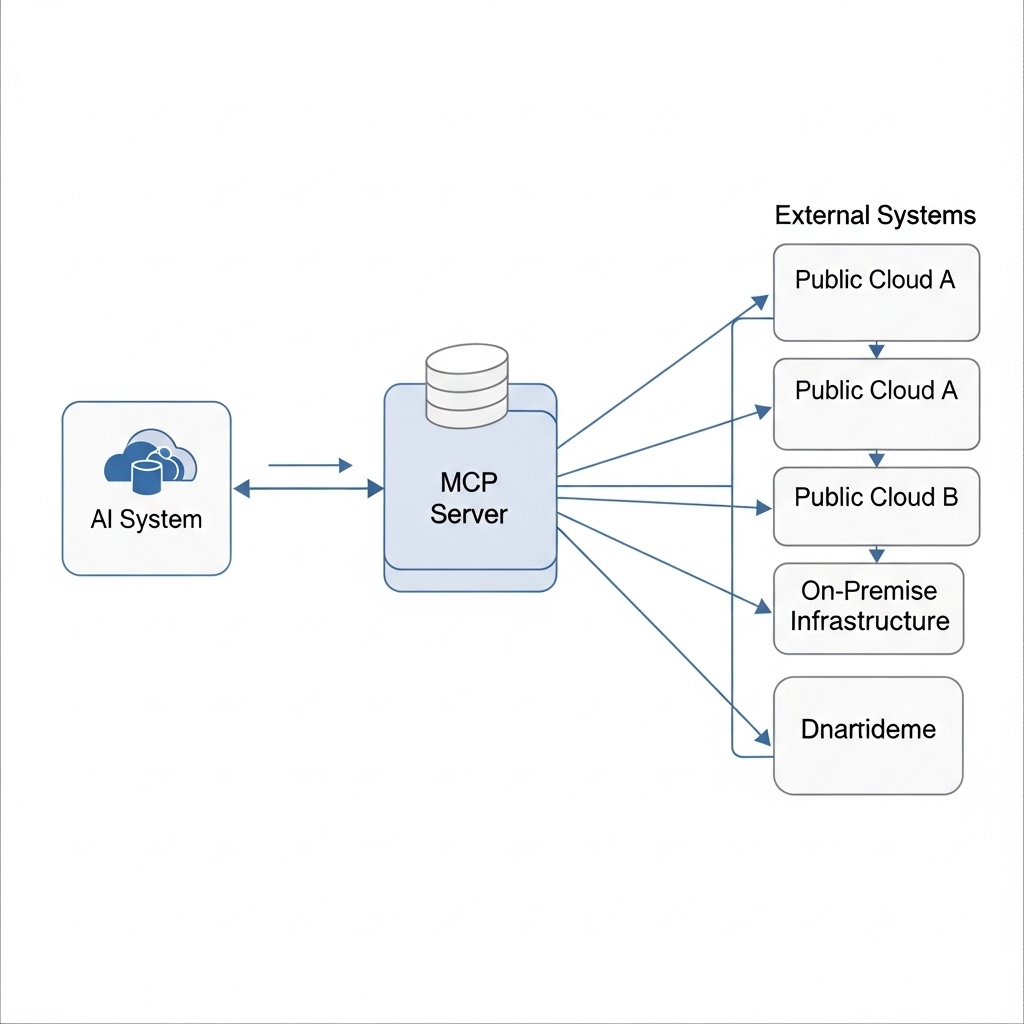
MCPの役割:
AI(Claude、ChatGPTなど)
↓
MCPプロトコル(共通規格)
↓
MCPサーバー(ローカルプログラム)
↓
外部システム
├ ファイルシステム ← 重要!
├ データベース
├ 外部API
└ その他のツール
ブラウザ制約の回避
MCPの革新的な点は、ブラウザの外で動くプログラムを経由することです:
従来:
ブラウザ版AI
↓ ❌ 遮断
ローカルファイル
MCP使用:
ブラウザ版AI
↓
MCP経由で外部プログラムに指示
↓
外部プログラム(サンドボックスの外)
↓ ✅ アクセス可能
ローカルファイル
これにより、AIがファイルを作成・読み取り・更新できるようになります。
基本的な使用例
あなた: 「今日の会議メモをファイルに保存して」
AI (Claude):
1. MCPサーバーに接続
2. ファイル作成を指示
3. 会議メモの内容を送信
結果:
→ meeting_notes_20250101.txt が作成される
後日:
あなた: 「前回の会議メモを参照して、次の議題を提案して」
AI:
1. MCPサーバー経由でファイルを読み込む
2. その内容に基づいて提案
→ 知識が蓄積され、活用される
これだけでも十分便利です。しかし、MCPの本当の価値は、ここから始まります。
6. MCPの本質:知識を外部化し、作業をオフロードする
MCPの本当の価値は、人間の知識と経験をファイルに蓄積し、AIに作業をオフロードできることです。
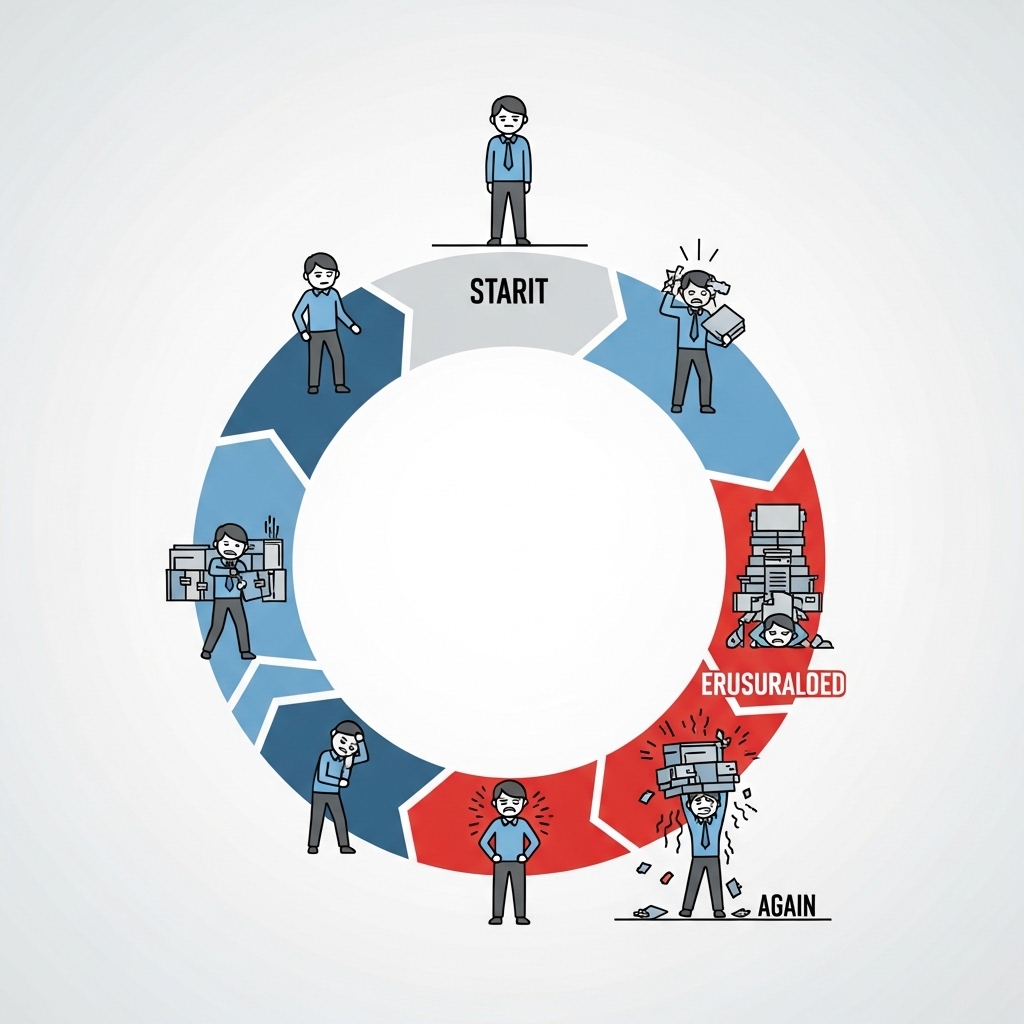
従来のサイクル
どんな作業にも、こういうサイクルがあります:
1. 調べる
→ ベストプラクティスを学ぶ
2. 試す
→ 実際にやってみる
3. 失敗する
→ うまくいかない
4. 学ぶ
→ 何が悪かったか理解
5. 改善する
→ 次はもっとうまくやる
そして...
6. 忘れる
→ 数週間後、また最初から
→ この繰り返し
MCPが変えるサイクル
MCPは、このサイクルを根本的に変えます:
1. 調べる
→ ベストプラクティスを学ぶ
→ ★ファイルに保存★
2. 試す
→ ★AIがファイルを参照して実行★
3. 失敗する
→ ★失敗例もファイルに記録★
4. 学ぶ
→ ★学びをファイルに追記★
5. 改善する
→ ★AIが更新されたファイルを参照★
そして...
6. 蓄積される
→ ★知識が消えない★
→ ★次回から自動的に活用★
→ 知識が資産になる
蓄積できる知識の種類
MCPで外部化できる知識は、多岐にわたります:
| 知識の種類 | 具体例 | ファイル名の例 |
|---|---|---|
| 手順書 | 特定のタスクの進め方 | deployment_procedure.md |
| ベストプラクティス | 効果的な方法論 | writing_guidelines.md |
| 失敗例 | 避けるべきパターン | common_mistakes.md |
| 判断基準 | 意思決定のルール | decision_criteria.md |
| テンプレート | 繰り返し使う雛形 | email_templates.md |
| 制約条件 | 守るべきルール | constraints.md |
ユースケース1:技術文書の作成
シナリオ:
定期的に技術ドキュメントを書く必要がある
準備:
documentation_guide.md を作成
├ 推奨される構成
├ 使うべき用語
├ 避けるべき表現
├ 過去の良い例
└ 過去の悪い例
使用:
あなた: 「新機能のドキュメントを書いて」
AI:
1. documentation_guide.md を参照
2. 推奨構成に従って作成
3. 適切な用語を使用
4. 悪い例を回避
結果:
✅ 一貫性のあるドキュメント
✅ 毎回の説明不要
✅ 品質が安定
✅ 時間短縮
ユースケース2:顧客対応
シナリオ:
顧客とのやり取りが多い
準備:
customer_interaction/
├ response_templates.md ← 返信テンプレート
├ tone_guidelines.md ← トーンガイドライン
├ faq.md ← よくある質問
└ escalation_criteria.md ← エスカレーション基準
使用:
あなた: 「顧客Aから問い合わせ。返信案を作って」
AI:
1. tone_guidelines.md でトーン確認
2. faq.md で類似ケース検索
3. response_templates.md でテンプレート選択
4. escalation_criteria.md で判断
5. 返信文を生成
あなた:
→ 内容を確認・微調整
→ 送信
結果:
✅ ブランドイメージ維持
✅ 対応品質の均一化
✅ 初期対応の自動化
✅ エスカレーション判断の支援
ユースケース3:外部サービスの活用
これは特に重要な例です。
シナリオ:
複雑な外部サービスのAPIを使う必要がある
(例:動画生成、画像生成、データ分析ツールなど)
準備:
external_service_guide/
├ api_overview.md ← API全体像
├ best_practices.md ← 効果的な使い方
├ common_patterns.md ← よく使うパターン
├ error_handling.md ← エラー対処法
└ cost_optimization.md ← コスト最適化
使用:
あなた: 「このサービスを使って○○を作って」
AI:
1. api_overview.md で全体像把握
2. best_practices.md でベストプラクティス確認
3. common_patterns.md で適切なパターン選択
4. 実装を提案
実行後、うまくいかない:
あなた: 「エラーが出た」
AI:
1. error_handling.md を参照
2. 類似エラーの対処法を検索
3. 解決策を提案
4. 今回の対処もerror_handling.mdに追記
結果:
✅ 使い方を毎回調べなくていい
✅ エラー対処が迅速
✅ 知識が蓄積
✅ チーム内で共有可能
注: 上記は一般的なパターンです。動画生成AI、画像生成AI、データ分析ツール、翻訳サービスなど、どんな外部サービスにも応用できます。

前提の可視化
MCPのもう一つの重要な価値は、「AIが何を基準に判断しているか」が見えることです。
従来:
あなた: 「提案して」
AI: 「Aがいいと思います」
あなた: 「なぜ?何を基準に?」
→ 分からない(ブラックボックス)
MCP使用:
あなた: 「提案して」
AI: 「project_guidelines.md の
『シンプルさ優先』という方針に基づき、
Aを推奨します」
あなた: 「ああ、そのファイルね」
「じゃあ、そのファイルを修正しよう」
→ 透明(制御可能)
これは、単なる便利機能ではありません。判断の透明性という、極めて重要な価値です。
🎯 MCPの本質的な価値
1. 知識の蓄積
→ ファイルに保存され、消えない
2. 作業のオフロード
→ AIが代わりに参照・実行
3. 判断の透明性
→ 何を基準にしているか見える
4. 制御可能性
→ ユーザーがファイルを管理
→ これが「徒手空拳」から「知識資産活用」への転換
あなたの場合は?
ここまでの例を読んで、こう考えてみてください:
問いかけ:
1. あなたが繰り返しやっている作業は?
2. そこにはベストプラクティスがある?
3. 過去の失敗から学んだことは?
4. チーム内で共有すべき知識は?
5. 複雑な外部サービスを使っている?
これらすべて、MCPで外部化できます。
重要なのは、具体的なツールやサービス名ではなく、「知識を外部化する」という考え方です。
あなたの仕事、あなたの状況に合わせて、MCPをどう活用できるか想像してみてください。
7. 現実的な期待値:「不完全な神様」との付き合い方
ここまで読んで、「MCPで完全自動化できる!」と思ったかもしれません。
しかし、重要な現実をお伝えする必要があります。
AIは「不完全な神様」
現実:
MCPで作業をオフロードできる
でも:
❌ 完全自動ではない
❌ AIは間違える
❌ 予期しない結果が出る
❌ 人間の監督が必要
これは、すべてのAIサービスに共通する現実です:
チャット型AI:
❌ 誤解することがある
❌ ハルシネーション(幻覚)を起こす
❌ 文脈を見失うことがある
動画生成AI:
❌ 指示通りに動かないことがある
❌ 予期しない結果が出る
❌ 細かい調整が必要
画像生成AI:
❌ 意図と異なる出力
❌ 品質のばらつき
❌ 試行錯誤が必要
共通点:
→ AIは「不完全な神様」
→ 完璧ではない
現実的なワークフロー
MCPを使った場合の現実的な作業フローは、こうなります:
ステップ1: AIが下書きを作成
あなた: 「技術ドキュメントを書いて」
AI: マニュアルを参照して生成
↓
★ここで人間が確認★
ステップ2: 人間がレビュー・修正
あなた: 内容を確認
→ 80%は良い
→ 20%は調整が必要
→ 修正
ステップ3: 完成
↓
必要なら、マニュアルも更新
結果:
✅ 80%の作業を自動化
✅ 20%は人間が調整
✅ でも、徒手空拳よりは遥かに速い
期待値の設定
❌ 非現実的な期待:
「AIが完全に自動でやってくれる」
「人間は何もしなくていい」
✅ 現実的な期待:
「AIが80%やってくれる」
「人間は20%の確認・調整をする」
「でも、それでも大幅な時間短縮」
具体例:
従来: 2時間かかる作業
MCP使用:
- AI作業: 15分
- 人間確認: 25分
- 合計: 40分
→ 60%の時間短縮
⚠️ 重要な理解
MCPは「完全自動化」の技術ではない
MCPは「知識資産化」の技術
✅ 知識を蓄積できる
✅ 作業を大幅に効率化できる
✅ でも、人間の監督は必要
→ これが「不完全な神様」との正しい付き合い方
費用対効果
外部サービスのAPIを活用する場合、コストも考慮する必要があります:
例:動画生成サービスの場合
必要なコスト:
- API利用料(1回 数百円~数千円)
- 試行錯誤のコスト
- 失敗した生成物の費用
初期段階:
試行錯誤でノウハウ蓄積
→ コストがかかる
でも、一度蓄積すれば:
マニュアルを参照するだけ
→ 失敗が減る
→ コスト削減
→ 効率向上
長期的には:
✅ 投資回収可能
✅ チーム内で共有
✅ 組織の資産に
注: 実際の検証には相当なコストがかかるため、費用対効果を慎重に検討する必要があります。
8. 未来への展望:「完全な神様」への道
現在のAIは「不完全な神様」です。しかし、技術は進化し続けています。
技術進化の予測
2025年(現在):
「動画を作って」
→ AIがマニュアル参照
→ プロンプト生成
→ API実行
→ 人間が最終確認・調整(20%の作業)
2028年(近未来):
「動画を作って」
→ AIが完全自動実行
→ 人間は軽い確認のみ(5%の作業)
2030年(予測):
「動画を作って」
→ AIが完全自動実行
→ 人間の確認すら不要になる可能性
2035年(展望):
「キャンペーンを実施」
→ 動画・画像・テキスト全自動生成
→ SNS投稿まで自動
→ 人間は戦略だけ考える
なぜ進化すると言えるのか
技術の進化には、明確なパターンがあります:
歴史的パターン:
1990年代: 音声認識
→ 不正確、使えない
→ 2020年代: ほぼ完璧
2000年代: 機械翻訳
→ 意味不明、使えない
→ 2020年代: 実用レベル
2010年代: 自動運転
→ 実験段階
→ 2020年代: 限定的に実用化
2020年代前半: 画像生成AI
→ 不自然、指示通りにならない
→ 2020年代後半: 驚くほど改善
共通点:
→ 最初は「不完全」
→ でも確実に進化
→ いつか「完全」に近づく
MCPの役割
この進化の過程で、MCPは重要な役割を果たします:
MCPの価値(時間軸):
現在:
知識を蓄積する仕組み
→ 人間が監督
近未来:
蓄積された知識をAIが活用
→ 監督が減る
遠い未来:
膨大な知識資産
→ AIが完全自動化
つまり:
MCPで蓄積した知識は、
将来の「完全な神様」の基礎になる
💡 長期的な視点
今、MCPで知識を蓄積することは:
✅ 現在:作業効率化の手段
✅ 近未来:自動化の基盤
✅ 遠い未来:完全自動化への橋渡し
→ 早く始めるほど、長期的な価値が大きい
規制と社会受容の進化
技術だけでなく、社会も進化します:
インターネット決済の例:
1990年代:
「クレジットカードをネットに入れるな!」
→ 誰も使わない
2000年代:
SSL/TLS、3Dセキュア
→ 徐々に普及
2010年代:
トークン化、生体認証
→ 広く普及
2025年:
ほぼすべての人が利用
→ 当たり前
同様に、AIの自動化も:
現在: 慎重
→ 技術成熟
→ 規制最適化
→ 社会受容
→ 未来: 当たり前
9. まとめ:知識を資産に変える
問題の本質
従来の課題:
❌ 毎回、同じ説明を繰り返す
❌ 知識が蓄積されない
❌ 失敗から学べない
❌ 徒手空拳で格闘
根本原因:
→ コンテキストウィンドウの制約
→ セッションのリセット
→ ブラウザの制約
MCPによる解決
MCPが可能にすること:
✅ 知識をファイルに保存
✅ AIが参照して実行
✅ 判断基準が見える
✅ ユーザーが制御できる
✅ チーム内で共有可能
✅ 長期的に蓄積
結果:
→ 知識が資産になる
→ 作業がオフロードされる
→ 効率が上がる

現実的な理解
重要な認識:
AIは「不完全な神様」
✅ 80%の作業を自動化
✅ 20%は人間が調整
✅ でも、徒手空拳よりは遥かにマシ
未来への期待:
いつかは「完全な神様」に
→ その基礎を今、築く
実践へのステップ
今日からできること:
ステップ1: 小さく始める
→ よく使う手順をファイル化
ステップ2: 試してみる
→ AIに参照させて実行
ステップ3: 改善する
→ うまくいかない部分を修正
ステップ4: 蓄積する
→ 新しい知識を追加
ステップ5: 共有する
→ チームで活用
→ 知識が資産になる
最後に
「知識を蓄積する」
この単純な行為が、
AIとの付き合い方を根本的に変えます。
毎回、徒手空拳で格闘するのではなく、
過去の経験を資産として活用する。
これが、MCPが可能にする未来です。
🚀 未来は、もう始まっている
MCPは、まだ発展途上の技術です。
完璧ではありません。
でも、それは「完全な神様」への第一歩です。
そして、その一歩を今、踏み出すことができます。
あなたの知識を、資産に変えてみませんか?
参考資料
公式ドキュメント
技術記事
コミュニティ
いかがでしたか?
私が一番不満に思っていた「使用されるコンテキストの不明瞭さ」という問題を解決するのに自動生成した基礎知識となるテキストファイルを用いるという方法を思いついて、その具体的手段としてローカルのMCPサーバーを建てるという提案をされました。
私は買ってから使ってなかったRaspberry Pi5がたまたまありましたのでローカルMCPサーバーを建てるという方法論が採れましたが、そうでない人たちはまた別の方法の方が手軽かもしれません。
いずれにしてもAIが使うプロトコルが整備されれば将来的に解決していく問題だとは思います。
AIによるファイルの生成と参照が出来れば、例えばSora2のプロンプトガイドをテキストにまとめAPIを叩く時に必ず参照するというようなこともできるようです。
※ 当然APIによるSora2の利用契約は必要です。
この記事はその時のやり取りを記事としてまとめたものです。
これが出来れば動画生成や画像生成機能のないclaudeにも動画生成や画像生成の機能を持たせることができるようです。
うまく行くかはわかりませんが、成功したら改めて報告させていただきます。