
NVIDIAのフラッグシップGPUであるGeForce RTX 5090とRTX PRO 6000に、仮想化環境下での無応答化という新たなバグが発生したようです。
NVIDIAのフラッグシップBlackwell GPU、VMの大量使用後に「無応答」に
開発者向けGPUクラウドであるCloudRiftは、NVIDIAのハイエンドGPUのクラッシュ問題を最初に報告しました。
同社によると、対象SKUが「数日間」VM使用状態になった後、完全に無応答になり始めたとのことです。
興味深いことに、ノードシステムを再起動しない限り、GPUにアクセスできなくなりました。
この問題はRTX 5090とRTX PRO 6000に特有のもので、RTX 4090、Hopper H100、BlackwellベースのB200などのモデルは現時点では影響を受けていないとのことです。
この問題は、デバイスドライバーのVFIOを使用してGPUをVM環境に割り当て、Function Level Reset(FLR)後にGPUが全く応答しなくなる場合に発生します。
この無応答状態によりカーネルの「ソフトロック」が発生し、ホスト環境とクライアント環境がデッドロック状態に陥ります。
この状態から抜け出すにはホストマシンを再起動する必要がありますが、CloudRiftのゲストマシンの規模を考えると、これは困難な手順です。
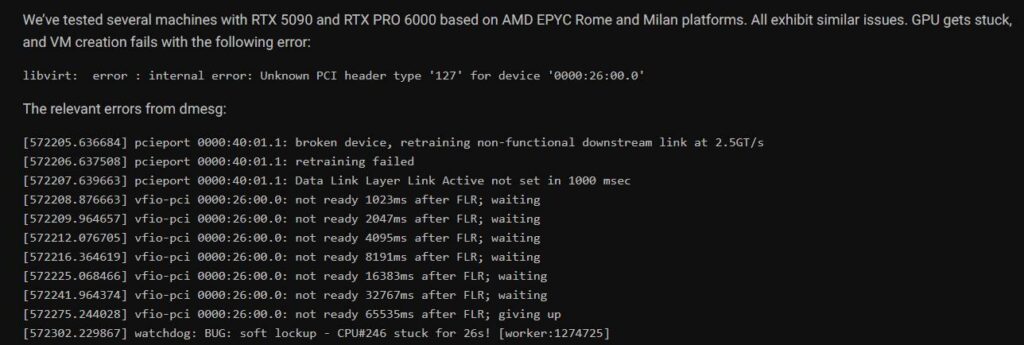
この問題はCloudRiftに限ったものではありません。Proxmoxのユーザーも同様の問題を報告しており、Windowsクライアントをシャットダウンした後にホストが完全にクラッシュしたとのことです。
興味深いことに、NVIDIAはこの問題に対応し、問題を再現できており修正に取り組んでいると述べています。
NVIDIAからの正式な確認を待っていますが、この問題はBlackwellベースのGPUに特有のもののようです。
興味深いことに、CloudRiftは問題を修正または軽減できる人に1,000ドルのバグ修正報奨金を出しており、重要なAIワークロードに影響を与えていることを考えると、NVIDIAがすぐに修正プログラムをリリースすると予想されます。
解説:
Blackwellにまた問題が見つかる。
ただ、一般の人にはあまり関係ありません。
影響を受けるのはRTX5090とRTX Pro 6000のみで仮想化環境で使っていると再起動しないといけなくなるバグがあるようです。
こちらは元記事にもありますが、環境によっては解決が非常に困難です。
中国はRTX5090を大量に集めてチップを抜いて新しく設計したPCBにメモリを128GB盛ってサーバー用GPUとして再利用していますので、かなり大問題ではないですかね(苦笑。
NVIDIAは修正に取り組んでいるのでいずれ解決するかもしれませんね。
一般人にとってはあまり関係のない問題ですが、イメージ的にはちょっと良くないと思います。