
NVIDIA GeForce RTX 4090は、次世代BFGPUとして登場し、ゲームを次のレベルに引き上げる、圧倒的なパフォーマンスを提供します。
GeForce RTX 4090は、単なるGPUではなく、グリーンチームのフラッグシップであり、旧モデルの4倍の性能向上を実現しています。
NVIDIAは、地球上で最も高速なGPUを搭載した次世代GeForce RTX 4090 BFGPUで、ゲームを次のレベルへ進化させます。
NVIDIAのGeForce RTX 4090は、長い間待ち望まれていましたが、ついに登場しました。
このグラフィックスカードは、最高のビジュアル忠実度を求めるエンスージアストやゲーマーのために設計されており、次世代AAAタイトルの要求がいかに高くなっているかを考えると、それを達成するには、強力なGPUが必要です。
このことを念頭に置いて、NVIDIAは次のチップを前世代より数パーセントや50%速くするのではなく、DLSSで4倍、ネイティブ解像度で2倍速くし、グラフィックカードが今後のタイトルに対応するだけではなく、レイトレーシングなどの拡張機能にも対応できるようにしたのです。
NVIDIAは、地球上で最も高速なGPUを搭載した次世代GeForce RTX 4090 BFGPUで、ゲームを次のレベルへ進化させます。
NVIDIAのGeForce RTX 4090は、長い間待ち望まれていましたが、ついに登場しました。
このグラフィックスカードは、最高のビジュアル忠実度を求めるエンスージアストやゲーマーのために設計されており、次世代AAAタイトルの要求がいかに高くなっているかを考えると、それを達成するには、強力なGPUが必要です。
このことを念頭に置いて、NVIDIAは次のチップを前世代より数パーセントや50%速くするのではなく、DLSSで4倍、ネイティブ解像度で2倍速くし、グラフィックカードが今後のタイトルに対応するだけではなく、レイトレーシングなどの拡張機能にも対応できるようにしたのです。
※ 画像をクリックすると別Window・タブで拡大します。
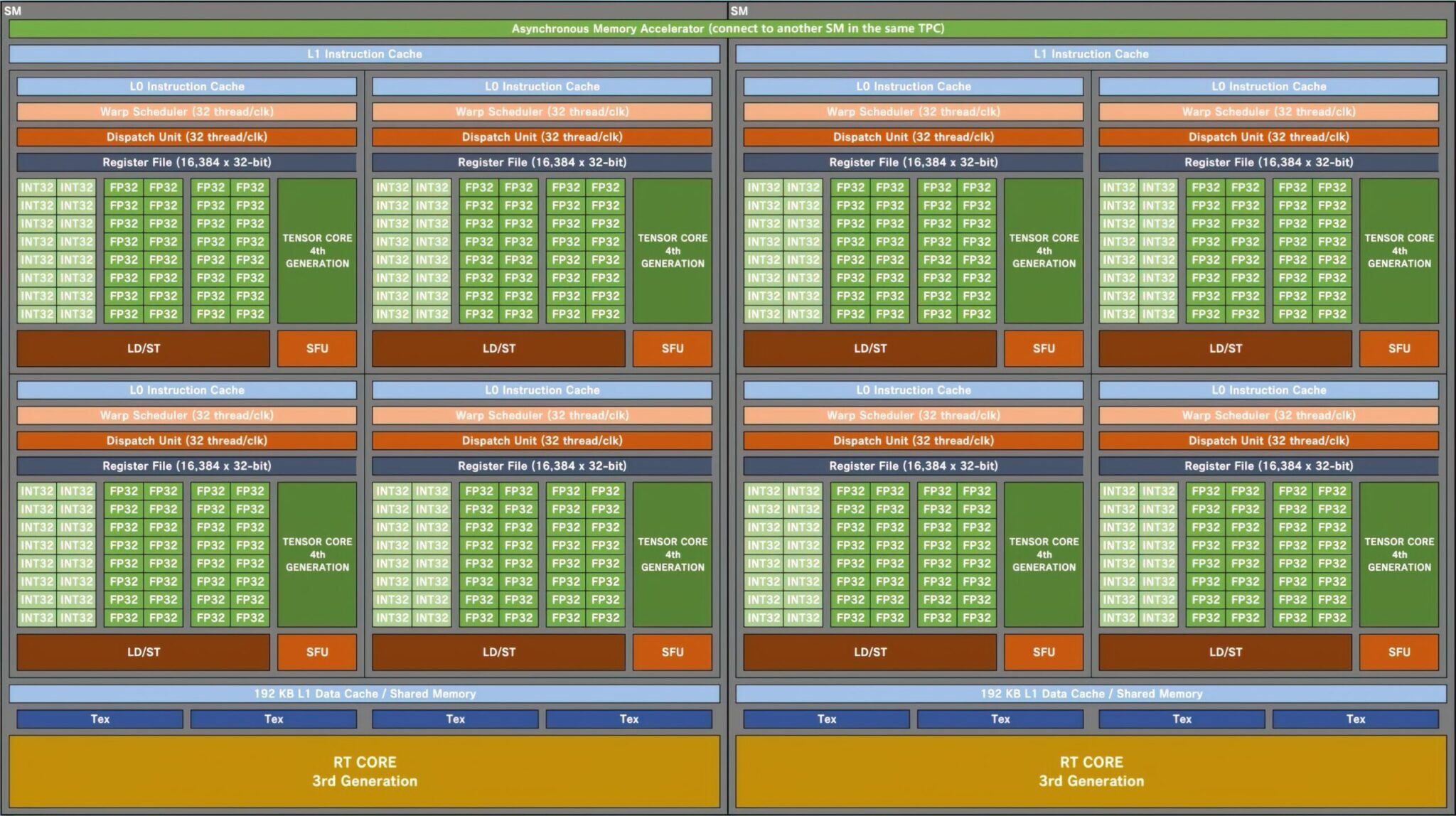
NVIDIA Ada Lovelace AD103 GPUは、最大7 GPC(Graphics Processing Clusters)を搭載する見込みです。
これはAmpere GA102 GPUと同じGPC数で、GA103 GPUよりGPCが1つ多い。
各GPUは、6つのTPCと2つのSMで構成され、これは従来のチップと同じ構成です。各SM(Streaming Multiprocessor)には4つのサブコアが搭載されますが、これもGA102 GPUと同じです。
変更点は、FP32とINT32のコア構成です。
各サブコアには128個のFP32が搭載されるが、FP32+INT32を合わせると最大192個になる。
これは、FP32ユニットがIN32ユニットと同じサブコアを共有しないためだ。128個のFP32コアは、64個のINT32コアとは別になっている。
つまり、各サブコアは、FP32ユニット32個とINT32ユニット16個、合計48個で構成されることになる。
各SMは、FP32ユニット128個とINT32ユニット64個、計192個を搭載することになる。そして、SMは合計84基(GPCあたり12基)あるので、FP32ユニット12,288基、INT32ユニット6,144基、合計18,432基のコアがあることになる。また、各SMには2つのWrap Schedules(32スレッド/CLK)が含まれ、SMあたり64ラップになります。これはGA102 GPUと比較して、コア数(FP32+INT32)で50%、Wraps/Threadsで33%増加したことになる。
NVIDIA AD102 'Ada Lovelace' ゲーミング GPU 'SM' ブロックダイアグラム(ソース:Kopite7kimi):
※ 画像をクリックすると別Window・タブで拡大します。
| GPU名 | AD102 | GA102 | TU102 | GA100 | GH100 |
| GPC | 12 (GPU毎) | 1.7x | 2x | 1.5x | 1.5x |
| TPC | 6 (GPC毎) | AD102に同じ | AD102に同じ | 0.75x | 0.67x |
| SM | 2 (TPC毎) | AD102に同じ | AD102に同じ | AD102に同じ | AD102に同じ |
| Sub-Core | 4 (SM毎) | AD102に同じ | AD102に同じ | AD102に同じ | AD102に同じ |
| FP32 | 128 (SM毎) | AD102に同じ | 2x | 2x | AD102に同じ |
| FP32+INT32 | 192 (SM毎) | 1.5x | 1.5x | 1.5x | AD102に同じ |
| Warps | 64 (SM毎) | 1.33x | 2x | AD102に同じ | AD102に同じ |
| Threads | 2048 (SM毎) | 1.33x | 2x | AD102に同じ | AD102に同じ |
| L1 Cache | 192 KB (SM毎) | 1.5x | 2x | AD102に同じ | 0.75x |
| L2 Cache | 96 MB (GPU毎) | 16x | 16x | 2.4x | 1.6x |
| ROP数 | 32 (Per GPC) | 2x | 2x | 2x | 2x |
キャッシュに話を移すと、ここもNVIDIAが既存のAmpere GPUに対して大きなブーストをかけた部分である。
Ada Lovelace GPUは、SMあたり192KBのL1キャッシュを搭載し、Ampereから50%増となる。
これは、トップのAD102 GPUでは、合計4.5MBのL1キャッシュを搭載することになる。
L2キャッシュは、リークにあるように96MBに増量される。
これは、6MBのL2キャッシュを搭載するAmpere GPUの16倍に相当する。このキャッシュは、GPU全体で共有される。
最後に、ROPですが、これも1GPCあたり32個に増え、Ampereの2倍になっています。
Ampereの最速GPUであるRTX 3090 Tiでは112個しかないROPが、次世代フラッグシップでは最大で384個になるわけです。
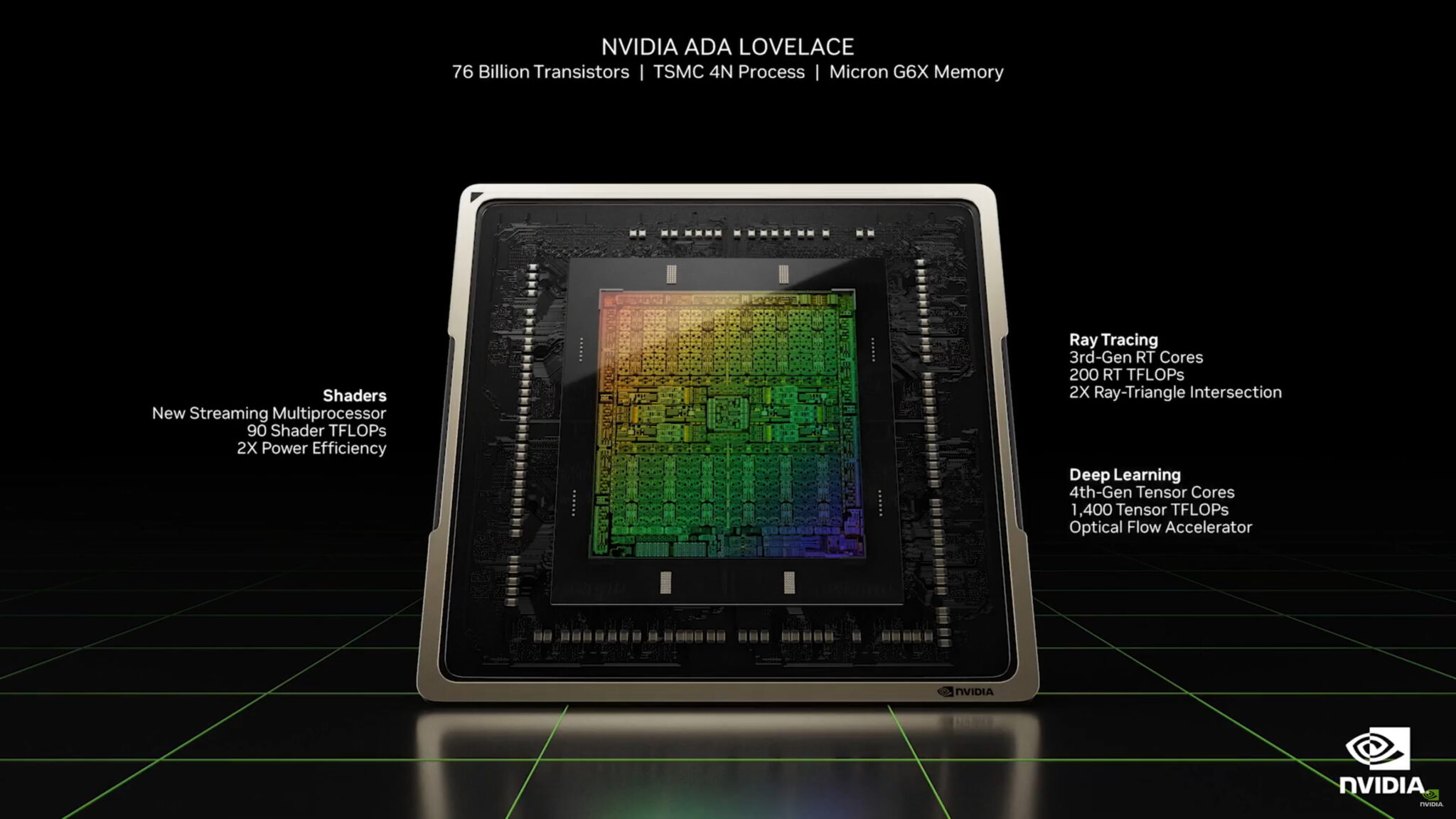
また、Ada Lovelace GPUには、最新の第4世代Tensorコアと第3世代RT(Raytracing)コアが搭載されており、DLSSとRaytracingのパフォーマンスを次のレベルに引き上げるのに役立ちます。
Ada Lovelace AD102 GPUは、次のような特徴を備えています。
- 2x GPCs (対Ampere)
- 50%増のコア(対Ampere)
- 50%増のL1キャッシュ(対Ampere)
- 16倍のL2キャッシュ(対Ampere)
- ROPsが2倍(対Ampere)
- 第4世代Tensorコアと第3世代RTコア
NVIDIA GeForce RTX 4090の「公式」スペック
NVIDIA GeForce RTX 4090は、144個のSMのうち128個のSMを使用し、合計16,384個のCUDAコアを搭載する予定です。
96MBのL2キャッシュと合計384個のROPを搭載し、まさに狂気のGPUとなるが、RTX 4090がカットダウンデザインであることを考えると、L2やROP数が若干少なくなる可能性がある。
クロックスピードはまだ確定していないが、TSMC 4Nプロセスが採用されていることを考慮すると。クロック速度は最大2.6GHzとされており、NVIDIAはオーバークロックで3GHz以上の速度を主張していますが、これについてはこちらで詳しく解説しています。
メモリのスペックとしては、GeForce RTX 4090は24GBのGDDR6X容量を搭載し、384bitバスインターフェイスで21Gbpsの速度でクロックアップされる予定です。
これにより、最大で1TB/sの帯域幅を実現します。これは既存のRTX 3090 Tiグラフィックスカードと同じ帯域幅で、消費電力に関しては、TBPは450Wの定格となっている。
カードは、最大600Wの電力を供給する16ピンコネクタ1個で駆動する予定です。カスタムモデルでは、より高いTBPのターゲットが提供される予定です。

NVIDIA GeForce RTX 4090グラフィックスカードのパフォーマンス
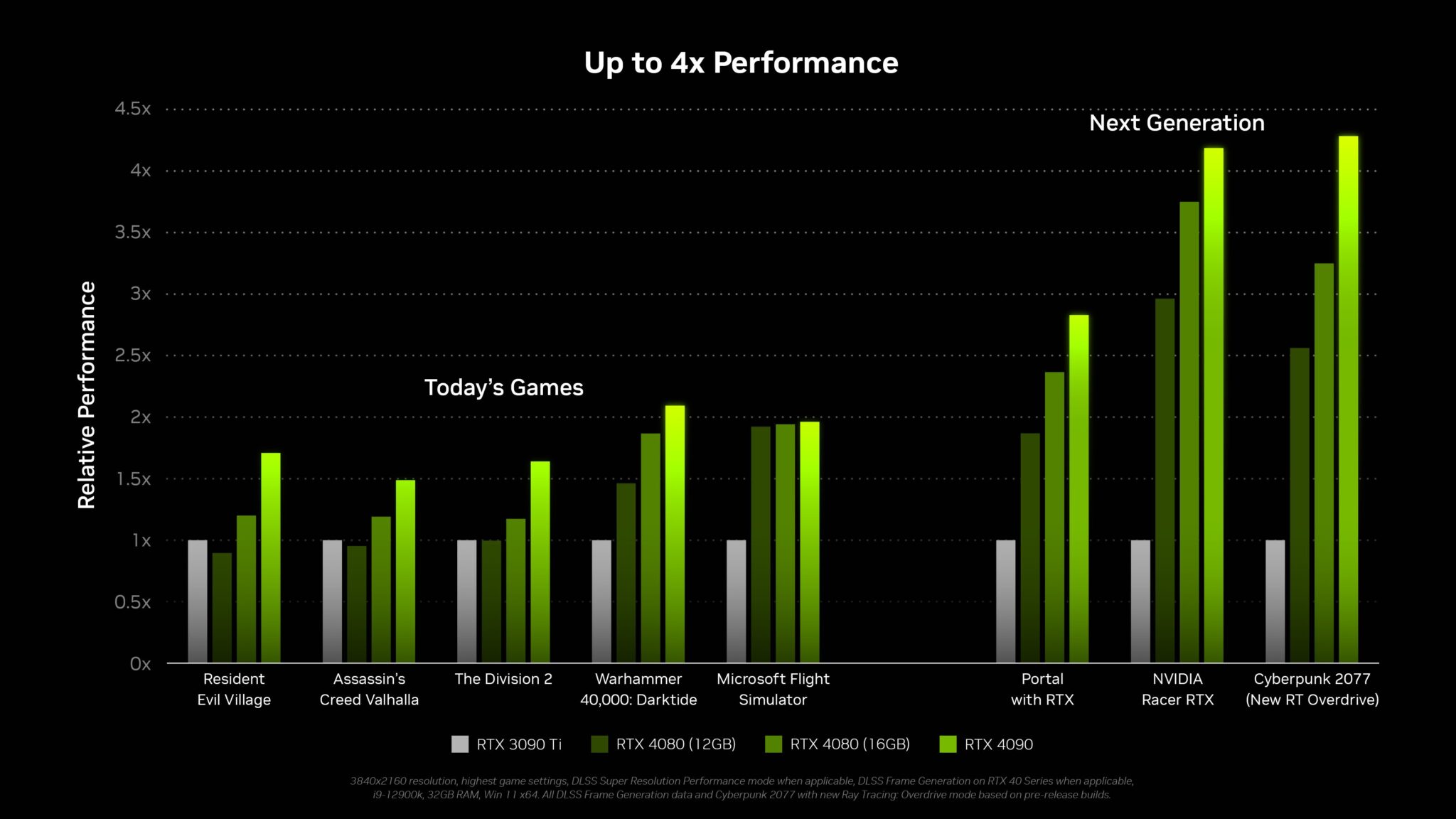
このモンスターGPUの性能については、NVIDIAが演算性能とゲーム性能の数値を公開しており、GeForce RTX 4090は、100 TFLOPsの演算馬力の制限に達する最初のゲームカードになるようです。
あくまでも比較のためのデータです:
- NVIDIA GeForce RTX 4090:90TFLOPs(FP32)(クロック2.8GHzと仮定した場合)
- NVIDIA GeForce RTX 3090 Ti:40TFLOPs(FP32)(ブーストクロック1.86GHzを想定)
- NVIDIA GeForce RTX 3090:36TFLOPs(FP32)(1.69GHzブーストクロックを想定)
2.8GHzの理論クロックに基づくと、最大103TFLOPsの演算性能となり、噂ではさらに高いブーストクロックが示唆されています。
これは、AMDのピーク周波数が平均的な「ゲーム」クロックよりも高いのと同様に、ピーククロックのように聞こえるのは間違いない。
100TFLOPs以上の演算性能は、3090 Tiフラッグシップに対して2倍以上の馬力を意味する。
しかし、演算性能は必ずしもゲーム全体の性能を示すものではないことを念頭に置く必要がありますが、それにもかかわらず、ゲーミングPCにとっては大きなアップグレードとなり、現在の最速コンソールであるXboxシリーズXの8.5倍となるのです。
※ 画像をクリックすると別Window・タブで拡大します。
これは、NVIDIAが各グラフィックスカードに対して示したように、演算性能で2倍、ゲーム性能で2倍の向上となり、それぞれの部門で大きな向上が期待されるRTとTensorコアの性能を考慮するまでもないことです。
RTX 3090とRTX 3090 Tiの2~4倍の性能向上は、非常に破壊的なものでしょう。
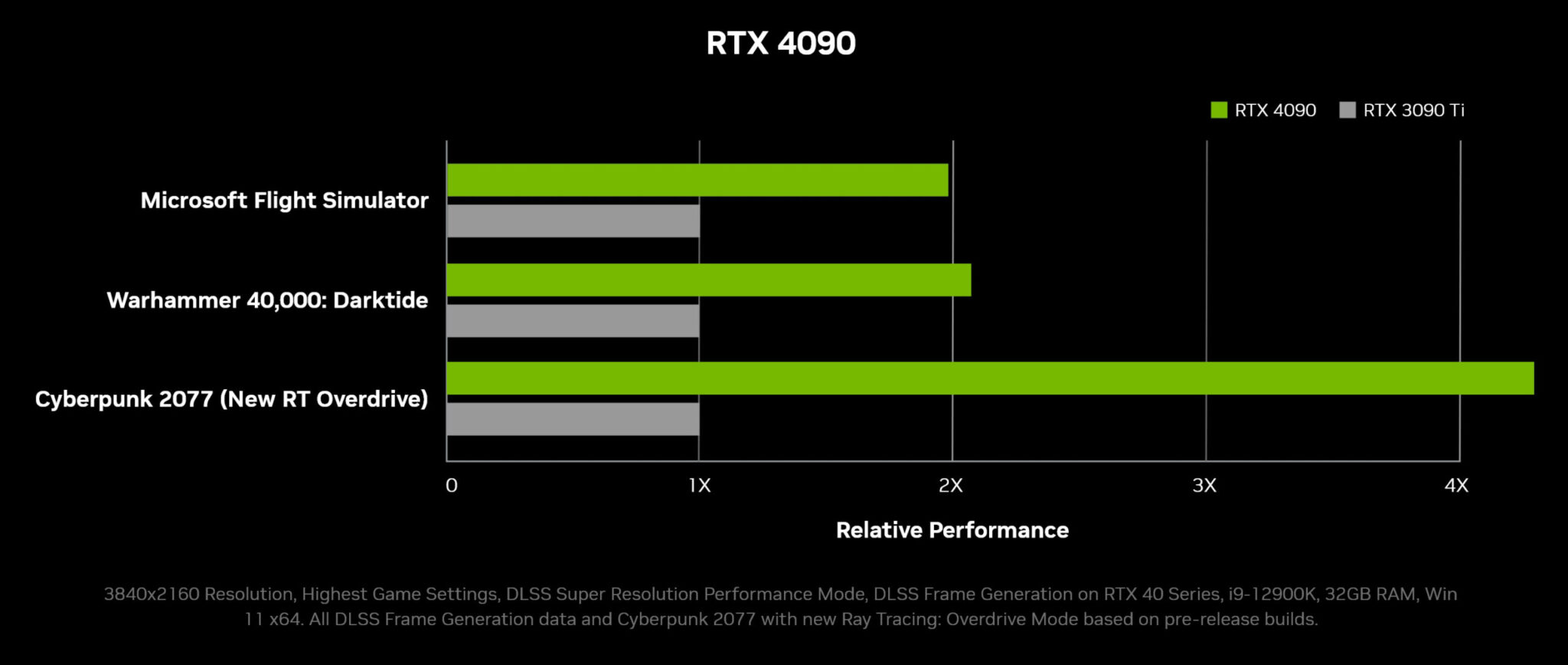
これは、NVIDIAが各グラフィックスカードに対して示したように、演算性能で2倍、ゲーム性能で2倍の向上となり、それぞれの分野で大きな向上が期待されるRTとTensorコアの性能を考慮するまでもないことです。
RTX 3090とRTX 3090 Tiの2~4倍の性能向上幅は、非常に破壊的なものでしょう。



※ 画像をクリックすると別Window・タブで拡大します。
NVIDIA GeForce RTX 4000シリーズグラフィックスカードは、10月の発売が噂されており、RTX 4090 Tiのシュラウドが先にリークしているのを見てきましたが、NVIDIAはまだRTX4090無印バージョンを最初にリリースし、RTX 4090 Tiバージョンがかなり後に市場に出回る可能性があります。
しかし、NVIDIAが次世代のごく初期にハイエンドSKUをリリースするのは、これが初めてではありません。
RTX 2080 Tiフラッグシップは、その旧モデルであるGTX 1080 Tiが初期ラインアップの発売から数カ月後に登場したにもかかわらず、他のラインアップと一緒に発売されました。
RTX 3090は、RTX 30シリーズのカードの初期ラインナップと一緒に発売されましたが、3090 Tiは1年以上遅れて登場しました。
今回、NVIDIAは最初から全ファミリーを発売し、後にミッドサイクルリフレッシュを行う可能性もあるが、それはまだわからない。
NVIDIA GeForce RTX 40シリーズ速報スペック:
| グラフィック カード名 | NVIDIA GeForce RTX 4090 | NVIDIA GeForce RTX 4080 16G | NVIDIA GeForce RTX 4080 12G | NVIDIA GeForce RTX 3090 Ti | NVIDIA GeForce RTX 3080 |
| GPU名 | Ada Lovelace AD102-300? | Ada Lovelace AD103-300? | Ada Lovelace AD104-400? | Ampere GA102-225 | Ampere GA102-200 |
| 製造プロセス | TSMC 4N | TSMC 4N | TSMC 4N | Samsung 8nm | Samsung 8nm |
| ダイサイズ | ~600mm2 | ~450mm2 | ~450mm2 | 628.4mm2 | 628.4mm2 |
| トランジスタ数 | ~75 Billion | TBD | TBD | 28 Billion | 28 Billion |
| CUDAコア数 | 16384 | 9728 | 7680 | 10240 | 8704 |
| TMU数 / ROP数 | 不明 | 不明 | 不明 | 320 / 112 | 272 / 96 |
| Tensor / RT コア数 | 不明 / 不明 | 不明 / 不明 | 不明 / 不明 | 320 / 80 | 272 / 68 |
| ベースクロック | 不明 | 不明 | 不明 | 1365 MHz | 1440 MHz |
| ブーストクロック | ~2520 MHz | ~2505 MHz | ~2610 MHz | 1665 MHz | 1710 MHz |
| FP32演算性能 | ~82 TFLOPs | ~50 TFLOPs | ~40 TFLOPs | 34 TFLOPs | 30 TFLOPs |
| RT TFLOPs | 不明 | 不明 | 不明 | 67 TFLOPs | 58 TFLOPs |
| Tensor-TOPs | 不明 | 不明 | 不明 | 273 TOPs | 238 TOPs |
| メモリ容量 ・種類 | 24 GB GDDR6X | 16 GB GDDR6X | 12 GB GDDR6X | 12 GB GDDR6X | 10 GB GDDR6X |
| メモリバス幅 | 384-bit | 256-bit | 192-bit | 384-bit | 320-bit |
| メモリ速度 | 21.0 Gbps | 23.0 Gbps | 21.0 Gbps | 19 Gbps | 19 Gbps |
| メモリ帯域幅 | 1008 GB/s | 736 GB/s | 504 GB/s | 912 Gbps | 760 Gbps |
| TBP | 450W (660W BIOS Max TGP) | 340W (516W BIOS Max TGP) | 285W (366W BIOS Max TGP) | 350W | 320W |
| 価格 (希望小売 価格 / FE版) | $1199 US? | $899 US? | $699 US? | $1199 | $699 US |
| 発売時期 | 2022/10? | 2022/11? | 2022/11? | 2021/07/03 | 2020/09/17 |
今のところ、噂では10月の発売とされています。
解説:
RTX4090の存在がnVidiaから公式に明かされました。
国内のメディアも同時に報じています。
わざわざウチのサイトを見る必要もないと思いますので解説にはちょっと他のサイトでは書かない(書けない)ことを書いておきます。
Ampereの在庫処分に関して、私はRTX4000シリーズがもうすぐ出るので、価格に納得できない限りは購入しないこと、私の意見では購入しないことをお勧めしてきました。
RTX4090のマーケティング資料が上の元記事にありますが、比較の対象になっているのはRTX3090やTiです。
nVidiaほどのシェアを取ると新製品の比較のターゲットになるのは自社の旧製品であり、猛烈に買い替えを促進するプロモーションを打ちます。
営利を追求する企業とはもともとそう言うものであり、仮に営業マン個人がどんなにいい人であったとしても「そう言う」理論が存在して、それを機械的に淡々とこなしていくので、客がどう思っているのかと言うのは関係ありません。
自分が旧製品を買った2-3か月後に「自分の買った製品よりいかに新製品が素晴らしいか?」と言うプロモーションを打たれるのは心理的にかなり負の感情を煽ります。
なぜわかるかと言えば私も何度も何度も同じような思いをしてきたからです。
だからこそ不確実でもリーク情報を追いかけるようになりました。
恐らく、Ampereの在庫処分品を納得して購入された方の中でもRTX4000シリーズのプロモーションを見て、後悔される方が出ると思います。
それは、旧製品を投げ捨てて、新製品が欲しくなるように一定のメソッドでプロモーションを展開するからです。
その内容は旧製品を徹底的にこき下ろし、新製品が如何に優れているか?カートをクリックして購入ボタンを如何に押させるか?
そう言うことを理詰めで追及し、それを我々に対して実践してくるからです。
そこには我々がゲームに期待するような夢や素晴らしい体験への期待とはかけ離れた冷たい機械的な理論が存在するだけで、感情や温かみはありません。
別に私の言うことを無理に信用することは無いです。
しかし、あなたの信じているインフルエンサーはもうすぐRTX4000シリーズが出ることを教えてくれましたか?
世界的に有名なマーケターのジェイ・エイブラハムはマーケティングの方法論を説いた書籍の中で「顧客とはあなたにとってのカモではなく、あなたが守るべき人である」と書いています。
あなたの信じていたインフルエンサーはあなたをカモだと思っているのか?あなたを守るべき人だと思っているのか?
事前にRTX4000シリーズの情報を出していたかどうかではっきりわかると思います。
nVidia RTX4000SUPER



nVidia RTX4000


nVidia RTX3000シリーズGPU
RTX3060 12GB GDDR6

RTX3050 6GB
