
GeForce RTX 40シリーズグラフィックスカードを搭載するNVIDIA Ada Lovelace Gaming GPUに関する詳細が明らかになりました。新情報はKopte7kimiからのもので、次世代アーキテクチャのブロック図について語られています。
NVIDIA GeForce Ada Lovelace GPU SMブロックダイアグラム詳細。より大きく、より良く、ゲーマーのために
NVIDIA Ada Lovelace GPUのアーキテクチャは、もはや謎ではありません。
GeForce RTX 40シリーズグラフィックスカードの次世代AD10*シリーズSKUを駆動する具体的な構成が判明し、ラインナップの仕様もリークされています。
さて、そろそろ純粋に次世代グラフィックスチップそのものについて語りたいところです。
NVIDIA AD102「Ada Lovelace」Gaming GPU「SM」ブロック図(ソース:Kopite7kimi):
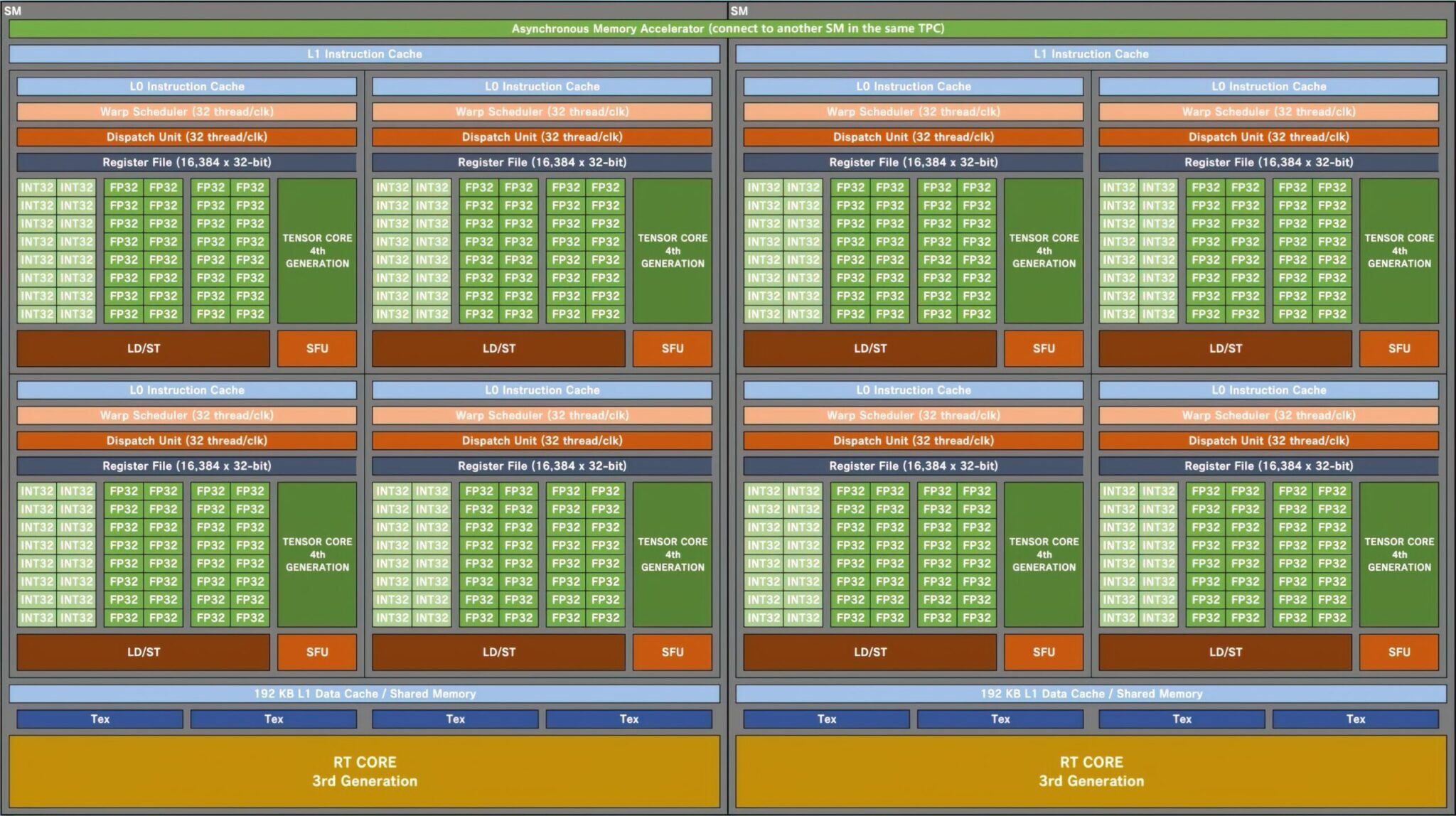
※ 画像をクリックすると別Window・タブで拡大します
NVIDIA GA102 「Ampere」ゲーミングGPU「SM」ブロック図:

※ 画像をクリックすると別Window・タブで拡大します
GPUの構成から、Kopite7kimiは、トップのAD102 GPUを、グリーンチームの他の様々なGPUと比較しています。
ゲーミングに特化した「Ampere GA102」や「Turing TU102」、HPCに特化した「Hopper GH100」や「Ampere GA100」などが追加されています。
HPCに特化した設計は、消費者向けの製品とは大きく異なるため、ここでは、AD102をゲーム用の先行製品と比較することにします。
NVIDIA Ada Lovelace AD102 GPUは、最大12 GPC (Graphics Processing Clusters)を搭載する予定です。
これは、GA102が7GPCしか搭載していないのに対し、70%増となる。各GPUは、6つのTPCと2つのSMで構成され、これは従来のチップと同じ構成です。
各SM(Streaming Multiprocessor)には4つのサブコアが搭載されますが、これもGA102 GPUと同じです。
変更点は、FP32とINT32のコア構成です。
各サブコアには128個のFP32が搭載されるが、FP32+INT32を合わせると最大192個になる。
これは、FP32ユニットがIN32ユニットと同じサブコアを共有しないためだ。
128個のFP32コアは、64個のINT32コアとは別になっている。
つまり、各サブコアは、128個のFP32ユニットと64個のINT32ユニットで構成され、合計で192個となる。
各SMは、FP32ユニット512個+INT32ユニット256個、合計768個を搭載することになる。そして、SMは合計24基(GPCあたり2基)なので、FP32ユニット12,288基、INT32ユニット6,144基、合計18,432基のコアを持つことになる。
また、各SMには2つのWrap Schedules(32スレッド/CLK)が含まれ、SMあたり64ラップになります。
これはGA102 GPUと比較して、コア数(FP32+INT32)で50%、Wraps/Threadsで33%の増加となっています。
NVIDIA Ada Lovelace GPUのスペック「速報値」
| GPU名 | AD102 | GA102 | TU102 | GA100 | GH100 |
| GPC | 12 (Per GPU) | 1.7x | 2x | 1.5x | 1.5x |
| TPC | 6 (Per GPC) | 同じ | 同じ | 0.75x | 0.67x |
| SM | 2 (Per TPC) | 同じ | 同じ | 同じ | 同じ |
| サブコア | 4 (Per SM) | 同じ | 同じ | 同じ | 同じ |
| FP32 | 128 (Per SM) | Same | 2x | 2x | 同じ |
| FP32+INT32 | 192 (Per SM) | 1.5x | 1.5x | 1.5x | 同じ |
| ワープ数 | 64 (Per SM) | 1.33x | 2x | 同じ | 同じ |
| スレッド | 2048 (Per SM) | 1.33x | 2x | 同じ | 同じ |
| L1キャッシュ | 192 KB (Per SM) | 1.5x | 2x | 同じ | 0.75x |
| L2キャッシュ | 96 MB (Per GPU) | 16x | 16x | 2.4x | 1.6x |
| ROP数 | 32 (Per GPC) | 2x | 2x | 2x | 2x |
キャッシュに話を移すと、ここもNVIDIAが既存のAmpere GPUに対して大きなブーストをかけたセグメントだ。
Ada Lovelace GPUは、SMあたり192KBのL1キャッシュを搭載し、Ampereから50%増となる。
これは、トップのAD102 GPUでは、合計4.5MBのL1キャッシュを搭載することになる。
L2キャッシュは、リークにあるように96MBに増量される。
これは、6MBのL2キャッシュを搭載するAmpere GPUの16倍に相当する。
キャッシュはGPU全体で共有される。

最後にROPですが、こちらも1GPCあたり32個と、Ampereの2倍になっています。
Ampereの最速GPUであるRTX 3090 Tiでは112個しかなかったROPが、次世代フラッグシップでは最大で384個になります。
また、Ada Lovelace GPUには、最新の第4世代Tensorコアと第3世代RT(Raytracing)コアが搭載されており、DLSSとRaytracingのパフォーマンスを次のレベルに引き上げるのに役立ちます。
Ada Lovelace AD102 GPUは、全体として以下のような特徴を備えています。
- 2倍速GPC(対Ampere比)
- 50%増のコア数(対Ampere比)
- 50%増のL1キャッシュ(対Ampere比)
- 16倍のL2キャッシュ(対Ampere比)
- 2倍のROP(対Ampere比)
- 第4世代Tensorコアと第3世代RTコア
2~3GHz台と言われるクロックは方程式に取り込まれないので、対Ampereのコアあたりの性能向上にも大きな役割を果たすことになることに注意してください。
次世代ゲーミングGPU「Ada Lovelace」を搭載したNVIDIA GeForce RTX 40シリーズグラフィックスカードは、2022年後半に発売予定&Hopper H100 GPUと同じTSMC 4Nプロセスノードを利用すると言われています。
NVIDIA CUDA GPU (噂) 暫定版:
| GPU | TU102 | GA102 | AD102 |
| アーキテクチャー | Turing | Ampere | Ada Lovelace |
| 製造プロセス | TSMC 12nm NFF | Samsung 8nm | 5nm |
| 画像処理 クラス タ(GPC) | 6 | 7 | 12 |
| テクスチャ 処理クラスタ (TPC) | 36 | 42 | 72 |
| ストリーミング マルチプロセッサー (SM) | 72 | 84 | 144 |
| CUDAコア数 | 4608 | 10752 | 18432 |
| 理論演算値 TFLOPs | 16.1 | 37.6 | ~90 TFLOPs? |
| メモリ種類 | GDDR6 | GDDR6X | GDDR6X |
| メモリバス幅 | 384-bit | 384-bit | 384-bit |
| メモリ容量 | 11 GB (2080 Ti) | 24 GB (3090) | 24 GB (4090?) |
| フラッグシップ SKU | RTX 2080 Ti | RTX 3090 | RTX 4090? |
| TGP | 250W | 350W | 450-850W? |
| 発売日 | 2018年9月 | 2020年9月 | 2022年下半期 (不明) |
解説:
LovelaceのGPUコンフィギュレーションがリーク
個人的に気になる個所は
「FP32ユニットがIN32ユニットと同じサブコアを共有しない」です。
AmpereはFP32演算性能の割にはゲーム性能が低かったのですが、根拠はないのですが、ここが関係しているのではないかと思っていました。
L2キャッシュについてですが、どこかに64bitバス幅当り16MBとあっと記憶しているのですが、全体で共有できるとのことでこれも過去に間違いを書いてしまったような気がします。
どうも「64bitバス幅で16MBを共有する」と言う意味ではなかったようです。
私はそう言う意味だと思っていたのですが、どうもこれも違うようですね。
INT32はGPUにはあまり重要ではないと思うのですが、これでドカンとゲーム性能が上がれば、「FP32ユニットがIN32ユニットと同じサブコアを共有しない」と言う部分が生きてきている証拠だと思います。
何れにしても大容量キャッシュとINT32コア問題を解決したLovelaceがどのくらいの性能を発揮するのか興味が尽きません。
nVidia RTX4000SUPER



nVidia RTX4000


nVidia RTX3000シリーズGPU
RTX3060 12GB GDDR6

RTX3050 6GB
