
AMDのStrix Point APUは、AI LLMワークロードにおいて、インテルのLunar Lake製品に対して強力な性能優位性を示している。
AMD Strix Point APUは、競合するインテルのLunar Lake SoCに対して全体的なレイテンシーを削減しながら、AI LLMで優位性を示す
AIワークロードにおけるより高い性能の要求により、多くの企業が独自の専用ハードウェアを市場に投入せざるを得なくなっただけでなく、競争も激化している。
LLM(大規模言語モデル)が著しく進化しているため、より高速なハードウェアに対するニーズも高まっています。
これに取り組むため、AMDは少し前にStrix Pointとして知られる独自のモバイル・プラットフォーム向けAI指向プロセッサを発表した。
最新のブログ記事で、同社はStrix Point APUが、より迅速なアウトプットのためにレイテンシーを減少させながら、ライバルに対して大きなリードを持つことができると主張している。
AMDによると、Ryzen AI 300プロセッサーは、インテルのLunar Lakeチップ(AIワークロード向けのインテルの特別なモバイルチップ)よりも高いTokens per secondを提供できるという。
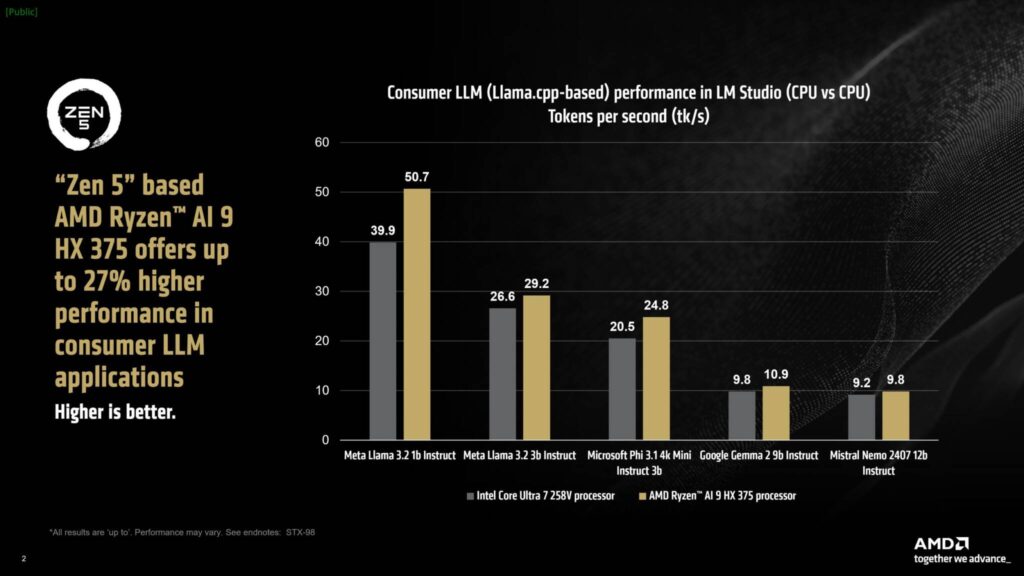
比較の通り、Ryzen AI 9 HX 375は、LM Studioのコンシューマー向けLLMアプリケーションにおいて、インテルCore Ultra 7 258Vよりも最大27%高いパフォーマンスを発揮する。
後者はLunar Lakeのラインナップの中では最速ではないが、コアクロック以外はコア/スレッド数が変わらないため、上位のLunar Lake CPUに近いことは確かだ。
LM Studioは、ユーザーがLLMの技術的な側面を学ぶ必要のないllama.cppをベースに構築されたAMDのコンシューマーフレンドリーなツールだ。
Llama.cppはx86 CPUに最適化されたフレームワークで、AVX2命令を使用する。
このフレームワークはLLMを実行するためにGPUを必要としないが、GPUを使えば確実に高速化できる。
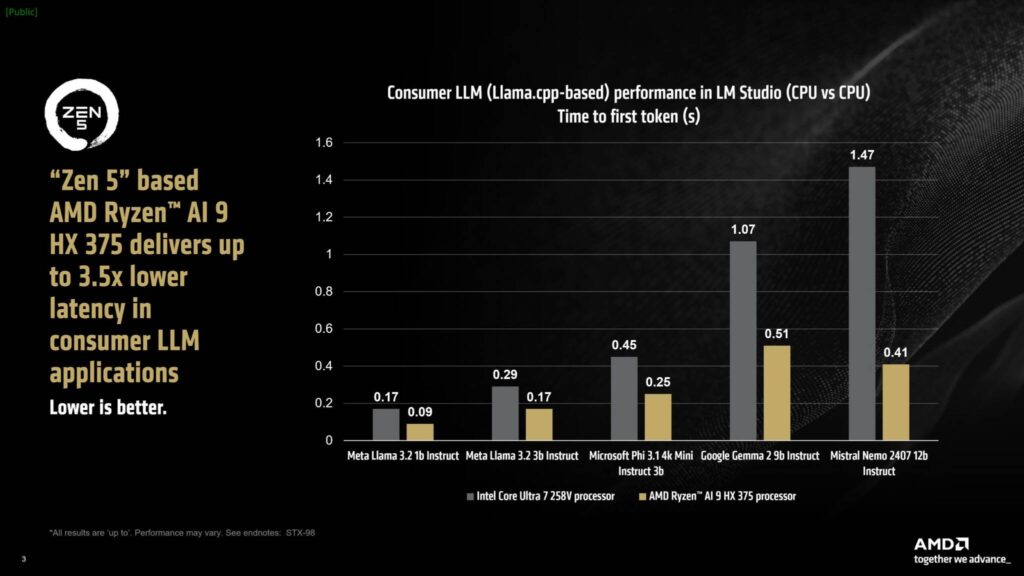
レイテンシ部門では、Ryzen AI 9 HX 375はライバルよりも最大3.5倍低いレイテンシを実現でき、Meta Llama 3.2 1b InstructではCore Ultra 7 258Vの39.9 tk/sに対して最大50.7 tk/sを達成できる。
Intel Lunar LakeとStrix Point APUの両方が強力な統合グラフィックスを搭載しているため、LM StudioはタスクをiGPUにオフロードし、Vulkan APIを使用してLLM性能を高めることができる。
Strix Point APUは、RDNA 3.5アーキテクチャに基づく強力なRadeonグラフィックスを搭載しており、Llama 3.2のパフォーマンスを最大31%向上させることができます。
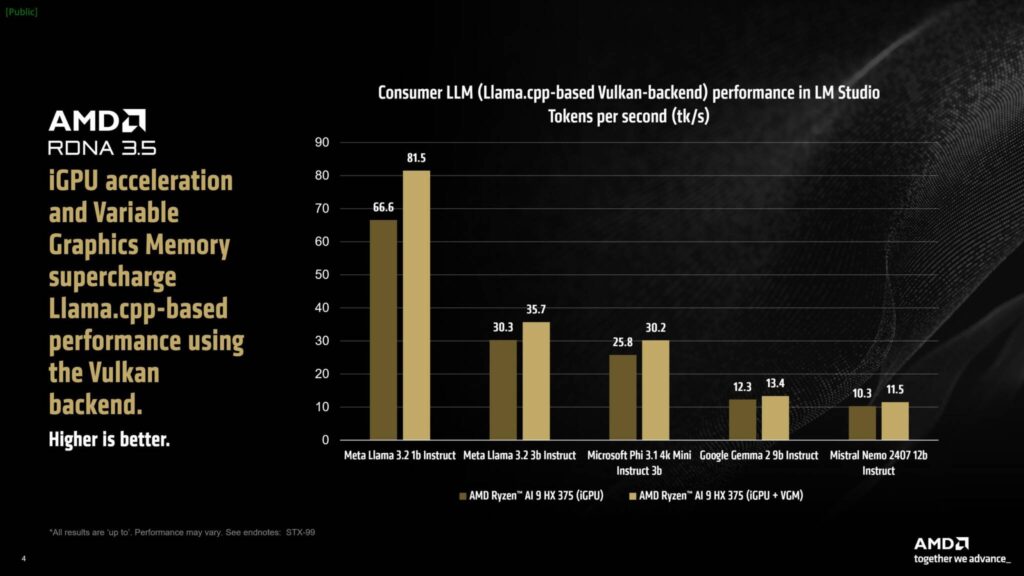
さらに、VGM(Variable Graphics Memory) Ryzen AI 300プロセッサを使用することで、iGPU指向のタスクのためにメモリを再割り当てすることが可能になり、電力効率が向上し、GPUアクセラレーションと合わせて60%も高いパフォーマンスを発揮する。
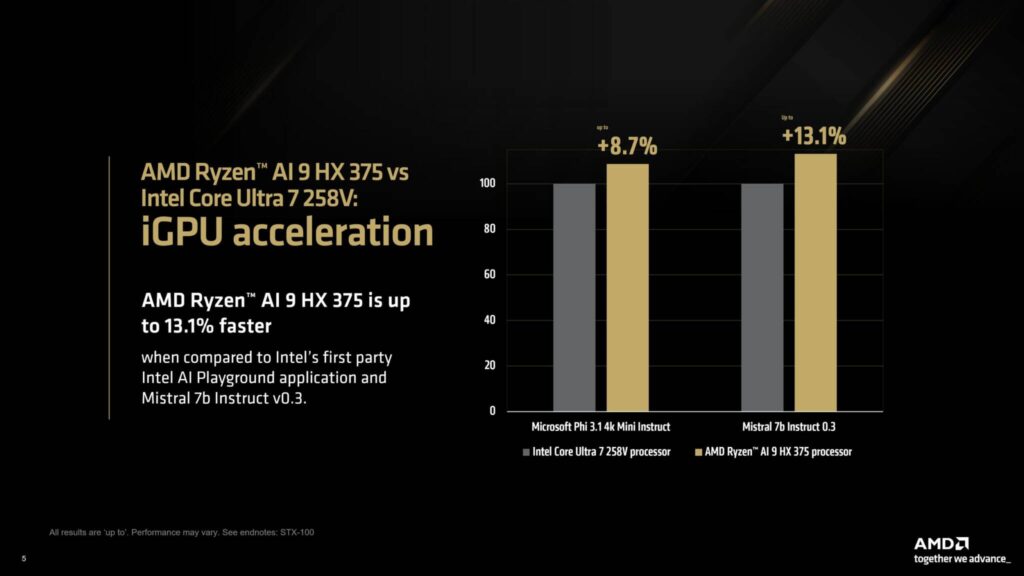
AMDによると、比較を公平にするため、両CPUを同じ設定でIntel AI Playgroundでもテストしたところ、Ryzen AI 9 HX 375はMicrosoft Phi 3.1でCore Ultra 7 258Vより最大8.7%高速で、Mistral 7b Instruct 0.3モデルでは最大13%高速だったという。
とはいえ、Ryzen AI 9 HX 375がフラッグシップのCore Ultra 9 288Vプロセッサーと対戦するのは興味深い。
現在AMDは、技術的スキルを持たない多くのユーザーがLLMにアクセスできるようにすることに注力しており、これはllama.cppフレームワークをベースとしたLM Studioを使用することで実現できる。
解説:
Strix PointがLLMにおいてLunarLakeに優位性を示す。
Luar Lakeは省電力性に特化しながら、Copilot+に準拠したAI性能を持つというのが最大の売りだと思います。
仮想敵はAMDではなく、Snapdragon Xシリーズであり、全体的に見て、非常に優秀な製品だと思います。
Lunar Lakeは性能という土俵では戦っていませんので、この比較はちょっとどうなのかと思いますが、AMDがWindowsでのLLM使用にいてLLM Studioという方法を用意したという点で意義があると思います。
NPU+iGPUのAI性能においてはStrix Pointが勝っているというのが立証できていますので、ぜひともCUDAと変わらない環境をWindowsでも提供されることを願ってやみません。
Lunar Lakeはx86の欠点であったバッテリーの持ちにフォーカスを当てた製品ですから、微妙な切り口ですが、TSMC3nmで製造されているLunar LakeにTSMC4nmで製造されているStrx Pointが省電力性で勝つのは非常に難しいので、x86の得意分野であるパフォーマンス競争を物差しに持ってくるのは非常に良い切り口だと思います。
AI全盛時代になれば、ハードというよりはソフト面での対応が非常に重要になってきますので、AMDには引き続くROCmを中心としたAIソフトウェア環境の整備を期待したいところです。