
NVIDIAは、公式のNVIDIA subreddit(VideocardzとHardwareeluxx経由)で開催されたQ&Aセッションの中で、GeForce RTX 30シリーズグラフィックスカードに関する詳細を明らかにしました。
NVIDIAの従業員の何人かが、新たに発表されたGeForce RTX 30シリーズグラフィックスカードに関連したコミュニティの質問に答えました。
N
NVIDIA GeForce RTX 30シリーズのGPUと機能はReddit Q&Aセッションで詳細がわかります-新しいSMデザイン、新機能など
Redditセッションの量は、ほぼ2000のコメントと回答された質問は、興味深い新しい詳細の啓示につながった。
NVIDIAは、独立したレビュアーが彼らのGeForce RTX 30シリーズカードの形で提供しなければならないものを紹介できるようにしたいと考えているので、コミュニティが望んでいるように、NVIDIAはまだ多くの詳細を明らかにしていません。
それまでは、NVIDIAの新しいゲーミングラインアップについて、NVIDIAが何を言わなければならないかを見てみましょう。

新しい NVIDIA ストリーミング マルチプロセッサ アンペア ゲーム GPU 用
最初に取り上げるのは、ゲーミング向けAmpere GPUに特化した新しいアーキテクチャ設計についてNVIDIAに問う質問だ。この質問には、NVIDIAのコンテンツ&テクノロジー担当上級副社長が答えている。
- これらのCUDAコアの倍増について少し詳しく教えてください。
- それはGPCの一般的なアーキテクチャにどのような影響を与えますか?
- すべてのFP32ユニットに電力を供給し続けることはどの程度の課題でしょうか?
- 高い稼働率を確保するために何が行われたのでしょうか?
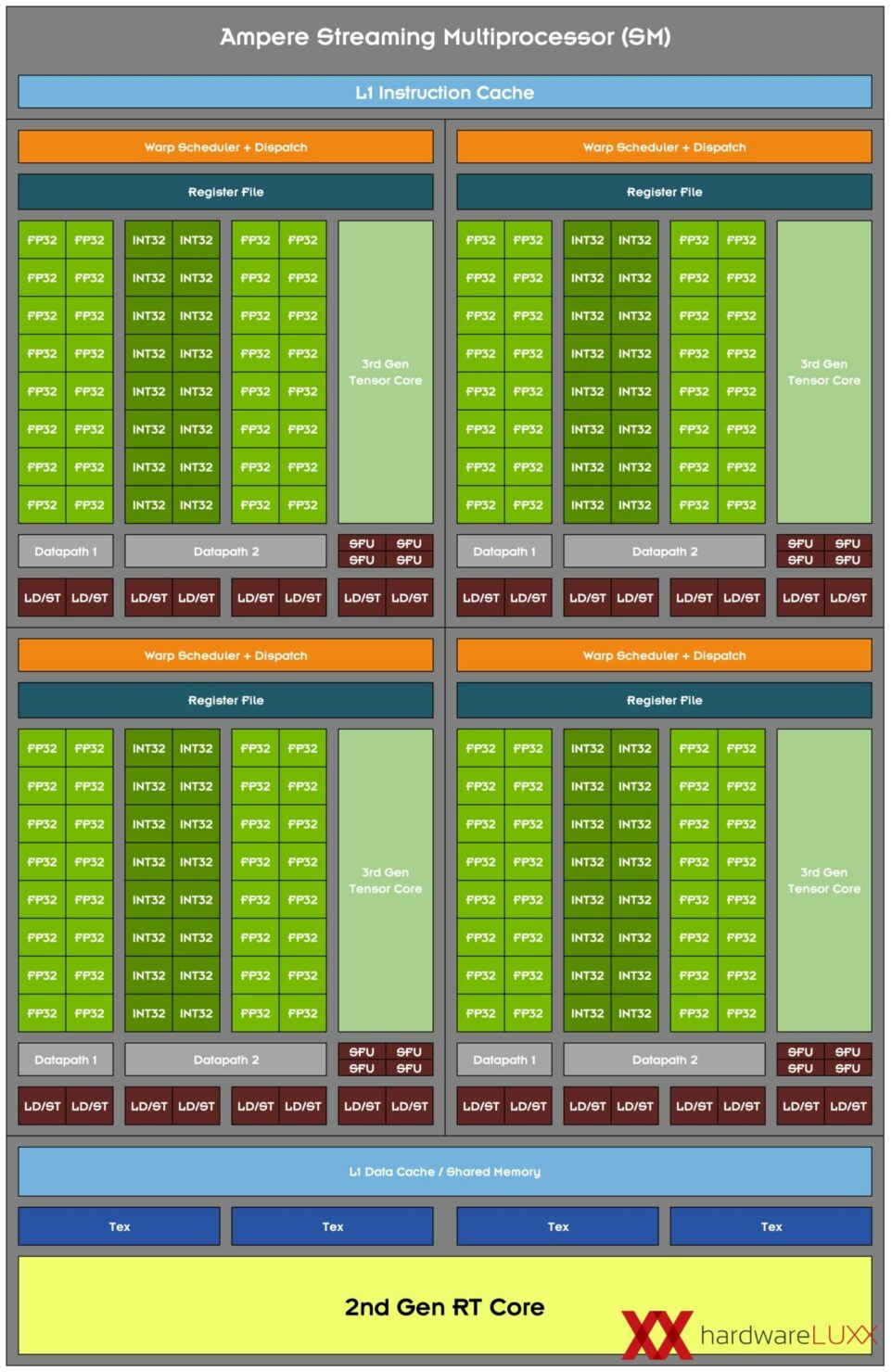
Ampere 30シリーズSMの主な設計目標の1つは、FP32演算のスループットをTuring SMの2倍にすることでした。
この目標を達成するために、Ampere SMにはFP32とINT32演算のための新しいデータパス設計が含まれています。
各パーティションの1つのデータパスは、1クロックあたり16個のFP32演算を実行できる16個のFP32 CUDAコアで構成されています。
もう1つのデータパスは、16個のFP32 CUDAコアと16個のINT32コアの両方で構成されています。
この新しいデザインの結果、各Ampere SMパーティションは、1クロックあたり32個のFP32演算、または16個のFP32と16個のINT32演算のいずれかを実行することができます。
4つのSMパーティションを合わせても、1クロックあたり128個のFP32演算を実行することができ、これはTuring SMの2倍のFP32レート、または1クロックあたり64個のFP32と64個のINT32演算を実行することができます。
FP32の処理速度が2倍になることで、多くの一般的なグラフィックスや計算操作、アルゴリズムのパフォーマンスが向上します。
最近のシェーダのワークロードは通常、FFMA、浮動小数点加算(FADD)、浮動小数点乗算(FMUL)などのFP32演算命令と、アドレス指定やデータ取得のための整数加算、浮動小数点比較、処理結果のmin/maxなどのより単純な命令を組み合わせたものが混在しています。
性能向上は、命令の組み合わせによって、シェーダとアプリケーションのレベルで異なります。
レイトレーシングデノイジングシェーダは、FP32のスループットを2倍にすることで大きな利益を得ることができる良い例です。
数学のスループットを2倍にするには、それをサポートするデータパスを2倍にする必要があったため、Ampere SMはSMの共有メモリとL1キャッシュの性能も2倍にしました。(Turingでは64バイト/クロックに対してAmpere SMでは128バイト/クロック)。
GeForce RTX 3080 の総 L1 帯域幅は 219 GB/秒であるのに対し、GeForce RTX 2080 Super は 116 GB/秒である。
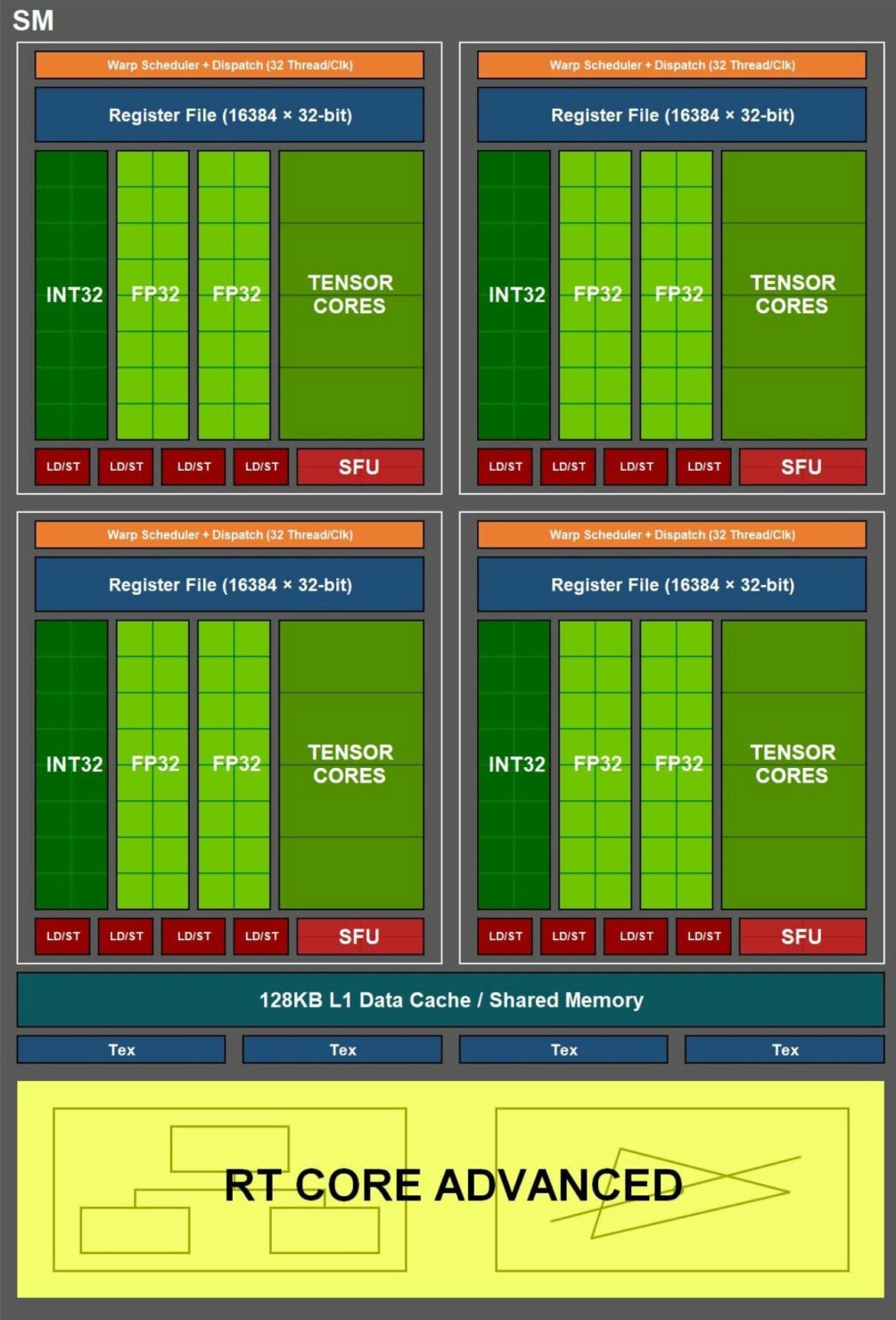
先行のNVIDIA GPUと同様に、Ampereは、グラフィックス処理クラスタ(GPC)、テクスチャ処理クラスタ(TPC)、ストリーミングマルチプロセッサ(SM)、ラスター演算子(ROPS)、およびメモリコントローラで構成されています。
GPC は、主要なグラフィックス処理ユニットのすべてが GPC 内に配置されている主要な高レベルハードウェアブロックです。
各GPCには専用のラスターエンジンが含まれており、現在では、NVIDIA Ampere Architecture GA10x GPUの新機能である2つのROPパーティション(各パーティションには8つのROPユニットが含まれています)も含まれています。
NVIDIA Ampereアーキテクチャの詳細については、近日中に発表されるNVIDIAのAmpereアーキテクチャホワイトペーパーを参照してください。
※ クリックすると別Window・タブで拡大します
Hardwareluxxが作成した次世代NVIDIA GeForce RTX 30シリーズグラフィックスカード用のAmpere Gaming SMのブロック図をTuring Gaming SMと比較した表現。
トニー氏が提供してくれた情報をもとに、Hardwareeluxxが作成したAmpere SMのブロック図表現。
新しいSMのブロックは最終的なものに近く、2つのデータパスにデュアルFP32ユニットがあることがわかります。
各SMは128個のCUDAコアで構成されており、これがAmpere GPUのコア数が2倍になった理由です。9月17日にAmpere GPUと基礎となるアーキテクチャについてのより詳細な記事をお届けしますので、お楽しみに。
NVIDIA RTX IO - どのように動作するのか、動作させるために何が必要なのか、そしてもっと多くのこと
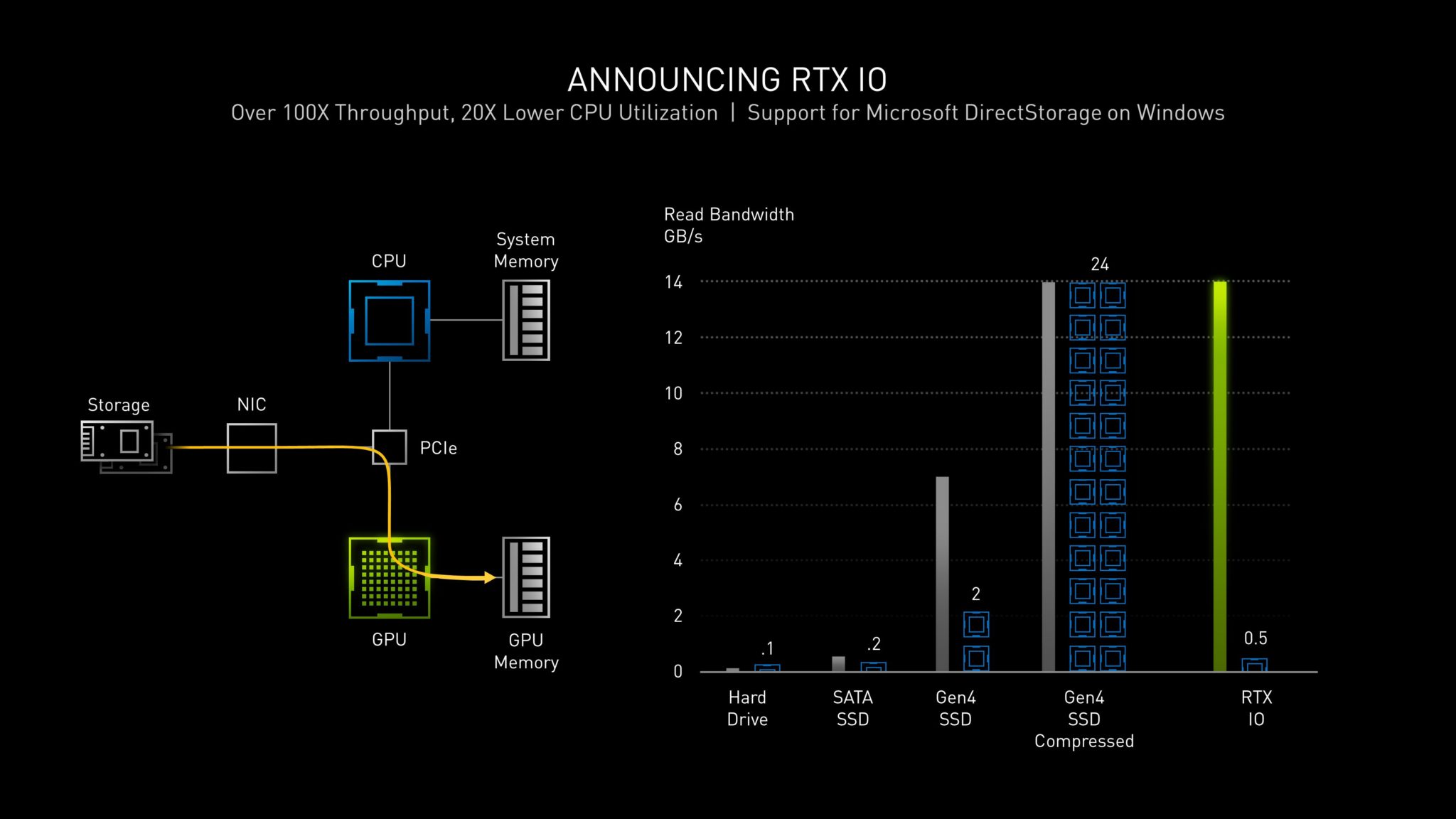
トニー氏は、ライブイベント中にNVIDIAが発表したRTX I/Oに関する質問にも答えています。RTX I/Oは、GPUベースのゲームアセットのロードと解凍を実現することを目的とした「一連の技術」と説明されていますが、同社は、標準的なハードドライブやストレージAPIと比較して、I/O性能を100倍に高速化できると主張しています。
※ クリックすると別Window・タブで拡大します
NVIDIAは、SATA SSDではなく、NVMeドライブの要件など、いくつかの詳細を提供しました。この次世代機能については、もっと多くのことが知られていますので、以下を読み続けてください。
Pengwin17523 - RTX I/Oのための特定のSSDの速度要件はありますか?
RTX IOのためのSSDの速度要件はありませんが、明らかに、最新世代のGen4 NVMe SSDのようなより高速なSSDの方が、より良い結果が得られます。
いくつかのゲームは、将来的にSSDのパフォーマンスのための最小要件を持つかもしれませんが、それはゲーム開発者によって決定されます。
RTX IOは、I/Oに必要なCPU負荷を減らし、GPUベースの解凍を可能にすることで、どれだけ速くてもSSDのパフォーマンスを加速させ、ゲーム資産を圧縮形式で保存することを可能にし、CPUコアの数十個分の負荷をその作業から解放する。
圧縮率は一般的に2:1なので、どのSSDの読み込み性能も2倍に増幅されます。リンク
SBMS-A-Man108 - RTX IOはSSDのスペースをVRAMとして使用することができますか?それとも私は完全に誤解しているのでしょうか?
[Tony Tamasi] RTX IOは、従来の方法よりもはるかに高速でSSDからデータを読み出すことを可能にし、データをGPUによって圧縮された形式で保存して読み出すことを可能にし、GPUで解凍して使用することを可能にします。
これにより、SSDがフレームバッファメモリを置き換えることはできませんが、SSDからのデータを、CPUのオーバーヘッドを大幅に減らして、GPUとGPUメモリにはるかに高速に到達させることができます。[リンク]
Aztec47 - Pytorchのような機械学習ライブラリにRTX IOが来るのを見ることができますか?これはリアルタイムアプリケーションのパフォーマンスを向上させるのに役立つでしょう。
[Tony Tamasi] NVIDIAは、約1年前にNVIDIA GPU DirectStorageで、さまざまなデータ分析プラットフォーム向けの高速I/Oソリューションを提供しました。これは、特にAIやHPCタイプのアプリケーションやワークロードのために、GPUとストレージ間の高速I/Oを提供します。詳細については、https://developer.nvidia.com/blog/gpudirect-storage/ [リンク]をご覧ください。
Qrios1ty - RTX I/O機能に興奮していますが、どのように正確に動作するのか部分的に理解していません。
[Tony Tamasi] RTX IOとDirectStorageは、アプリケーションが新しいAPIを組み込むことで、これらの機能をサポートする必要があります。Microsoftは来年、ゲーム開発者向けにDirectStorage for Windowsの開発者プレビューを目標にしており、NVIDIA RTXゲーマーは、利用可能になり次第、RTX IOで強化されたゲームを利用することができるようになります。
Ben10lightning- RTX IOはRTX 2080でサポートされますか?
[Nestledrink] はい。
TuringとAmpere
PCIe 4.0とPCIe 3.0の違いは?
Tony氏が回答したもう一つの重要な質問は、PCIe 4.0とPCIe 3.0のインターフェースの違いです。
NVIDIA AmpereゲーミングGPUの場合、それは、Gen 3.0プロトコル対Gen 4.0プロトコルのパフォーマンスの違いは、数パーセント未満であり、主要な影響は、CPU自体からであることが述べられています。
NVIDIAは、フルのGen 4プラットフォームで性能が向上する可能性について言及しており、PCをアップグレードする人は、その点を考慮しておくべきである。
PCIe 3.0はRTX 3090のボトルネックになりますか?私のIntelシステムは4.0をサポートしていないので心配です。
Tony Tamasi - システムのパフォーマンスは多くの要因によって影響を受け、その影響はアプリケーションによって異なります。
一般的に、x16 PCIE 4.0からx16 PCIE 3.0に移行した場合の影響は数パーセント以下です。
多くの場合、CPUの選択がパフォーマンスに与える影響は大きくなります。
NVIDIA DLSS 2.1、Reflex、RTXエンコーダの詳細
質問の次のカップルは、DLSS 2.1、Reflex、および異なる従業員によって回答されたAmpereエンコーダなどのNVIDIA AmpereゲーミングGPUの特定の機能に関連しています。

※ クリックすると別Window・タブで拡大します
EeK09 - DLSSにはどのような進化が期待できますか?ほとんどの人がDLSS 3.0か、少なくともDLSS 2.1のようなものを期待していました。DLSSを改良し続け、同じバージョンを維持しながら、より多くのゲームのサポートを提供するつもりですか?
[NV-Randy] DLSS SDK 2.1がリリースされ、3つのアップデートが含まれています。
- 8Kゲーミングのための新しいウルトラパフォーマンスモード。新しい9倍スケーリングオプションでGeForce RTX 3090上で8Kゲーミングを実現。
- VRをサポート。VRタイトルでDLSSがサポートされるようになりました。
- ダイナミック解像度をサポート。出力サイズは固定のままで、入力バッファはフレームごとに寸法を変えることができます。レンダリングエンジンがダイナミック解像度をサポートしている場合、DLSSを使用して、表示解像度に必要なアップスケールを実行することができます。リンク
Carmen813 - AmpereシリーズのカードのRTXエンコーダには、Turingリリースで見たような改善があるのでしょうか?ブロードキャストソフトウェアの情報を見ましたが、同じビットレートで全体的な画質を向上させるというラインに沿って考えています。
[Jason Paul] RTX 30シリーズでは、ビデオデコード側の改善に重点を置くことにして、AV1デコードのサポートを追加しました。エンコード側では、RTX 30シリーズは、当社のRTX 20シリーズGPUと同じ優れたエンコーダを搭載しています。また、NVIDIAエンコーダSDKも最近更新しました。今後数ヶ月の間に、ライブストリームアプリケーションはSDKのこの新しいバージョンにアップデートされ、ストリーマーのための新しいパフォーマンスオプションのロックが解除されます。
Akanash94 - Nvidia reflexはPascal GPUで動作しますか、それともこれはTuring/Ampere機能のみですか?
[NV_Tim] RTX 20シリーズを含む900シリーズ+GPUで動作します。
NVIDIA RTX 30シリーズ Founders Editionクーラー - Turing Founders Editionよりも静かで効率的なクーラー
NVIDIAのGeForceのプロダクトマネージャーであるQi Lin氏は、GeForce RTX 30シリーズのFounders Editionのデザインは、Turingカードが利用しているFounders Editionよりも冷却性が高く、静音性に優れていると、あるコミュニティメンバーに説明している。
また、ほとんどのユーザーは、筐体がGPUに新鮮な空気を送り込み、PCケースから空気を効率的に外に出すように構成されていれば、エアフローを気にする必要はないと述べている。

iCinn - デュアルエアフロー設計が倒立ケースのためにめちゃくちゃになるのかどうか、心当たりはありますか?以前のデザインよりも?それはCPU上でそれを吹き飛ばすような気がします。
しかし、CPUクーラーはまだケースの外に吹き出してしまいます。それほど悪くないかもしれません。
二つ目の質問。
3090用のTitanの10倍の静音性は、NVIDIA GeForce RTX2080 Super(例えばEvga ultra fx)と比べても、多かれ少なかれ静かなのではないでしょうか?
[Qi Lin] u/iCinn 新しいフロースルー冷却設計は、シャーシのファンがGPUに新鮮な空気をもたらし、GPUを流れる空気をシャーシの外に移動させるように構成されている限り、うまく機能するでしょう。シャーシが反転しているかどうかは関係ない。
Founders Edition RTX 3090は、Titan RTXとFounders Edition RTX 2080 Superの両方よりも静かです。特定のパートナーのデザインに対してテストしたわけではありませんが、聞いただけで感動すると思います...というか、聞こえないと思います。
発売日と価格についてですが、NVIDIAはGeForce RTX 3080が最初に9月17日に店頭に並ぶと発表しており、続いて9月24日にGeForce RTX 3090、そして最後に10月にGeForce RTX 3070が発売されると発表しています。
グラフィックカードの小売価格は1499ドル(RTX 3090)、699ドル(RT 3080)、499ドル(RTX 3070)。カスタムモデルは参考価格に固執するが、よりプレミアムなモデルはより高い価格が特徴となる。
解説:
RedittでnVidia公式が質問に答える
これらを見ると、nVidiaは新しい技術を取り入れるのに積極的であり、こういったところが他社を圧倒する強みになっているのかなと思います。
私はnVidiaのマーケティング手法があまり好きにはなれませんが、Geforceが非常に優秀な製品であることは確かだと思います。