
NVIDIAは次世代Feynmanチップで推論スタックを支配する計画で、同社はアーキテクチャ内にLPUユニットを統合する可能性があります。
NVIDIAは推論向けにSRAMダイとのハイブリッドボンディングを使用する可能性があるが、いくつかの課題も
Team Green※1のGroqのLPUユニットに関するIPライセンス契約は、買収の規模や関連する収益額を見ると控えめな開発のように聞こえるかもしれませんが、実際にはNVIDIAはLPUを通じて推論セグメントでリードを取ろうとしており、これについてはすでに広範な記事で取り上げています。NVIDIAがLPUをどのように統合する計画かについては、さまざまな提案が浮上していますが、GPU専門家であるAGFの見解によると、LPUユニットはTSMCのハイブリッドボンディング技術※2を通じて次世代FeynmanGPUに積層される可能性があるようです。
Groq LPU blocks will first appears in 2028 in Feynman (the post Rubin generation).
Deterministic, compiler-driven dataflow with static low-latency scheduling and Higher Model Floats Utilization (MFU) in low-batch scenarios will give Feynman immense inference performance boost in… https://t.co/GVZCWiENC2— AGF (@XpeaGPU) December 28, 2025
この専門家は、実装がAMDのX3D CPU※3で行われた方式に似たものになる可能性があると考えており、TSMCのSoICハイブリッドボンディング技術※4を利用して3D V-Cache※5タイルをメインコンピュートダイ※6に統合します。AGFは、SRAMをモノリシックダイ※7として統合することはFeynman GPUにとって適切な選択ではないと主張しています。その理由は、SRAMのスケーリングには限界があり、先進ノード※8で構築すると高級シリコンを無駄にし、ウェーハ面積あたりの使用コストが劇的に増加するためです。代わりに、AGFはNVIDIAがLPUユニットをFeynmanコンピュートダイに積層すると考えています。
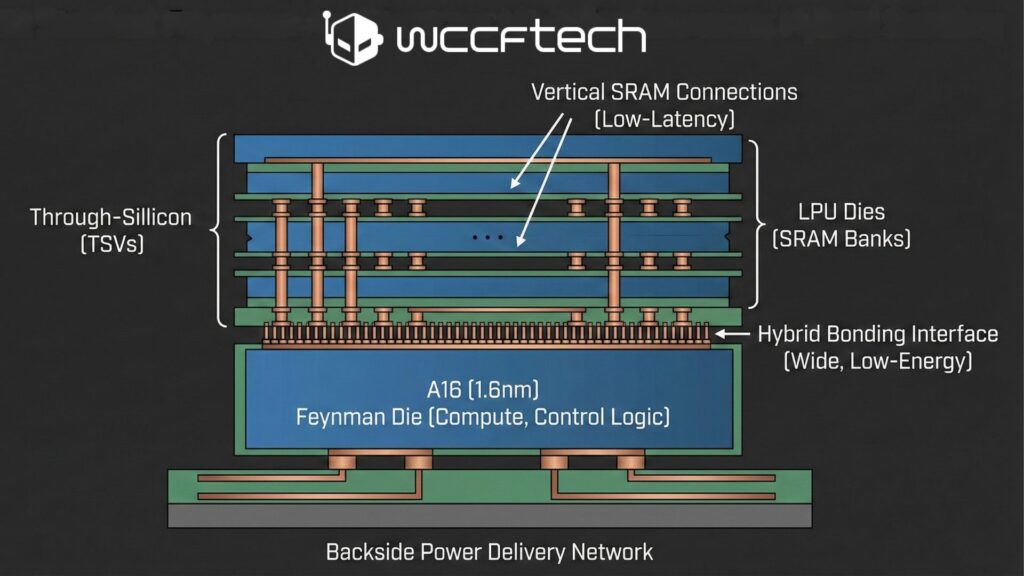
このアプローチは理にかなっているように思えます。というのも、これによりA16(1.6nm)のようなチップがメインのFeynmanダイに使用され、そこには演算ブロック(Tensorユニット※9、制御ロジックなど)が含まれる一方で、個別のLPUダイには大容量のSRAMバンクが含まれることになるからです。さらに、これらのダイを接続するために、TSMCのハイブリッドボンディング技術が重要な役割を果たします。これにより、広帯域インターフェース※10とパッケージ外メモリと比較してビットあたりのエネルギーを低減できます。さらに、A16は裏面電力供給※11を搭載しているため、表面は垂直SRAM接続用に解放され、低レイテンシのデコード応答が保証されます。
しかし、この技術には、NVIDIAが熱制限をどのように管理するかという懸念があります。高い演算密度で動作するプロセスにダイを積層することは、すでに課題だからです。そして、持続的なスループットに重点を置くLPUでは、ボトルネックが発生する可能性があります。さらに重要なことに、このようなアプローチでは実行レベルの影響も大幅に増大します。LPUは固定実行順序に集中するため、当然、決定性※12と柔軟性の間に矛盾が生じます。

たとえNVIDIAがハードウェアレベルの制約を解決できたとしても、主要な懸念は、LPUスタイルの実行内でCUDA※13がどのように動作するかによって引き起こされます。LPUは明示的なメモリ配置を必要としますが、CUDAカーネル※14はハードウェア抽象化※15のために設計されているからです。AIアーキテクチャ内にSRAMを統合することは、Team Greenにとって容易な作業ではありません。LPU-GPU環境が最適化されていることを保証するには、エンジニアリングの妙技が必要になるでしょう。しかし、NVIDIAが推論セグメントでリードを取りたいのであれば、これは支払う意思のあるコストかもしれません。
注釈
- ※1 Team Green:NVIDIAの通称(ロゴの色に由来)
- ※2 ハイブリッドボンディング技術:複数のチップを非常に高密度で接続する先進的な半導体製造技術
- ※3 X3D CPU:AMDが開発した3D V-Cache技術を搭載したCPU
- ※4 SoIC(System on Integrated Chips):TSMCの3Dチップ積層技術
- ※5 3D V-Cache:チップ上に垂直に積層された大容量キャッシュメモリ
- ※6 コンピュートダイ:実際の演算処理を行うチップの中核部分
- ※7 モノリシックダイ:単一の半導体基板上に全ての機能を統合したチップ
- ※8 先進ノード:最先端の微細化プロセス技術(数値が小さいほど高度)
- ※9 Tensorユニット:AI演算に特化した処理ユニット
- ※10 広帯域インターフェース:大量のデータを高速転送できる接続方式
- ※11 裏面電力供給:チップの裏側から電力を供給する新技術で、表面を信号伝達に専念できる
- ※12 決定性:同じ入力に対して常に同じ結果を返す性質
- ※13 CUDA:NVIDIAのGPU向け並列コンピューティングプラットフォーム
- ※14 CUDAカーネル:CUDA上で実行されるプログラムの中核部分
- ※15 ハードウェア抽象化:具体的なハードウェアの詳細を隠蔽し、プログラミングを容易にする
解説:
GroqのLPUとは大規模言語モデル(ChatGPTやGemini、claudeのようなシステム)に特化したプロセッサのことです。
LPUはキャッシュの代わりに大容量のSRAMを持ち非常に高速に推論を行うことができます。
これは演算性能より莫大なデータ量を滞りなく流すことの方がAI処理においては有効であるというアーキテクチャーの一つです。
ローカルAIは画像生成が中心ですので、LLMにはなじみのない方が多いと思いますが、LLMでは量子化しない場合(たいていの場合、性能の劣化をもたらす)莫大なデータ量になります。
例を挙げるとMetaの最新のLlama3.3 70BはFP16で約142GBほどあります。これで中規模なモデルデータです。
AIの場合、一括でメモリロードする必要がありますのでこれを普通のPCで実行するのがいかに絶望的な話なのかよくわかるのではないかと思います。
そこで登場するのが量子化です。70Bは4bitで量子化するとゲーミングPCのハイエンドクラスで実行することがようやく現実的になります。
最新のIQ4_XSという方式で量子化すると40GB弱になります。
これでも普通のPCで推論するにはかなり厳しい容量ですが、ローカルPCで推論することが現実的に考えられる容量とはいえるのではないでしょうか?
中規模のデータでこれですから、LLMの場合、いかに滞りなくデータを流すのが重要なのかよくわかるのではないでしょうか?
ちなみにLlama3.3 70Bの場合、16GB程度のGPUで入りきらなかった分を共有GPUメモリに入れて推論するより、最初からすべてオンメモリでCPU推論する方が推論速度が速くなります。
※ RTX5060Ti 16GBとRyzen 9 7950X(AVX512対応)+128GB RAMで比較
GPUがいかに高速に推論できたとしてもデータフローが速い方が性能が出るという端的な例になります。
GPUに入りきらなかった分はメインメモリのGPU共有メモリに格納され、推論によってPCIeを通じて本体側とのメモリとのやり取りが頻繁に発生します。
いかにPCIeが高速とは言ってもメモリの速度には敵わないです。
画像生成AIだとちょっと前まであまり絶望的なデータ量ではありませんでしたから、よくわかってない方もいると思いますので念のために注釈しておきます。
特化したプロセッサにはASICがありますが、LPUはその中でもLLMに特化したASICといえるかもしれません。
このLPUのライセンスをNVIDIAが取得したことによって未来のNVIDIA製品に搭載されるだろうという噂が流れています。
データフローに関してはHBM系のメモリを進化させできうる限り高速にしていますが、それでもGPUというアーキテクチャーが特化したプロセッサと比較すると劣っているということの証明でもあります。
そのため、LPU的な仕組みを導入することにしたのでしょう。
この演算性能よりデータフロー重視という考え方にはジム・ケラー氏の率いるテンストレントのTensixコアがあります。
こちらの場合、+スケーラビリティですね。
まあ、NVIDIAも激しい性能競争の中で、どこかで特化型の回路を設計に入れざるを得なくなってきたということなのでしょう。