強力なNightshadeは、テキストから画像に変換するジェネレーターをターゲットにしている。

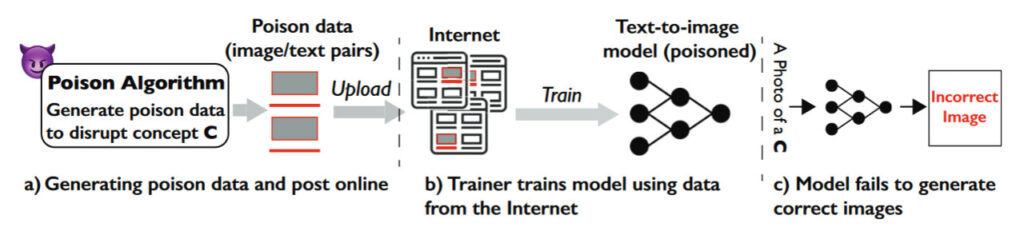
Nightshadeと名づけられた新しい画像データツールが、コンピュータサイエンスの研究者たちによって、テキストから画像への変換モデル用のデータに「毒」を盛るために作られた。
Nightshadeは、オンラインにアップロードされたクリエイターの画像に気づかれないような変更を加える。
その後、データスクレーパーがこれらの変更された画像をデータセットに追加すると、モデルに「予期せぬ動作を導入」し、毒を盛る。
テキストから画像への生成モデルに対するプロンプト固有のポイズニング攻撃(Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models)」と呼ばれる論文のプレビューが最近arXivで発表され、Nightshadeの範囲と機能の概要が明らかになった。
MITテクノロジーレビューは、このプロジェクトを支えるチームとの会談から、さらなる洞察を得ている。
AIモデルがクリエイターの明示的な許可なしにデータで学習され、学習した内容に基づいて「新しいデータを生成」するという問題は、ここ数ヶ月のニュースでもよく取り上げられている。
データスクレイピングの自由奔放さと、それに続く機械によるほとんど、あるいはまったく帰属のない再投稿のように見えるものは、多くの分野のクリエイターたちに、現在のジェネレーティブAIプロジェクトに眉をひそめさせる原因となっている。
Nightshadeは、ビジュアルアーティストを支援すること、少なくともAIデータスクレイパーに無闇にデータを取得することに警戒心を抱かせることを目的としている。
このツールは、人間の視聴者に害を与えることなく画像データに毒を盛ることができるが、DALL-E、Midjourney、Stable Diffusionのような生成ツールで使用されているAIモデルを混乱させるだろう。
イヌホウズキによるデータ毒効果の例としては、犬が猫になる、車が牛になる、キュビズムがアニメになる、帽子がトースターになる、などのカオスが考えられる。Nightshadeの破壊作用の例は以下を参照。


以前は、生成AIに毒を盛るには、トレーニングパイプラインに何百万もの毒サンプルが必要だと考えられていた。
しかし、Nightshadeは "プロンプトに特化した毒物攻撃...効力のために最適化された "と主張している。
驚くべきことに、Nightshadeは100個以下の毒サンプルで破壊的な仕事をすることができる。
さらに研究者によれば、Nightshadeの毒の効果は関連する概念に「ブリードスルー」し、1つのプロンプトで複数の攻撃をまとめて行うことができるという。
最終的な結果は、ユーザーのテキストプロンプトに基づいて意味のある画像を生成できないようにすることである。
研究者たちは、Nightshadeのようなツールを無闇に使うつもりはない。
むしろ、"オプトアウト/クロール禁止ディレクティブを無視するウェブスクレイパーに対する、コンテンツ制作者の最後の防御 "を意図している。
このようなツールは、西部開拓時代のAIデータスクレイパーに対する抑止力になるかもしれない。
MIT Technology Reviewのレポートによれば、Stability AIやOpenAIのような主要なAI企業は現在でも、ユーザーが事前に許可を求めるための手順を踏んだ場合にのみ、芸術作品をスクレイピングしている。
代わりに、ユーザーの事前許可を追跡する必要があるのはAI企業であるべきだと考える人もいる。
Nightshadeの研究チームを率いるシカゴ大学のベン・ザオ教授は、クリエイターが個人のアートスタイルをマスクして、AI企業にスクレイピングされたり模倣されたりするのを防ぐツールGlazeの開発者でもある。
オープンソースプロジェクトとして準備が進められているNightshadeは、後日Glazeに統合され、AIのデータポイズニングをオプションにする可能性がある。
ソース:Tom's Hardware - Nightshade Data Poisoning Tool Could Help Artists Fight AI
解説:
AIのスクレイピングを妨害するツールが登場
とのこと、どのように仕組みなのかははっきりわかりませんが、単純にタグを書き換えるというようなものではないようですね。
100程度の毒入りサンプルをスクレイピングするだけで学習結果に破壊的な効果をもたらすようです。
100程度でこれだけの効果が出せるならば、作風を模倣して現実の写真から多数のデータを生み出して自動でタグ付けし、学習することは出来ないのですかね。
100枚程度のデータを買うのはそれほど多額の費用は掛からないでしょう。
少なくとも飛ぶ鳥を落とす勢いのAI企業なら簡単に出せるはずです。
学習に対するコストのようなものはきちんと支払われるべきだと思いますが、あまりに強欲な価格を設定すると一部の企業しか使えなくなると思いますし、もっと効果的な学習方法が開発されてしまうかもしれません。
AIの学習はどこからがコピーでどこまでが創作なのか?と言う命題はAI/MLにおいて永遠に付きまとう課題だと思います。
簡単に結論が出る問題ではないと思いますが、少なくとも無断で学習する質の悪いスクレイパーに対しては一定の効果はあるのではないでしょうか。
画像が画像である以上、ダウンロードして毒を取り除き、自動で学習するような対抗ツールも出てくると思います。
Pxabayなどの存在を考えるとそのうちBtoBで学習画像データを売るサイトなどが出てきてもおかしくはないですね。
その方が世間の反発も小さいし、うるさくないでしょう。
ネットの野良データを勝手にスクレイピングして問題になるは今だけの状況なのかもしれません。