Nvidia、自社製CPU+GPUとL4 GPUの初のMLPerfスコアを提出。

Nvidiaは本日、Grace Hopper CPU+GPU SuperchipとL4 GPUアクセラレータの最初のベンチマーク結果を、さまざまなワークロードにおけるAI性能を測定するための公平な競争の場を提供するために設計された業界標準のAIベンチマークであるMLPerfの最新バージョンに提出したと発表した。
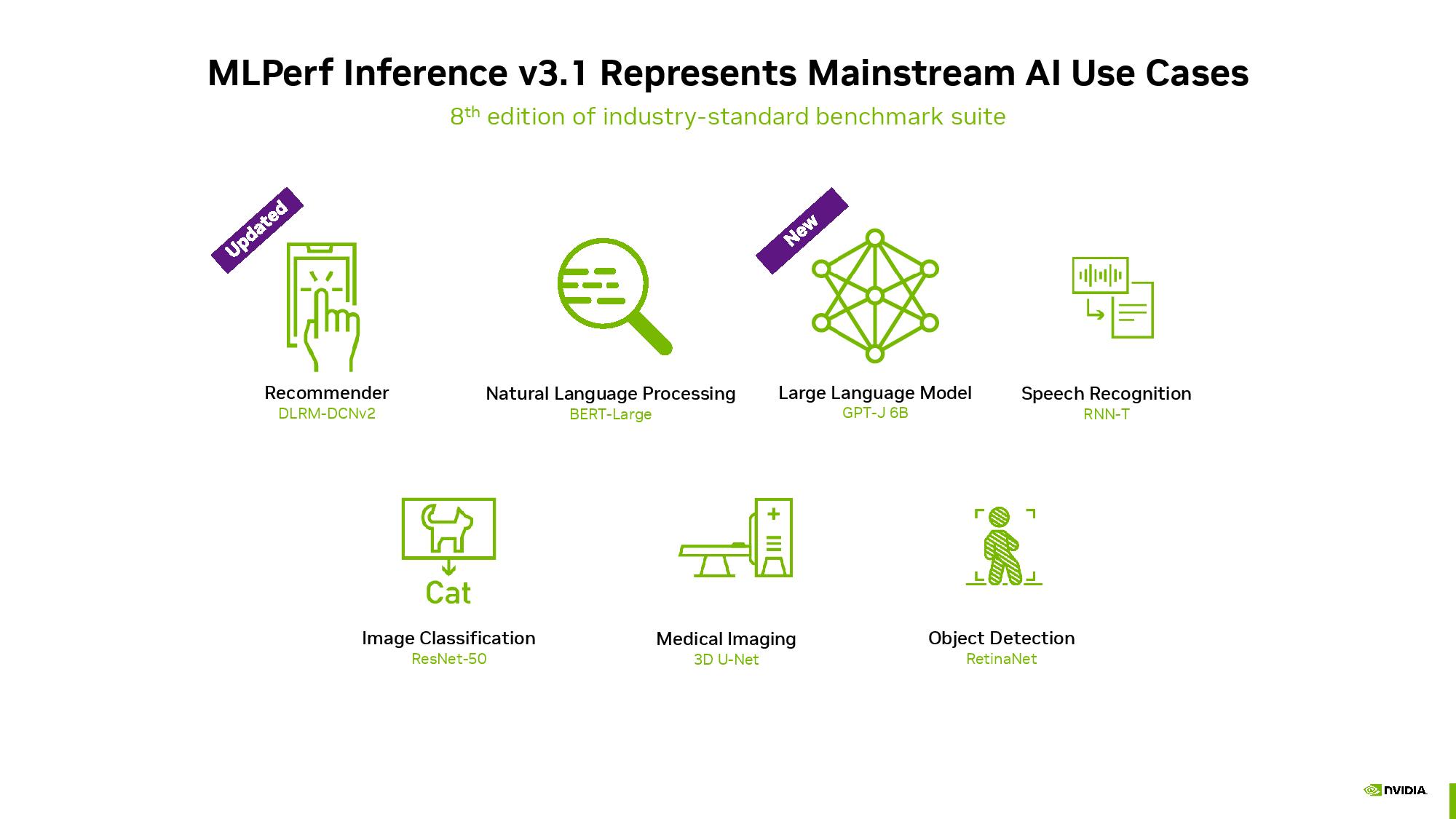
本日のベンチマーク結果では、MLPerfベンチマークにとって初めてとなる2つの注目すべき結果が示されました: それは、新しい大規模言語モデル(LLM)GPT-J推論ベンチマークの追加と、刷新された推薦モデルである。
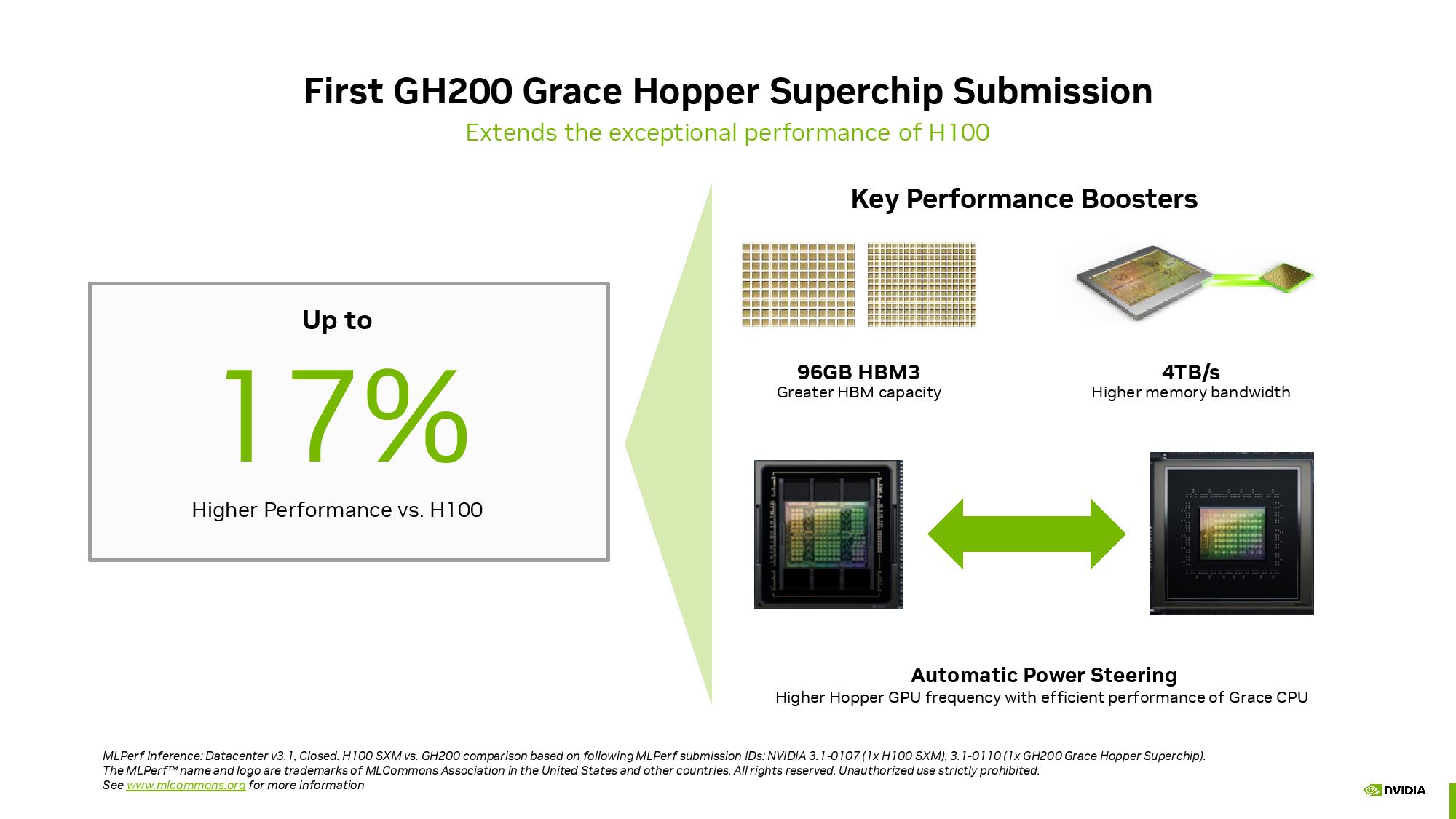
Nvidiaは、GPT-Jベンチマークにおいて、Grace Hopper Superchipが市場をリードするH100 GPUの1つよりも最大17%高い推論性能を発揮し、L4 GPUがIntelのXeon CPUの最大6倍の性能を発揮すると主張している。
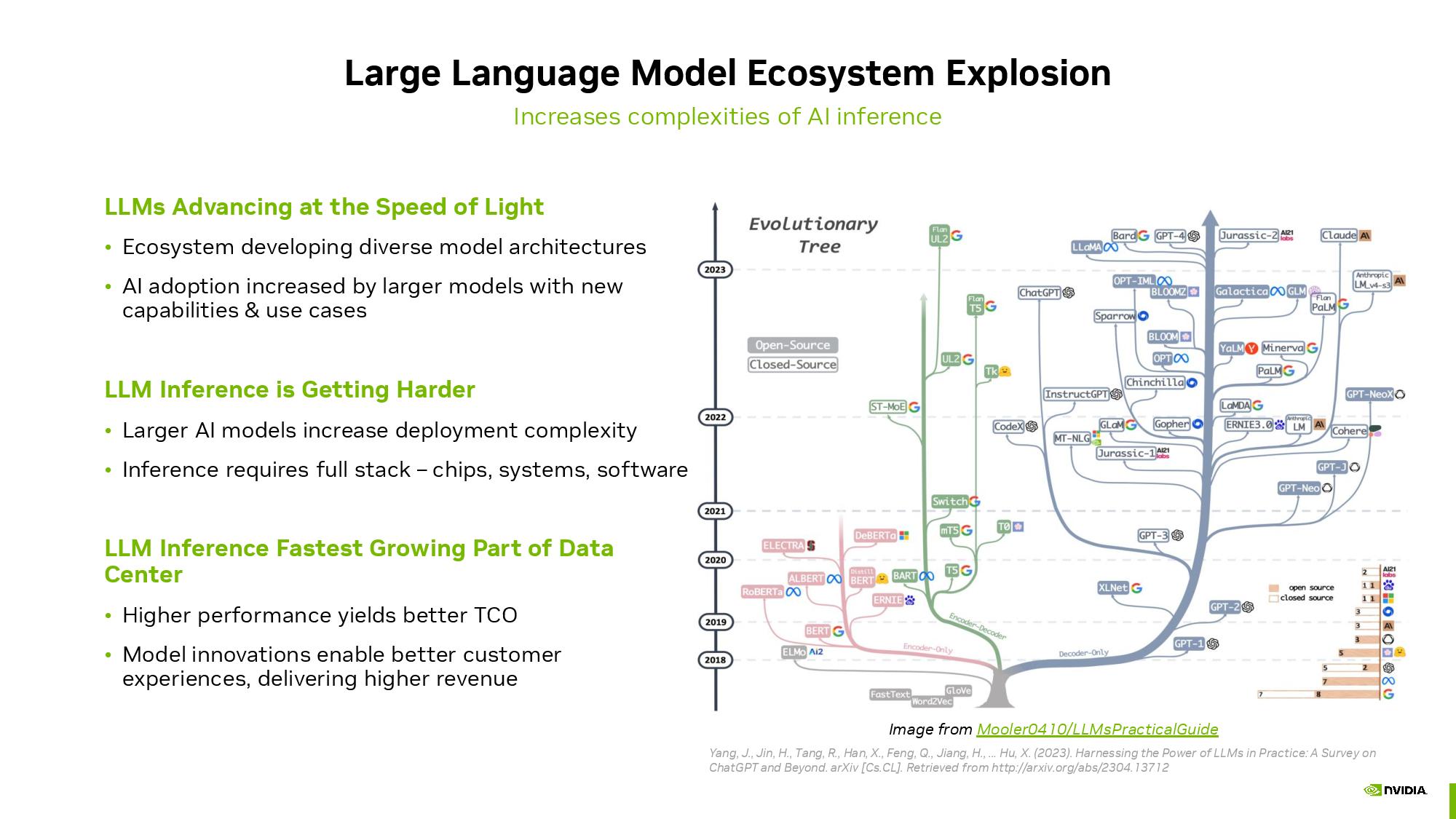
新しいAIモデルやより強力な実装への急速な進化に伴い、業界は猛スピードで動いています。
これと同様に、MLCommonsによって管理されているMLPerfベンチマークも、新しいv3.1改訂版によって、AIランドスケープの変化をよりよく反映するために常に進化しています。
GPT-J 6Bは、2021年以来実世界のワークロードで使用されているテキスト要約モデルで、現在MLPerfスイート内で推論性能測定のベンチマークとして使用されています。
60億パラメータのGPT-J LLMは、1750億パラメータのGPT-3のような、より高度なAIモデルと比べるとかなり軽量ですが、推論ベンチマークの役割にはうまく適合しています。
このモデルはテキストブロックを要約し、レイテンシに敏感なオンラインモードと、スループットを重視するオフラインモードの両方で動作します。
MLPerfスイートはまた、2倍のパラメータ数を持つより大規模なDLRM-DCNv2推薦モデル、より大規模なマルチホットデータセット、実環境をよりよく表現するクロスレイヤーアルゴリズムを採用しています。




※ 画像をクリックすると別Window・タブで開きます。
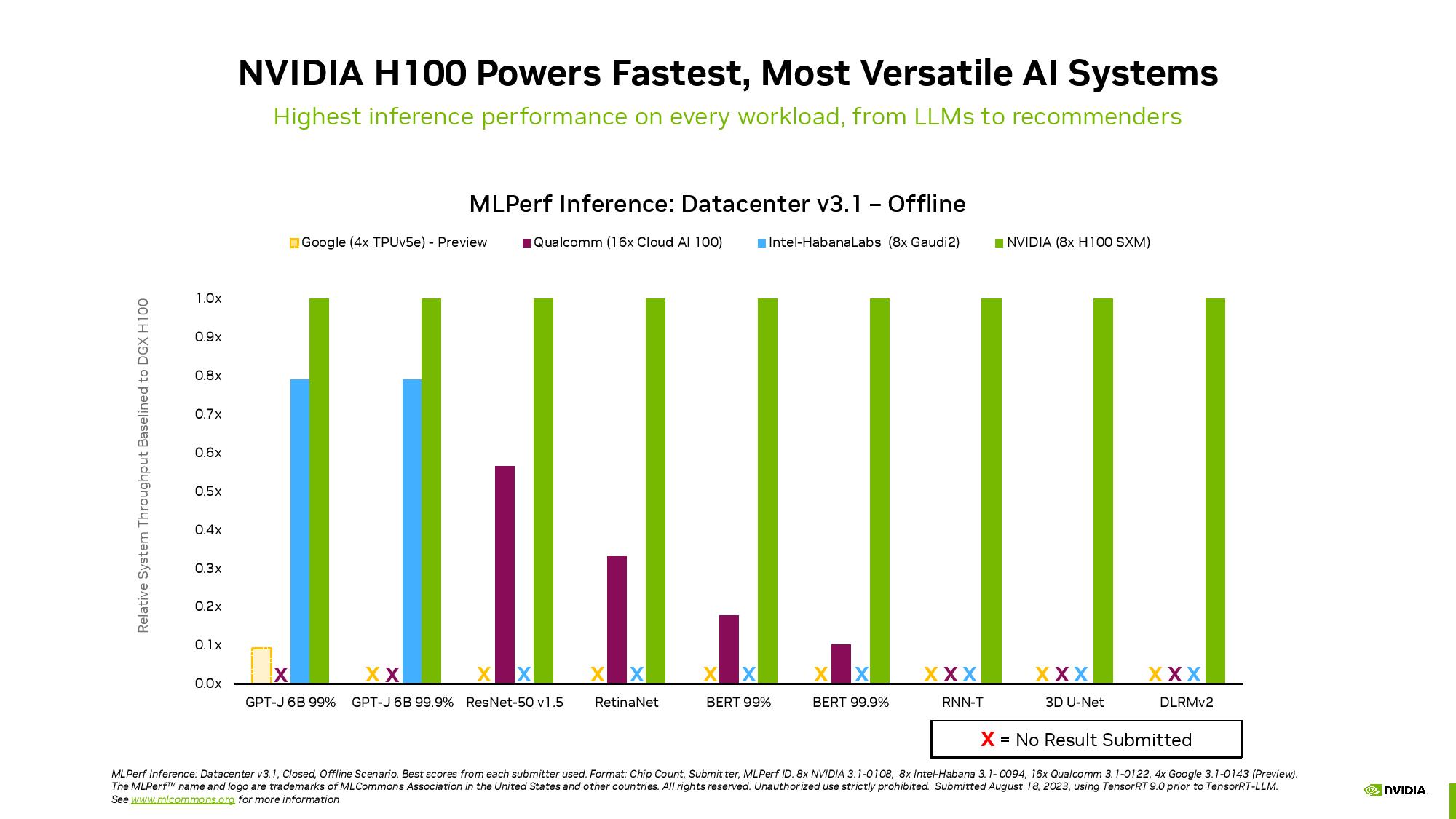
このような背景から、Nvidiaの性能に関する主張の一部をここで見ることができる。
Nvidia自身がこれらのベンチマークをMLCommonsに提出しているため、おそらく高度に調整された最良のシナリオを表していることに注意してください。
Nvidiaはまた、MLPerfスイートで使用されているすべてのAIモデルのベンチマークを提出した唯一の企業であることを指摘したがります。
AMDのようにベンチマークを提出しない企業もあれば、HabanaのIntelやTPUのGoogleのように数種類のベンチマークしか提出しない企業もある。
提出が少ない理由は企業によって異なりますが、より多くの競合企業がMLPerfの土俵に上がることは喜ばしいことです。
Nvidiaは、初のGH200 Grace Hopper Superchip MLPerfの結果を提出し、CPU+GPUのコンボがH100 GPU単体よりも17%高い性能を発揮していることを強調した。
GH200がH100 CPUと同じシリコンを使用していることを考えると、表面的には驚くべきことだが、その理由は後述する。
当然のことながら、H100を8基搭載したNvidiaのシステムは、Grace Hopper Superchipを凌駕し、すべての推論テストでリードを奪った。
備考として、グレース・ホッパー・スーパーチップは、ホッパーGPUとグレースCPUを同じボード上に統合し、2つのユニット間に900GB/秒のスループットを持つC2Cリンク(詳細はこちら)を提供するため、CPUからGPUへのデータ転送に一般的なPCIe接続の7倍の帯域幅を提供し、96GBのHBM3メモリと4TB/秒のGPUメモリ帯域幅を含むコヒーレント・メモリ・プールによって増強されたGH200のアクセス可能なメモリ帯域幅を向上させます。
対照的に、HGXでテストした比較対象のH100は、80GBのHBM3しか搭載していない(次世代Grace Hopperモデルは、2024年第2四半期に144GBの1.7倍高速なHBM3eを搭載する予定)。
Nvidiaはまた、Automatic Power Steeringと呼ばれるダイナミックパワーシフト技術もアピールしている。
これは、CPUとGPU間のパワーバジェットを動的にバランスさせ、負荷が最も高い方のユニットにスピルオーバーバジェットを配分するものだ。この技術は、競合する最新のCPU+GPUコンボの多くで使用されているため、目新しいものではないが、グレース・ホッパー・スーパーチップに搭載されたGPUは、グレースCPUから電力がシフトされるため、HGXよりも高い電力供給バジェットを享受することができる。
CPU+GPUのフルシステムはTDP1000Wで動作した。
L4のような小型の低消費電力GPUでこれらのワークロードのCPUを置き換えることは、大量販売の原動力となるため、Nvidiaにとって最も重要なことである。
今回のMLPerfでは、NvidiaのL4 GPUに関する初の結果も発表されており、推論に最適化されたカードは、補助電源接続を必要としないスリムなフォームファクタのカードでわずか72Wにもかかわらず、GPT-J推論ベンチマークでシングルXeon 9480の6倍の性能を発揮している。
Nvidiaはまた、8個のL4 GPUと2個の旧世代Xeon 8380s CPUの性能を測定することで、ビデオ+AIデコード-推論-エンコードのワークロードでCPUに対して最大120倍の性能を発揮すると主張しているが、これは少し不利だ。これはおそらく、1つのシャーシに詰め込むことができる膨大なコンピューティングパワーを直接比較することを意図したものだろう。
それでも、この仕事に最適ではないにもかかわらず、クアッドソケット・サーバーが利用可能であることは注目に値するし、新しいXeonチップはおそらくこのテストでもう少し良いパフォーマンスを発揮するだろう。
テスト構成はスライド下部の小さな活字に記載されているので、細部に注意してほしい。
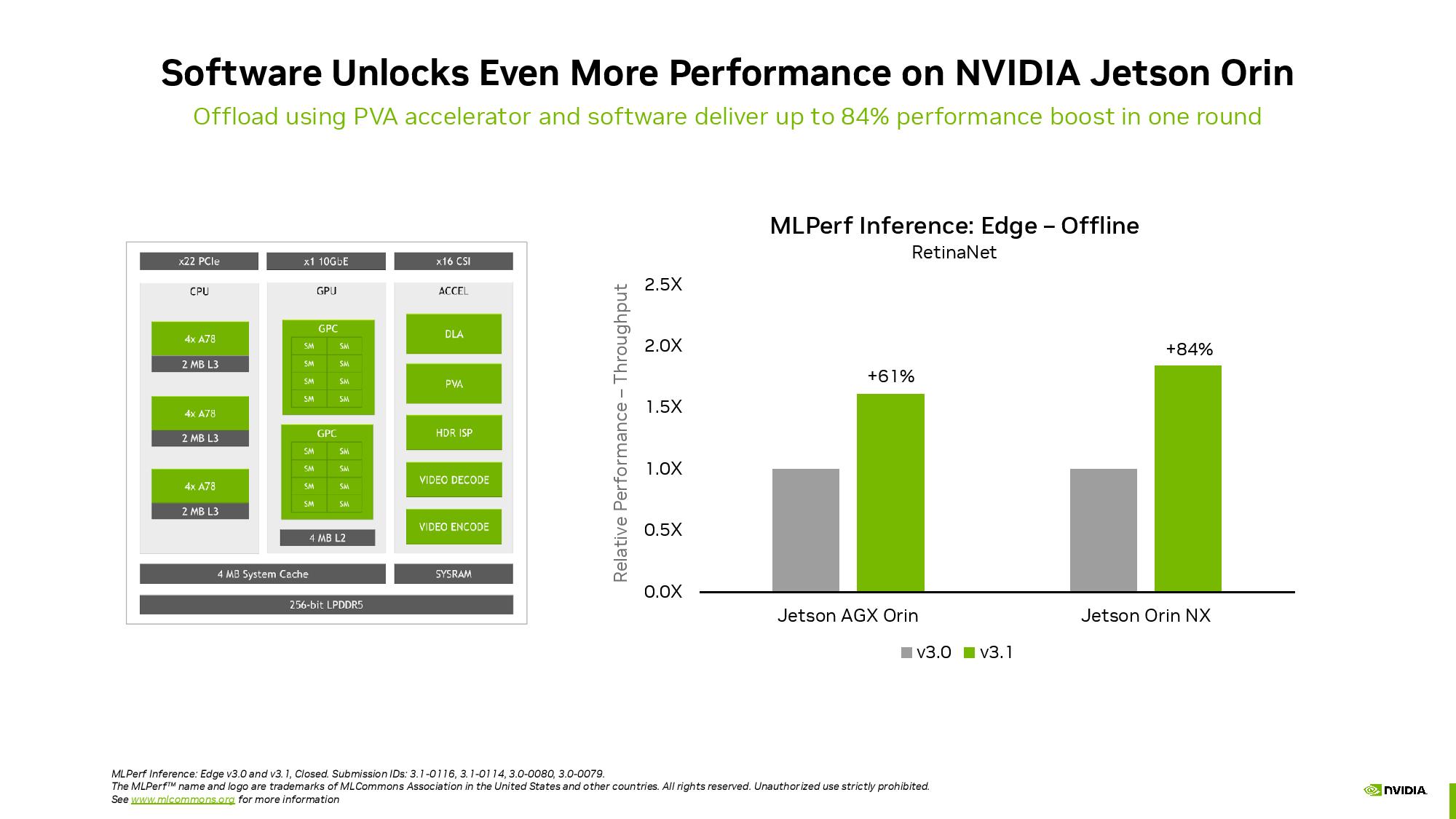
最後に、NvidiaもJetson Orinロボットチップのベンチマークを提出し、ソフトウェアの改善によって推論スループットが84%向上したことを示した。







※ 画像をクリックすると別Window・タブで開きます。
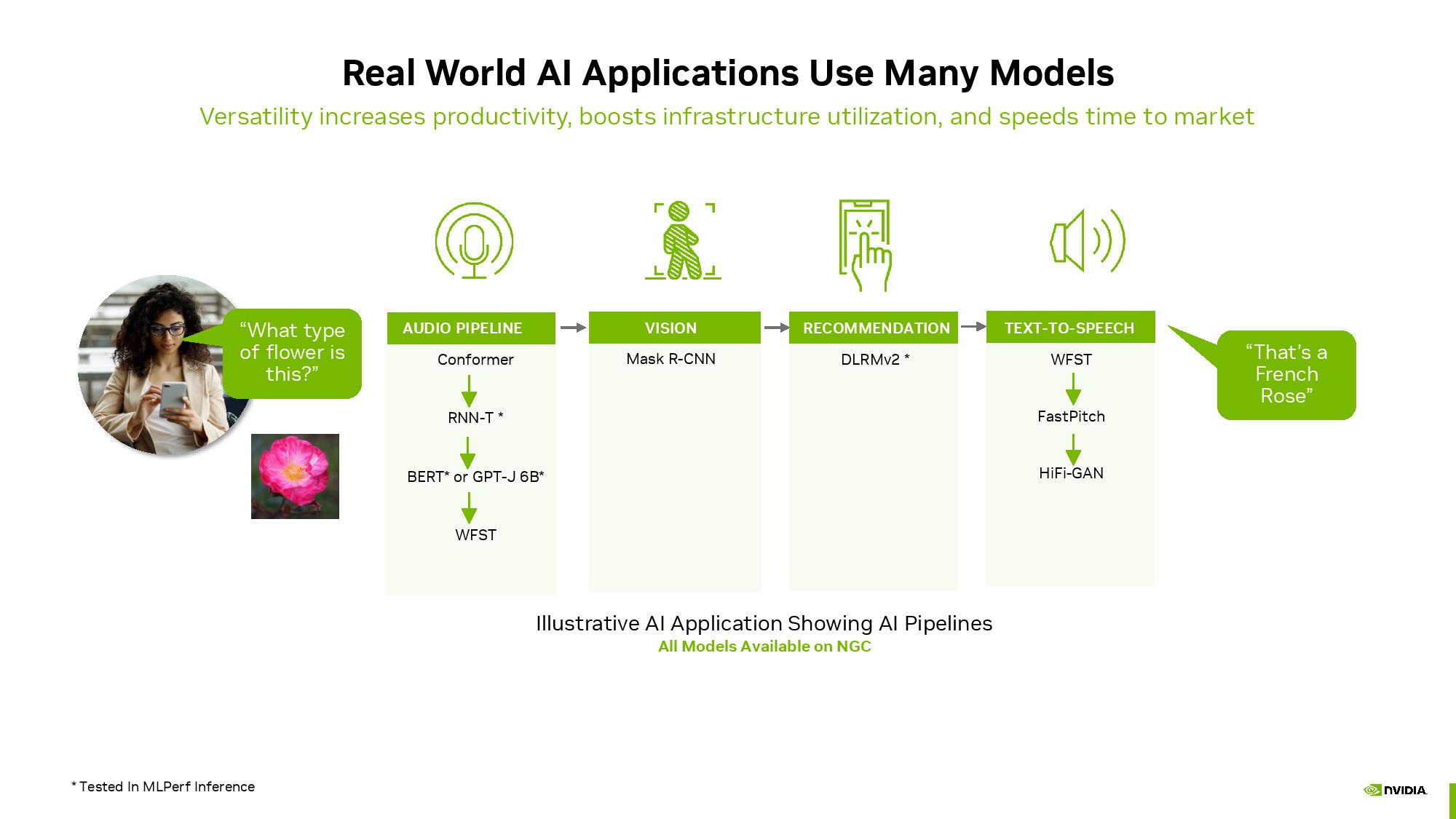
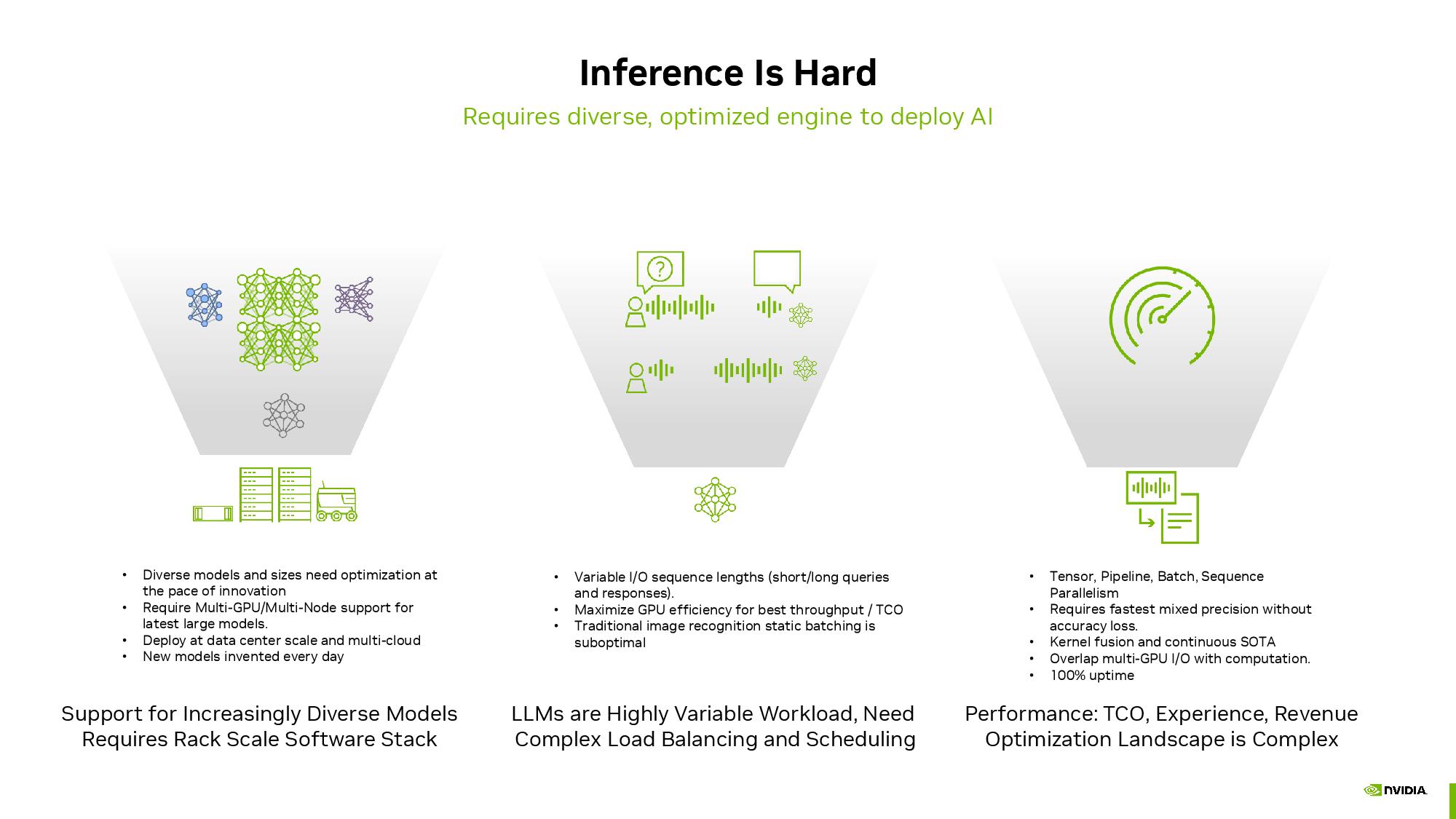
現実の世界では、各AIモデルは、特定のジョブやタスクを達成するためにAIパイプラインで実行される、より長い一連のモデルの一部として実行されることを覚えておくことが重要です。
上のNvidiaの図解はこれを見事に表現しており、1つのクエリに対して8つの異なるAIモデルが実行され、完了します。この種のAIパイプラインでは、1つのクエリを満たすために最大15個のネットワークが拡張されることも珍しくありません。
上記のスループット重視のベンチマークは、単一のAIモデルを高い稼働率で実行することに重点を置く傾向があるため、これは重要な文脈である。現実のパイプラインは、与えられたタスクを完了するために複数のAIモデルをシリアルに実行し、かなり多用途性を必要とするのとは対照的である。
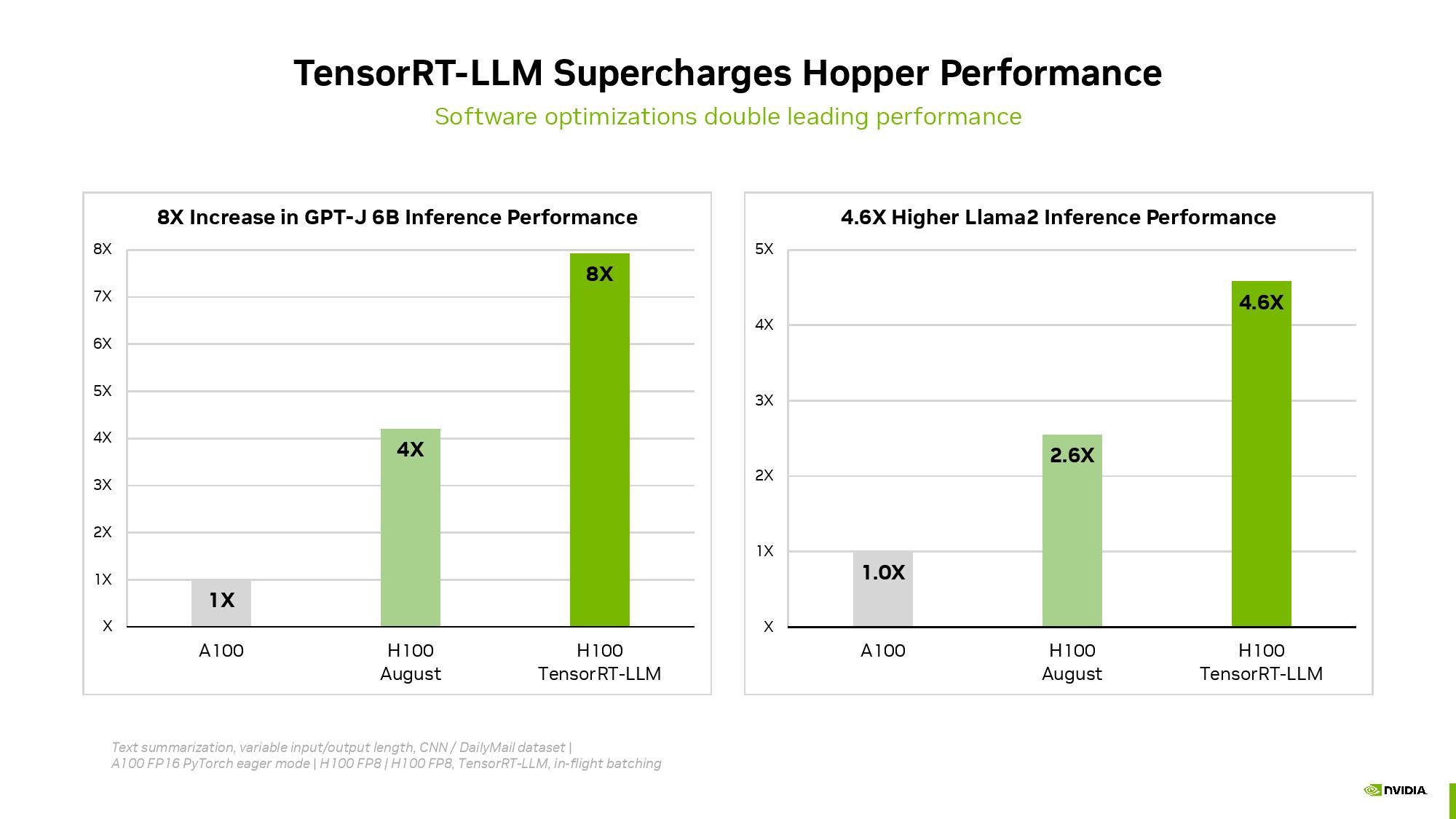
Nvidiaはまた先週、生成AIワークロード用のTensorRT-LLMソフトウェアが推論ワークロードで最適化されたパフォーマンスを提供し、H100 GPUで使用した場合、追加コストなしで全体的に2倍以上のパフォーマンスを実現すると発表した。MLCommonsはMLPerfの提出に30日のリードタイムを要求しており、TensorRT-LLMはその時点では利用できなかった。つまり、NvidiaのMLPerfベンチマークの初回ラウンドは、次の提出ラウンドで飛躍的な改善が見られるはずだ。
ソース:Tom's Hardware - Nvidia Submits First Grace Hopper CPU Superchip Benchmarks to MLPerf
解説:
nVIDIAはゲーミングGPUの売り上げがあまりに良くないので、ゲーム用の人員を減らしてAI/MLチップに力を入れていくという話が出ていますが、それを裏付けるような話ですね。
なんでもAI/ML用のチップは利益率900%などと言う噂も聞こえてきます。
それでも飛ぶようにうれるのですから、ゲーミングGPUなんてやるの馬鹿らしくなるのかなと思います。
将来的には利益率の高い一部の上級モデルのみを残して後は出さなくなるかもしれませんねえ。
AI/MLがマイニングなどの「空虚な需要」と違って安定して続くと思うのはAI/MLの成果物が生産性向上にに直結しているからです。
「メタバース」も今のところ一般向けの幅広い生産性向上に直結するような技術やサービスが出ているようには見えません。
それらと比べても非常に有望だと思います。
また、応用分野は幅広く、法的・倫理的・道徳的な問題を解決するか社会的な合意が得られれば、恐らくもっと大きく飛躍することは想像に難くありません。
記事ではnVIDIAがMLPerfスコアを提出したことがかかれていますが、企業によっては一部の結果しか出していないそうでこの辺にnVIDIAの自信のほどかうかがえるのかなと思います。
Radeon Instinctシリーズも理論値ではnVIDIA製品を上回っていても、実際に回すと勝ってないなどと言う話も聞きます。
やはりこの分野ではnVIDIAに一日の長があるのかなと思います。