※ わかりにくいと思われる個所をいくつか訂正しました。
より高速に動作させられるROCm版の記事はこちらです。(OSはLinuxです。)
更新:Pytorch 2.0.0に対応しました。
先日の失敗の記録を公開したところ、Pythonのバージョンを上げれば動くよと言う話を「通りすがり」氏がコメントで教えてくれたので、さっそくやってみたところ、なんと無事に動作しました。
今回は動作記念ということで、ハローアスカベンチマークを動かしてみました。
先にお断りしておきます。
残念ですが、Geforceなどで既に公開されているものと全く同じ絵は出てきませんでした。
理由は分かりません。
Stable diffusion WebUIで鉄板とされているPythonのバージョンは3.10.6なので、3.10.10に上げたからなのか、DirectMLだからなのか・・・。
動作環境です。

- CPU:Intel Core i7-13700K
- CPUクーラー:サイズ Big shuriken3 RGB
- マザーボード:Asrock Z690M-ITX/ax
- SSD:M2_2(チップセット側) AGI NVMe Gen3(システムドライブ)
- M2_1(CPU側) Moment MT34 NVMe Gen3 SSD 256GB(今回は使用していません)
- 電源:Corsair SFX 750W電源 SF-750
- メモリ:Patriot Viper DDR4-3000 OCメモリ8GB*2=16GB
- ケース:QDIY 0040-*PCJMK6-ITX(テストベンチ)
- OS:Windows11 22H2(最新Windows Update適用済)
- GPU Sapphire Pulse Radeon RX7900XTX 24GB
Stable Diffusion WebUIはSAN ZANG MASTER NVMe-USB3.2 Gen2X2 アルミエンクロージャー BLM20Cを使って接続したWINTEN WTPCIe-SSD-256GBにて使用しています。
ほぼNVMe Gen3 SSDで使うのとそん色ないスピードが出ています。
一番時間がかかるのはModelデータの読み込みですが、保存場所が遅いと読み込みに時間がかかって快適ではなくなるので、ストレージの速度は重要だと思います。
モデルデータはかなり容量が大きいですから、シーケンシャルリードの値がものを言うと思います。
20Gbps対応品やお金を持っている人はThunderblot3接続のUSBエンクロージャを使うと快適だと思います。
今回私は既に公開されているGeforce版を自分でカスタマイズしたポータブル版のStable Diffusion WebUI DirectMLを使っています。
ベンチマークの後にポータブル版Stable Diffusion WebUI DirectMLを使い方と一緒に公開します。
手持ちでGeforceもいくつか持っていますが、比較しても仕方ないほどかけ離れた性能なので、近い性能のものをネットから拾ってきて比較対象にします。
ハローアスカベンチマークとは
ハローアスカベンチマークはモデルデータが多数公開されている有名サイトhuggingfaceにあるanimefull-final-prunedを使って一定の条件で10枚のイラストを生成する時間で性能を測るベンチマークです。
先にお断りしておきますが、この生成されるイラストはほぼ同一になるような条件で公開されています。
しかし、今回私が公開するポータブル版では同一になりませんでした。
理由はわかりません。
それを前提に読んでください。
通常で生成されるイラスト
Batch Count 1,Batch Size1(設定が正常かどうか確認する画像)

Batch Count 10,Batch Size 1(ベンチマーク)

DirectML ポータブル版で生成されるイラスト
Batch Count 1,Batch Size1(設定が正常かどうか確認する画像)

Batch Count 10,Batch Size 1(ベンチマーク)
はい、全然違います。
これを前提にしてください。
設定はWikiの画像から読み込んでいますので、間違いありません。
RX7900XTXの結果です。
Time taken: 55.45sでした。
ちなみに、DirectML版は画像の生成速度を上げるオプション「--xformers」が使えません。
画像生成後に表示されるメッセージを全て張り付けておきます。
masterpiece, best quality, masterpiece, asuka langley sitting cross legged on a chair
Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name
Steps: 28, Sampler: Euler, CFG scale: 12, Seed: 2870305590, Size: 512x512, Model hash: 89d59c3dde, Model: model-001, Clip skip: 2, ENSD: 31337
Time taken: 55.45s
他に比較対象としてRTX3060とRTX4070Tiも測定しました。
以下が結果になります。
※ 「結果(秒)」の数字が小さい方が速い
| GPU | ベース | 結果(秒) | 備考 |
| RX7900XTX | DirectML | 55.45 | |
| RX7900XTX | DirectML (torch2.0.0) | 49.11 | |
| RTX3060 | DirectML | 162.9 | |
| RTX3060 | CUDA | 49.21 | xformer無し |
| RTX3060 | CUDA | 42.27 | xformerあり |
| RTX4070Ti | DirectML | 66.64 | |
| RTX4070Ti | CUDA | 38.87 | xformer無し |
| RTX4070Ti | CUDA | 32.48 | xformerあり |
DirectML版のオプション=--autolaunch --no-half --always-batch-cond-uncond --opt-sub-quad-attention
DirectML torch2.0.0版のオプション=--autolaunch --opt-sdp-attention --opt-sdp-no-mem-attention --no-half --always-batch-cond-uncond --opt-sub-quad-attention
CUDA版のオプション=--autolaunch --xformers(ただし、あり、無し両方でテストしています。)
面白いのはDirectMLは綺麗に性能順に並んでいるところです。
RX7900XTXがRTX4070Tiに勝っているのは痛快でした。
DirectML版の画像は全てCUDA版とは違った画像だったので(ただし3種類とも上に上げたものです。)違った画像が出てくるのはDirectML版固有の問題のようです。
→DirectML版はCPUとして認識されているようです。ただし、きちんとGPUを利用しています。
WIKIではROCm(Linux)上での結果がRX6900XTで34.51秒ですから、RX7900XT/XTX対応のROCmが出ればかなり良いタイムが期待できるのではないでしょうか?
RX7900XTXのStable-Diffusion WebUI DirectMLの性能はRTX3060 12GBにも及ばないという残念な結果になりました。
もう少しDirectML版のアップデートが進み最適化されればまた変化が出てくることを期待したいです。
しかし、やはり、Radeonの本命はROCm上での性能だと思います。
ここはAMDさんにRDNA3対応のROCmを早く出していただけることを期待してベンチマークの報告を終えたいと思います。
→Linux用のROCm 5.5がリリースされましたので、早速導入方法を説明しています。
ストレージの速度によるモデル読み込みの変化
今回私は自分でカスタマイズしたポータブル版をUSB3.2Gen2x2対応のエンクロージャに入れて運用しました。
SAN ZANG MASTER NVMe-USB3.2 Gen2X2 アルミエンクロージャー BLM20C
丁度良かったので、USB3.2Gen2x2(20Gbps)とUSB3.2Gen2(10Gbps)とUSB3.2Gen1(5Gbps)でモデルデータの読み込み速度に変化があるかどうかテストしてみました。
テストに当たっては起動時にコンソールに出てくるload SD checkpointの秒数を基準としています。
読み込みモデルデータrevanimated_reval1.safetensors 7.17GB
- 20Gbps・・・9.7秒
- 10Gbps・・・10.7秒
- 5Gbps・・・16.1秒
という結果になりました。
5GbpsがSATA SSDの結果と考えてよいでしょう。
20Gbpsはかなり速いと思っていたのですが、実は10Gbpsとそんなに差が無くて少しがっかりしたのは内緒です。
5Gbpsでもそこそこのスピードなので、待てないほど遅いというわけではありませんが、Stable-Diffusion WebUIのモデルデータは巨大なサイズのものが大半ですので、出来るだけ速いストレージで実行したほうが良いです。
DirectML ポータブル版Stable-Diffusion WEBUI配布
Google検索 - automatic1111 スタンドアローンセットアップ法・改
上の「automatic1111 スタンドアローンセットアップ法・改」を元に私がDirectML版が動作するように改造したものです。
こちらを配布します。
Radeonだけではなく、Geforceでも動作します。(ただし、CUDA版の方が圧倒的に早いのと同じ条件でも出てくるイラストが違いますのでこちらを使う意味はありません)
恐らくIntel ARCの単体GPUやRenoir、Cezanneの内蔵GPUでも動くと思います。
Renoir、Cezanneの内蔵GPUはメモリ16GBだと8GB、32GBだと16GBまで内蔵GPUにメモリを割り当てられるようですので、興味のある方はチャレンジしてコメントで結果を教えていただけると嬉しいです。
※ ポータブル版って意味あるの?
PythonやGitをインストールしない(環境を汚さない)と言うのが一番のメリットです。特定の環境で作ったポータブル版のWebUIは他の環境では動かなかったので、汎用性と言う点ではあまり意味が無いです。例えばあなたの構築した「DirectML ポータブル版Stable-Diffusion WEBUI」は友達のA君の家のパソコンでは実行できません。してもエラーが出て止まります。新しい環境ではセットアップから始める必要があります。
また、申し訳ありませんがアップデートが入ると動作しなくなる可能性があるのでその旨お断りしておきます。
ROCmが出たら、また改めてセットアップスクリプトを配布する予定なので、DirectML版はそれまでのつなぎです。
特徴
- git、pythonのインストールは必要ありません。
- PCのどこに置いてもOKです。出来るだけ高速なSSDにおきましょう。
- ダブルクリック一発でセットアップ・実行します。
- ハローアスカベンチマークに必要なモデルデータを自動でダウンロードしますので、ワンタッチでハローアスカベンチマークが実行できます。
※ 注意、セットアップ直後の状態で10GB前後の容量が必要になります。
ダウンロードと展開
DirectML ポータブル版Stable-Diffusion WEBUI
※ 更新:Pytorch2.0.0対応版
上のリンクをクリックしてください。
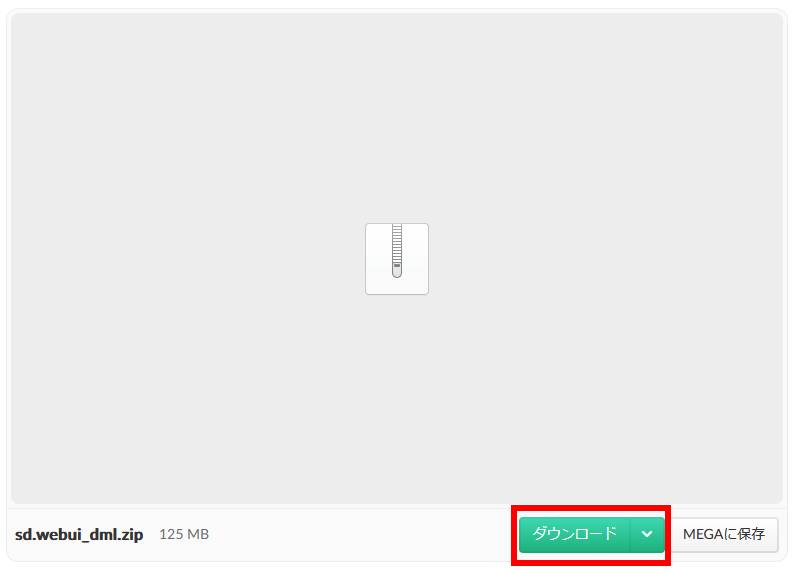
すると別Window・タブで上のようなページが開きます。赤線で囲った「ダウンロード」をクリックしてしばらく待つと「sd.webui_dml .zip」ファイルが「ダウンロードフォルダ」にダウンロードされます。
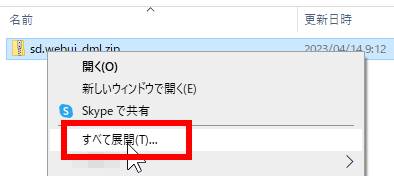
「sd.webui_dml .zip」ファイルの上で右クリックしてメニューを表示させ上の赤線で囲った部分の「すべて展開(T)」をクリックしてください。
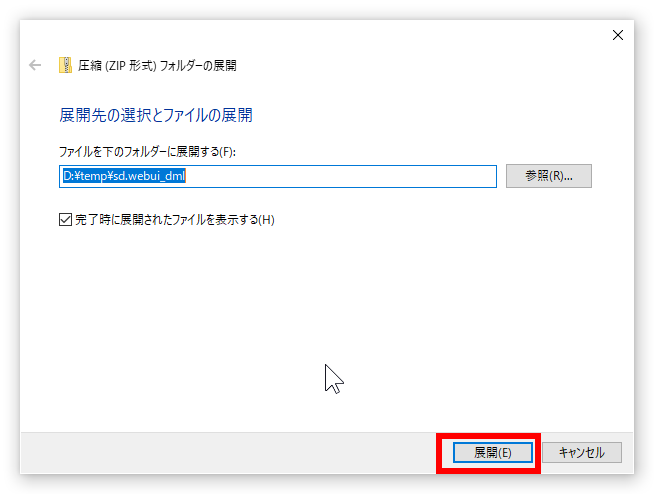
上の画像のようなウィンドウが出てきますので赤線で囲った「展開(E)」をクリックしてください。

暫く待つと展開処理が終わり、上の画像のように展開されたフォルダがエクスプローラーで表示されます。
インストール
展開されたフォルダが表示されたエクスプローラーで上の画像のように赤戦で囲った矢印の部分がありますのでクリックしてください。
上のように表示されますので、「sd_webui_dml」フォルダを自分の好きな場所にコピペ(もしくは切り取り、貼り付け)してください。
インストール場所は空き容量が大きく、速度が速いドライブでパス名はあまり長くない方がいいです。
「パス名があまり長くない」の意味が解らない方はドライブの直下においてください。
パス名の間にスペースが入っていたり、全角文字が入って「いない」方がいいです。
「sd_webui_dml.zip」は失敗してやり直すときに使いますので、保管しておいてください。
環境構築
移動した「sd_webui_dmlフォルダの中身を見てください。
上のようになっていると思います。
「1_セットアップ.bat」をダブルクリックしてください。
※ ハローアスカベンチマークの実行に必要なモデルデータを持っている方は「1.セットアップ.bat」の39行(折り返し無しの場合)「bitsadmin /transfer ・・・」で始まる行をコメントアウトしてください。データのダウンロードに20分くらいかかる場合がありますので大幅にセットアップ時間を縮めることが出来ます。意味が解らない方はそのままでいいです。
上のような画像が出てきます。

上のようにy(小文字・半角)を入力して「Ener」キーを押してください。
自動でセットアップが始まり、終わるとStable Diffusion WEBUIが起動します。
Radeon向けのオプションが最初から入っています。
※ 他のGPUの方は申し訳ありませんが、ご自分で最適なオプションを探してみてください。
セットアップには最低20分、最新のPCでない、もしくは回線が遅い場合、もっとかかる可能性が高いですので気長に待ってください。
なお、Stable Diffusion WEBUIが起動するとブラウザのほか、上の黒い画面(コマンドプロンプト)がずっと表示され続けますが、閉じないでください。
ブラウザが操作パネルで黒い画面(コマンドプロンプト)がプログラム本体です。
黒い画面(コマンドプロンプト)を閉じてしまうと動かなくなります。
2回目以降は「2_スタート_webui-user.bat」を実行してください。
DirectMLワンタッチ版は「webui-user.bat」ではなく、「1_セットアップ.bat」と「2_スタート_webui-user.bat」に直接オプションを記述します。
折り返し無しで「1_セットアップ.bat」は50行目に、「2_スタート_webui-user.bat」は48行目にオプションを記述します。
何れも「set COMMANDLINE_ARGS=」で始まる行があるはずです。
「1_セットアップ.bat」はセットアップの一回目にしか使いませんので、面倒な場合、「2_スタート_webui-user.bat」のみ書き換えてもよいです。
使い続けていくうちにもし動かなくなったら「3_通常更新 (git pull).bat」をダブルクリックしてみてください。
※1 わかる人向けの注意、repositoryディレクトの中身はsubmoduleとしてファイルを引っ張る必要があるようなのですが、今回の環境ではリカーシヴオプションを付けてcloneしても中身が落ちてこないためやむを得ずtmpに中身を展開したものを用意してコピーするという強引な手法をとっています。将来的なアップデートで動かなくなる可能性があることは理解しておいてください。自己解決できる方は自分で解決してください。
※2 CUDA版はpython3.10.6で普通に動きますが、DirectML版はpython3.10.10(最新)を使わないと動作しませんでした。よって将来的にまた同様の現象に見舞われる可能性がありますので注意を喚起しておきます。解決策はローカルにインストールしたpythonの最新版をそのままコピーして「DirectML ポータブル版Stable-Diffusion WEBUI」のpythonと中身を入れ替えるだけです。わかる人は対応してください。
ハローアスカベンチマークを実行する
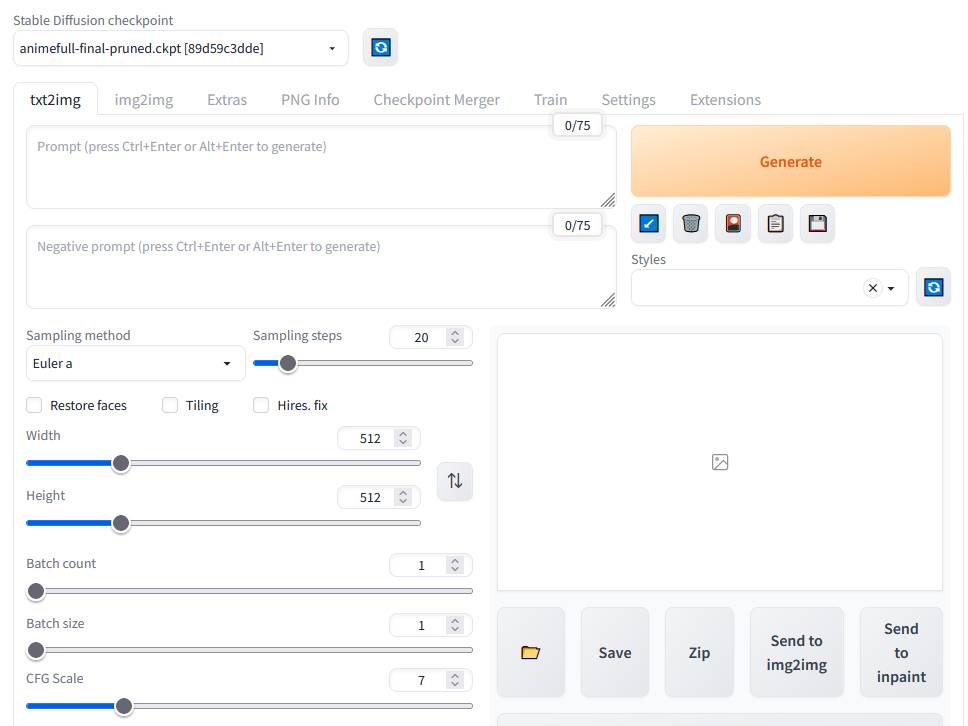
無事にStable Diffusion WebUIが起動したら、下のファイルをダウンロードして解凍してください。
解凍すると中に「Hello Aska.png」と言う画像ファイルファイルが入っています。
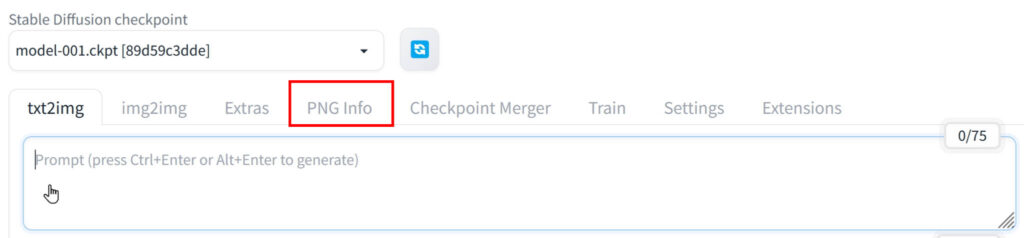
Stable-Diffusion WEBUI画面で赤線で囲った「PNG info」をクリックします。
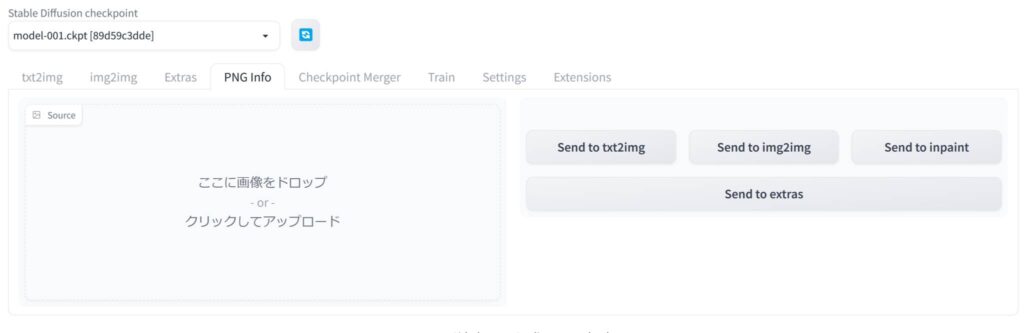
上の画像のような画面が出ます。
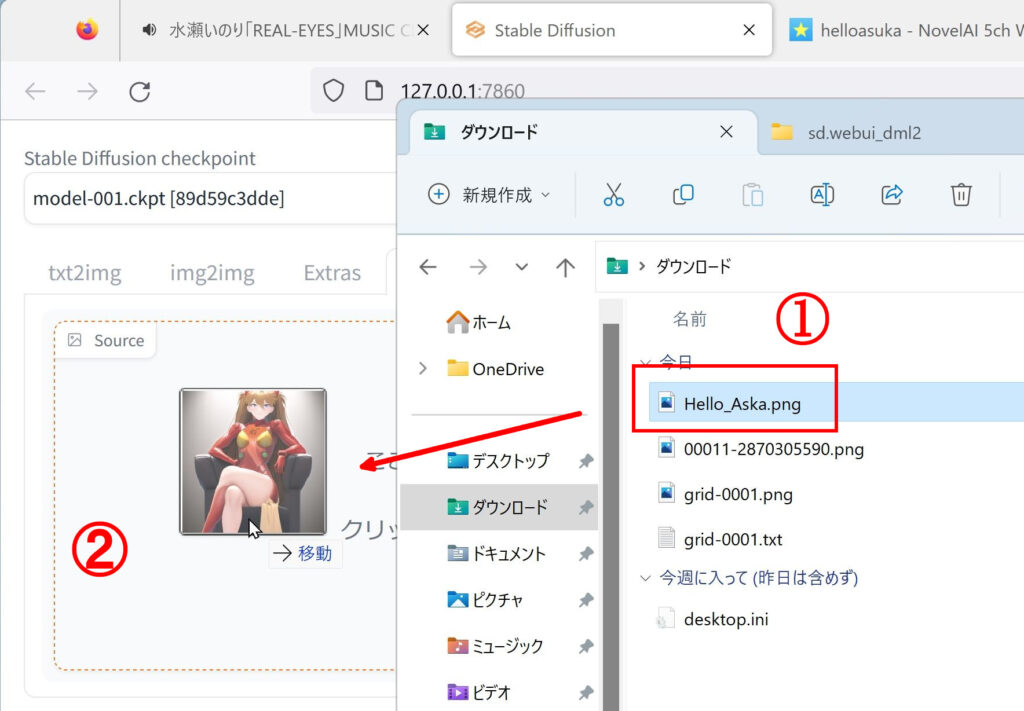
1.解凍して出てきた「Hello Aska.png」をドラッグして
2.PNG infoの画像を参考に所定の位置にドロップします。
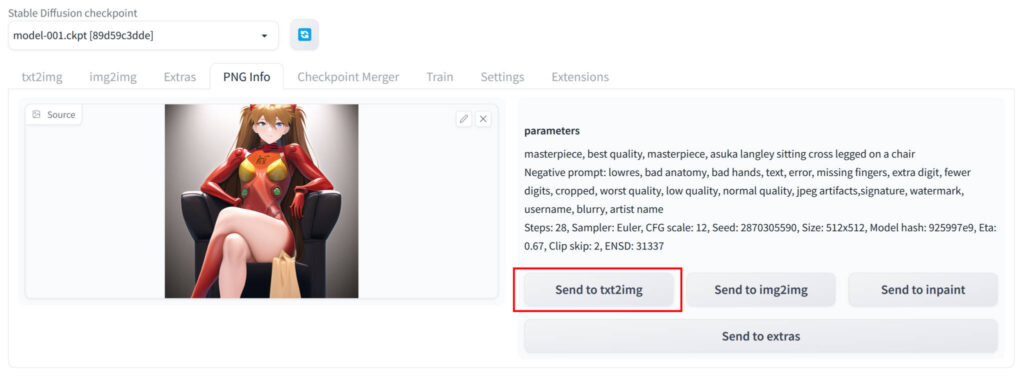
上の画像のような状態になったら赤線で囲った「Send to txt2img」をクリックします。
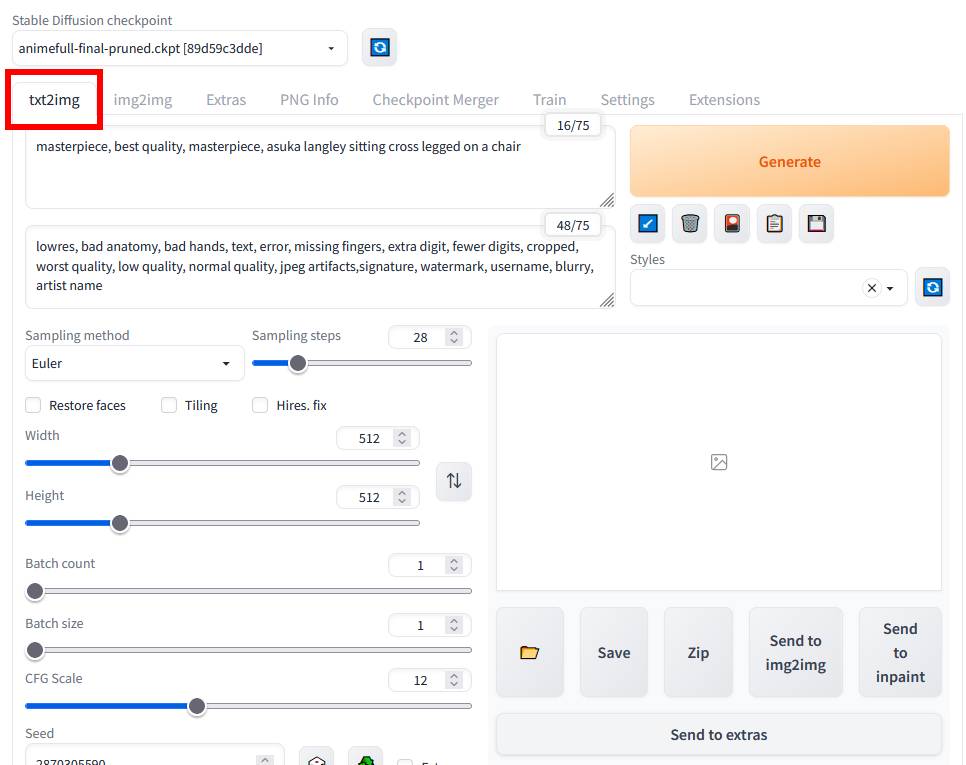
上の画像のように「txt2img」タブをクリックするとハローアスカベンチマークに必要なオプションが全て入力された状態になっています。
テスト画像が出力されます。
上に私がDirectML版で出力した画像があるので同じかどうか確認してください。

また「Batch Count」を10にしてから「Generate」をクリックするとベンチマークとなります。

結果は画像が表示されるエリアの下に表示されます。
下の方の赤線で囲った部分に「Tijme taken:32.33s」とあります。
これがタイムになります。
当然ですが、時間が短い方が速いです。
この記事にもいくつかタイムを掲載していますので、自分の結果がどの程度なのか比較してみましょう。
以上です。お疲れさまでした。
というわけで速度がイマイチですが、あなたのRadeon RX7900XT/XTXでもStable Diffusion WebUIが動きます。
今まで指をくわえてGeforceを見ていた方は思う存分イラストを生成してください。
ROCm版の方が速度も速く、生成されるイラストもCUDA版と同一と思いますので、そちらが出るまでのつなぎと言う風に理解してください。
正直、RadeonでイラストAIは茨の道だと思います。
敢えて茨の道を進む覚悟がある方向けにまた機会があれば役に立つ情報を発信しようと思います。
AMDさん、出来れば早くROCmのRDNA3対応版を公開してください。
全世界1億人(嘘)のRadeonファンが待っています。
今回の検証のGPUはこちらを使用しました。


