
IDM 2.0の基調講演において、インテル社のCEOであるパット・ゲルシンガー氏は、新しいプロセス・ロードマップと、次世代ノードの新しいネーミングスキームを発表しました。
この新しいロードマップは、2025年以降に製造・生産が開始されるすべてのノードとその製品を網羅しています。
インテル プロセス・ロードマップおよびイノベーション・ロードマップでは、「++」および「SuperFin」ブランドを取り除いた全く新しいノード・ネーミング・スキームを強調しています。
インテルは新体制になって全体的に再編が進んでおり、ここ数年混乱していたプロセスノードもようやく一般の人にも理解できるようになりそうだ。
インテルは最近、Ice Lakeチップで利用されているインテル10nm(++)ノードの強化型である10nm SuperFinプロセスノードを発表した。
現在、インテルはモバイルとデスクトップのプラットフォームに10nmと14nmの両方のチップを搭載していますが、今年後半にインテルがついにAlder LakeとSapphire Rapidsのラインナップを発表することで、この状況は変わりそうです。

※ 画像をクリックすると別Window・タブで拡大します。
IDM2.0では、当社の工場ネットワークが継続的に機能しており、現在では10nmのウェハーの製造数が14nmのウェハーの製造数を上回っています。10nmの生産量が増加するにつれ、経済性も向上し、10nmのウエハーコストは前年比で45%低下しており、今後もさらなる改善が見込まれます。
インテルより
インテル 7 プロセスノード(従来は10nm Enhanced SuperFin)
まず最初にご紹介するのは、10nm Enhanced SuperFinプロセスノードの新しい名称である「Intel 7」です。
このノードは、インテルのAlder LakeクライアントとSapphire Rapidsサーバーのラインナップに搭載される予定でした。
インテルが発表した内容によると、このノードは10nm SuperFinに比べて1ワットあたり10~15%の性能向上を実現し、FinFETトランジスタの最適化を特徴としています。
インテル 7は、2021年第4四半期までに量産体制が整い、最初の製品が市場に投入される予定です。
インテル 7は、FinFETトランジスタの最適化に基づき、インテル 10nm SuperFinと比較して、ワット当たりの性能が約10%から15%向上しています。
インテル7は、2021年にクライアント向けの「Alder Lake」、2022年第1四半期に生産開始が予定されているデータセンター向けの「Sapphire Rapids」などの製品に搭載されます。
インテル4のプロセスノード(従来は7nm)
Intel 4は、これまで同社が7nmプロセスノードと呼んでいたものです。
このノードは、Ponte Vecchio(ポンテベッキオ)をはじめとするいくつかの次世代製品に搭載されており、クライアント向けのMeteor Lake(メテオレイク)やデータセンター向けのGranite Rapids(グラナイトラピッズ)と並んで、大いに注目されているノードです。
インテルは、インテル4がインテル7に比べてワットあたりの性能を20%向上させると主張しています。これらに加えて、Intel 4は10nmと比較して以下のような優れた機能強化を実現しています。
- インテル7に対して2倍の密度スケーリング
- 計画されているノード内の最適化
- デザインルールの4倍削減
- EUV
- 次世代フォベローズとEMIBパッケージ

このノードでは、EUVリソグラフィを駆使し、前四半期にテープアウトされたMeteor Lake Compute Tileなどの製品がすでにテープアウトされています。
Granite Rapidsもマルチコンピュートタイルデザインを採用しており、そのメインとなるGranite Rapidsコアは、インテル4ノードで製造されます。
インテル4は、EUVリソグラフィーを全面的に採用し、超短波長の光を使って信じられないほどの小さな形状を印刷します。
インテル 4は、2022年後半に生産を開始し、クライアント向けのMeteor Lakeやデータセンター向けのGranite Rapidsなど、2023年に出荷される製品に向けて、ワットあたりの性能を約20%向上させ、面積も向上させる予定です。
インテル3プロセスノード(インテル4の最適化?)
インテルは、インテル4の次のステップとして、2023年後半に製造可能となるインテル3プロセスノードを発表する予定です。
インテルが発表した内容によると、インテル3はインテル4の世代的な最適化であり、1ワットあたりの性能を18%向上させ、HPライブラリの密度を高め、ドライバーの固有電流を増加させ、EUVの使用を増やし、ビア抵抗を減少させているようです。
Meteor Lake(Lunar Lake)やGranite Ridge(Diamond Rapids)以降の製品は、Intel 3のプロセスノードを利用することができそうですが、これは2024年、早くても2025年に発売される製品の話なので、まだまだ先の話になります。
インテル 3は、FinFETのさらなる最適化とEUVの強化により、インテル 4に比べてワット当たりの性能が約18%向上し、さらに面積も改善されています。インテル 3は、2023年後半に製品の製造を開始できる予定です。
インテル 20A プロセスノード&ビヨンド(真の次世代ノード)
インテルは、「インテル20A」という新製品で、ポストナノメートル時代の到来を宣言した。
インテル20Aは、10-¹⁰ mまたは1A=0.1nmに相当するアングストロング時代(アングストロングのA)の始まりです。
これは、2nmのクールな言い方ですが、ノードの微細化が進み、10年以内に小数点以下のスペースに向かうことを考えると、インテルは新しい測定単位が必要であると判断しました。
インテル20A(2nm)は、2024年上半期までに初期生産段階に入ることで、画期的なイノベーションを提供することになります。
20Aノードでは、既存のFinFETアーキテクチャに代わる全く新しいRibbonFETトランジスタが採用され、また、PowerViaと呼ばれる新しいインターコネクトのイノベーションが実現される予定です。
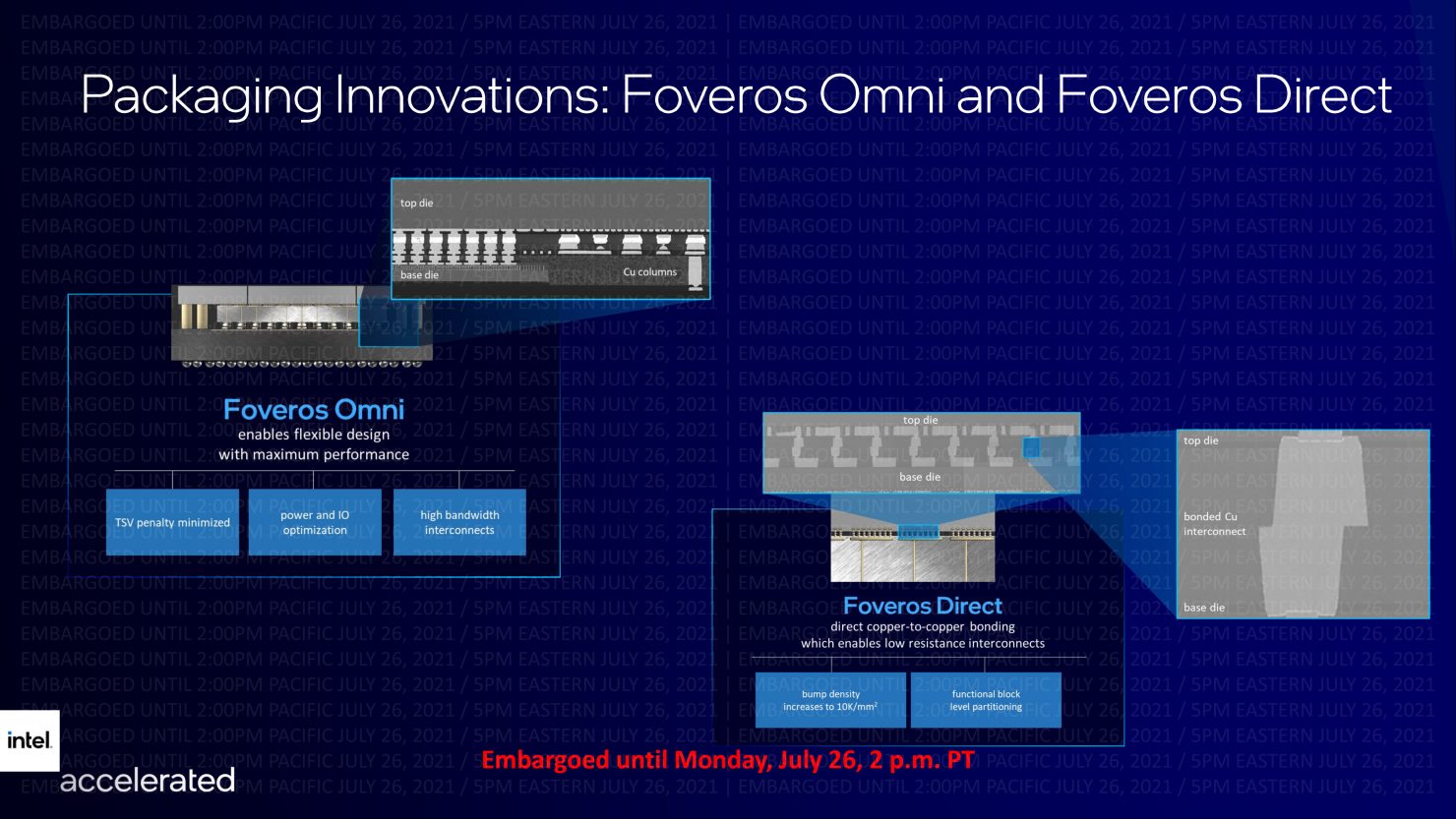
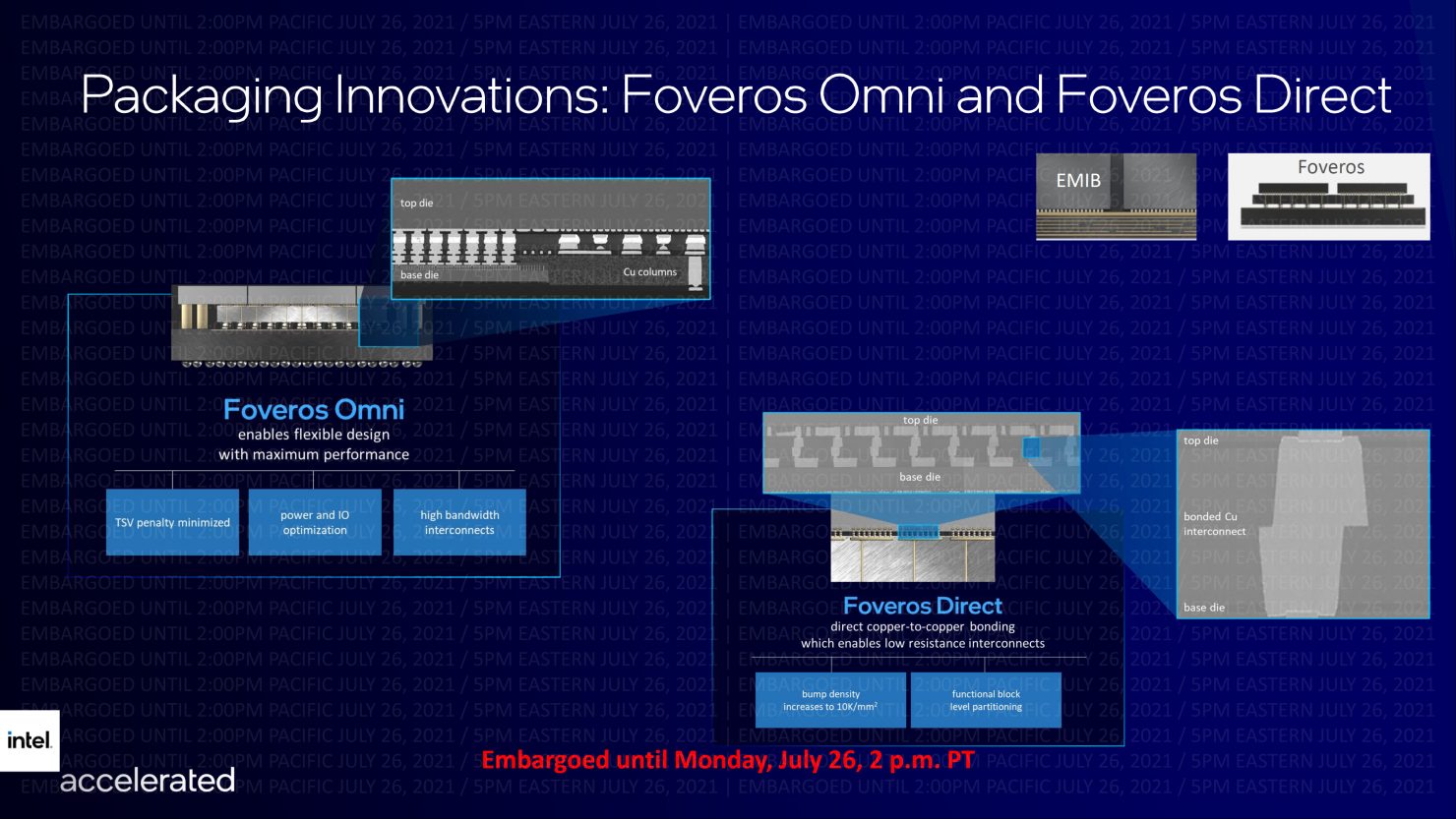
また、インテルは、OmniとDirectというForveros技術を拡張しています。
Forveors Omniは、高性能なコンピュートタイルをパッケージ化した製品に搭載され、Forveors Directは、銅と銅の接合による多階層のインターコネクト耐性を実現します。
Forveros全体としては、次世代の相互接続ソリューションにより、より高い帯域幅を提供するために更新されます。







※ 画像をクリックすると別Window・タブで拡大します。
インテル20Aは、RibbonFETとPowerViaという2つの画期的な技術でオングストローム時代の到来を告げるものです。
RibbonFETは、ゲート・オール・アラウンド型のトランジスタで、2011年にFinFETを開発して以来、初めての新しいトランジスタ・アーキテクチャとなります。
この技術は、より小さなフットプリントで複数のフィンと同じ駆動電流を実現しながら、トランジスタのスイッチング速度の高速化を実現します。
PowerViaは、業界初のバックサイド・パワーデリバリを実現するインテル独自の技術であり、ウェハの表側での電源配線を不要にすることで、信号伝送を最適化します。インテル 20Aは、2024年に立ち上がる予定です。
Foveros Omniは、次世代のFoverosテクノロジーの先駆けとなるもので、ダイ・トゥ・ダイの相互接続やモジュール設計のための3Dスタッキング技術により、限りない柔軟性を提供します。
Foveros Omniは、複数のトップ・ダイ・タイルと複数のベース・タイルを混合して、複数のファブ・ノードでダイを分解することができ、2023年には量産が可能になると予想されています。
Foveros Directは、銅と銅を直接接合することで低抵抗の配線を実現し、ウェハの終わりとパッケージの始まりの境界を曖昧にします。
Foveros Directは、10ミクロン以下のバンプピッチを可能にし、3D積層のための配線密度を桁違いに高め、これまで実現できなかった機能的なダイ・パーティショニングの新しいコンセプトをもたらします。
Foveros Directは、Foveros Omniを補完するもので、2023年の完成を目指しています。
インテル・プロセス・ロードマップ
| プロセス名 | Intel 10nm SuperFin | Intel 7 | Intel 4 | Intel 3 | Intel 20A | Intel 18A |
| 製造状況 | 大量生産中 | 量産中 | 2022後半 | 2023後半 | 2024後半 | 2025後半 |
| 性能/ワット (10nm SF比)* | N/A | 10-15% | 20% | 18% | >20%? | 未確認 |
| EUV | × | × | 〇 | 〇 | 〇 | High-NA EUV |
| トランジスタ 技術 | FinFET | 最適化済み FinFET | 最適化済み FinFET | 最適化済み FinFET | RibbonFET | 最適化済み RibbonFET |
| 製品 | Tiger Lake | Alder Lake Sapphire Rapids Xe-HPG? | Meteor Lake Granite Rapids Xe-HPC / Xe-HP? | Lunar Lake? Diamond Rapids? 未確認 | 未確認 未確認 未確認 | 未確認 未確認 未確認 |
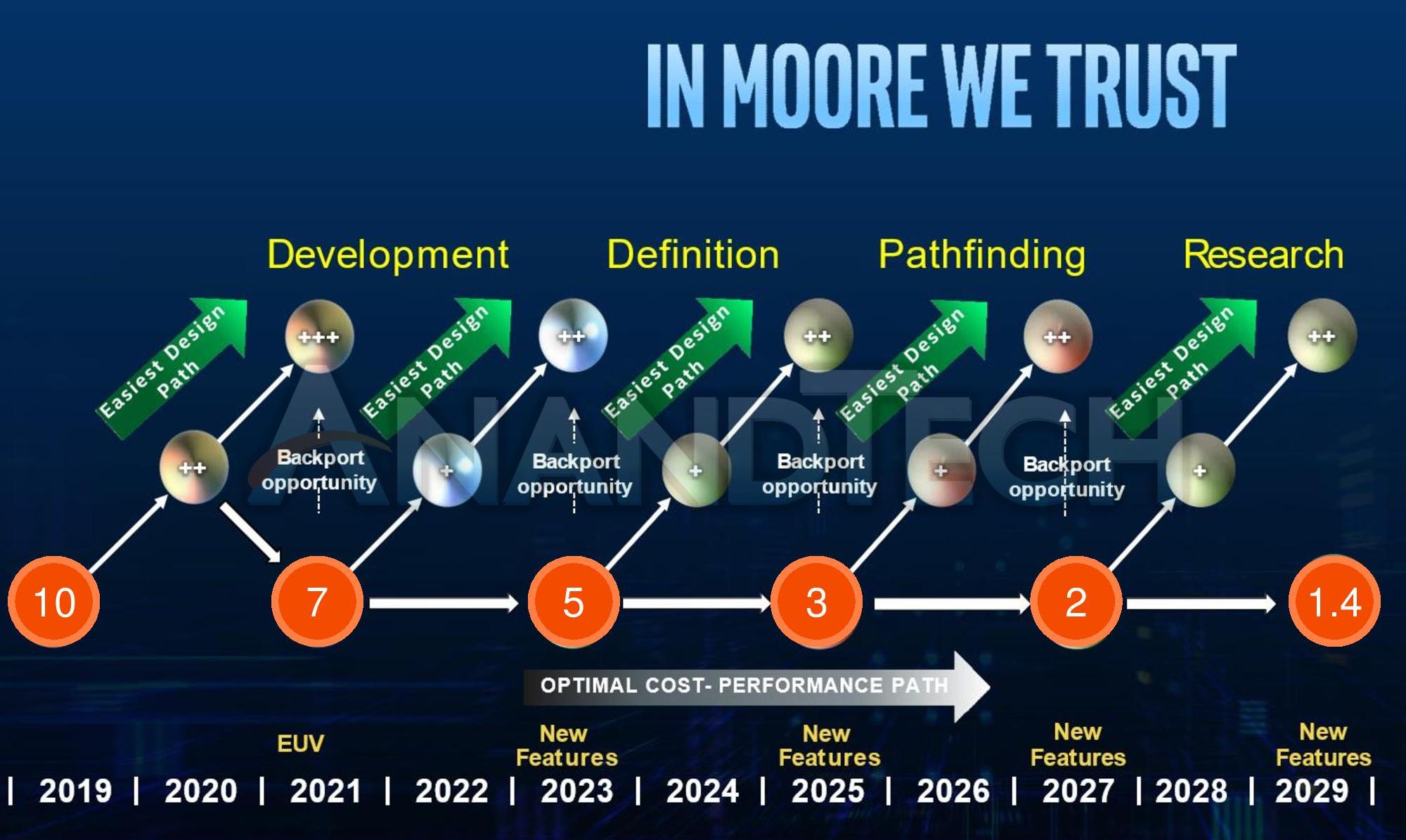
インテルの20Aプロセスノードをベースにした製品は、2025年より前には実現しないでしょう。
また、これまでのロードマップや20Aの位置づけを見ると、インテルの5nmまたは3nmプロセスノードの名称を変更したもののようだ。
しかし、インテルは20Aに留まらず、2025年以降の次世代ノードについても言及しており、その中には18Aも含まれています。
18Aノードは、2025年初頭に向けてすでに開発されており、RibbonFETアーキテクチャの改良により、トランジスタとチップの性能をさらに大きく向上させることになる。
※ 画像をクリックすると別windowタブで拡大します。
これらの新しい技術革新とネーミングスキームは、ほんの数年前にインテルが直面した混乱を避けるために素晴らしいものです。
プロセスノードのロードマップには、複数のノードとそれぞれのバックポートや最適化が並んでおり、実にわかりにくいものでした。
今、インテルはネーミングスキームを気にすることなく前進し、新しいネーミング基準で統一されたプロセスノードのラインナップを提供することができます。
解説:
Intelついに壊れる
今まで++とかSuperFinとか呼んでたけど、名前変えます。
ゲルシンガーさん 「10nmESFはintel7、7nmはIntel4、intel3にしまーす。これでオッケー」
いや、ダメだろ
私が思うところを書きます。
14nmは改良を続けてきましたが、結局TSMC7nmには敵いませんでした。
14nmで生産されたCoffeeLake以下の製品はAMD製品の後塵を拝することになりました。
その過去の実績を鑑みると、Intelがプロセスを改良したものはTSMCのプロセスが微細化したものに敵わないというのが私の判断です。
もちろん今後出てくるIntelの技術は新しいものですので14nmと同じになるとは限りません。
しかし、過去の技術から判断するとそうです。
名前を変えるのはマーケティング上の都合であるならば、同世代の製品は後塵を拝することになります。
そもそも、名前を変えるというのは同世代のTSMCの製品に敵わないため、Intelの製造プロセスはTSMCのプロセスと比較して、このくらいの性能はありますよ、と言う自己申告になります。
それの何がまずいのかと言えば、あくまでも「自己申告」であるということです。
そこに客観性はあるのでしょうか?かなり疑問です。
もう一つ付け加えるとすれば、「名前を変えても実態は変わらない」と言うことです。
Intel7nmを改良したIntel3がTSMC3nmに匹敵する性能があるのでしょうか?私にはそのようには到底思えないです。
典型的な大企業病のように見えるのですが、どうでしょうか?
*1ワット当たりの性能として比較が10nm ESFと原文にありましたが、恐らくは10nmSFの間違い(Intel7が10nmESFのため)で、10nmESF比となっていますが、恐らくは前世代比です。また、正直に言って、プロセスの改良なく前世代と比較して20%弱の改良が出来るものなのかどうか疑問です。