
NVIDIAは、そのGeForce RTX 30シリーズのグラフィックスカードとそれらが利用するAmpere GPUに関するより多くの情報を報道機関に提供しているようだ。
この情報は、今後数週間でゲーミング市場に登場するGA102とGA104ゲーミングAmpere GPUを詳しく見ていく、ディープダイブNDA'dセッションの一部です。
NVIDIA GeForce RTX 30シリーズグラフィックスカードのスペック、性能、GA102/GA104 GPUの詳細をディープダイブで紹介します。
ディープダイブセッションには、NVIDIA GeForce RTX 30シリーズに関する情報が含まれており、その中には9月1日の正式発表時にすでに見た情報もあれば、AmpereゲーミングGPUについてより詳細な情報を提供してくれる新しい情報もあります。
NVIDIAは、RedditのQ&Aセッションで、彼らがAmpere GPUの新しいSMデザインについて話している間に、少量の情報を詳述しています。
しかし、その前に、NVIDIAの新しいGeforce RTX 30シリーズのラインナップに搭載されているGPUを見てみましょう。以下の画像は、Hardwareeluxx.deからの提供です。
NVIDIA GA102 GPU - GeForce RTX 3090 及び RTX 3080 に搭載されるフラッグシップAmpereゲーミングGPU
NVIDIA GA102 GPUは、ダイサイズが628mm2で、合計280億個のトランジスタを搭載したフラッグシップゲーミングチップで、NVIDIAによると、6つのGPC(Graphics Processing Clusters)と6つのTPC(Texture Processing Clusters)で構成されている。
NVIDIAによると、GA102 GPUは6つのGPC(Graphics Processing Clusters)と6つのTPC(Texture Processing Clusters)で構成されています。
RTX 3090に搭載されているGA102 GPUは41個のTPC(82SM)を使用しており、GeForce RTX 3080は34個のTPC(68SM)を使用している。
Ampere GPU の各 SM は、128 個の CUDA コアと再設計された構造を特徴としています。
RTX 3090 の GA102 GPU は合計 10,496 コア、RTX 3080 の GA102 GPU は 8704 コアを搭載しています。
GPU密度の面では、GA102 GPUはTuring TU102 GPUの約2倍の密度を持っており、1平方ミリメートルあたり4,456万個のトランジスターがTuring GPUの2,467万個のトランジスターであるのに対し、Samsungの8nmプロセスノード上にあります。

各SMは4つのテンソルコアと1つのRTコアで構成されています。
GA102 GPUの特徴は、共有L2キャッシュ。GeForce RTX 3090では6MB、RTX 3080では5MBとなっている。
共有されている具体的なGPUブロック図は、320ビットバスを提供するGeForce RTX 3080用の合計10個の32ビットメモリコントローラを示している。
GeForce RTX 3090は、合計12個の32ビットメモリコントローラを搭載し、384ビットバスインターフェースを提供する。
NVIDIA GA104 GPU - GeForce RTX 3070のための効率性とゲーミングに最適化されたGPU
NVIDIA GeForce RTX 3070グラフィックスカードの心臓部には、GA104 GPUがあります。
GA104は、ゲーミングセグメントで手に入れようとしている数多くのAmpere GPUの1つだ。GA104 GPUは、スタックの中で2番目に高速なAmpereチップです。
このGPUは、Samsungの8nm(N8)プロセスノードをベースにしている。
GPUは395.2mm2と目されており、TU102 GPUに搭載されているトランジスターのほぼ93%である174億個のトランジスターを搭載しています。同時に、GA104 GPUはTU102 GPUのほぼ半分のサイズであり、これは非常識な密度である。
GeForce RTX 3070では、NVIDIAはそのフラッグシップで合計46個のSMユニットを有効にし、合計5888個のCUDAコアを実現しています。CUDAコアに加えて、NVIDIAのGeForce RTX 3070には、次世代RT(レイトレーシング)コア、Tensorコア、新しいSMまたはストリーミングマルチプロセッサユニットが搭載されています。
このGPUは、合計184個のTensorコアと46個のRTコアを搭載している。GA104 GPUは、将来のグラフィックカードのバリエーションで登場する可能性のある、フルファットな6144コア構成を搭載している可能性が高いです。
GA104 GPUは、4MBのL2共有キャッシュを備え、256ビット幅のバスインターフェース用に合計8つの32ビットメモリコントローラを備えている。
NVIDIA GeForce RTX 30シリーズ「Ampere」グラフィックスカード仕様:
| グラフィック カード名 | NVIDIA GeForce RTX 3070 | NVIDIA GeForce RTX 3080 | NVIDIA GeForce RTX 3090 |
| チップ型番 | Ampere GA104-300 | Ampere GA102-200 | Ampere GA102-300 |
| 製造プロセス | Samsung 8nm | Samsung 8nm | Samsung 8nm |
| ダイサイズ | 395.2mm2 | 628.4mm2 | 628.4mm2 |
| トランジスタ数 | 174億 | 280億 | 280億 |
| CUDAコア数 | 5888 | 8704 | 10496 |
| TMU数 / ROP数 | 未確認 | 未確認 | 未確認 |
| Tensor / RT Core数 | 184 / 46 | 272 / 68 | 328 / 82 |
| ベース クロック | 1500 MHz | 1440 MHz | 1400 MHz |
| ブースト クロック | 1730 MHz | 1710 MHz | 1700 MHz |
| FP32演算性能 | 20 TFLOPs | 30 TFLOPs | 36 TFLOPs |
| RT TFLOPs | 40 TFLOPs | 58 TFLOPs | 69 TFLOPs |
| Tensor-TOPs | 163 TOPs | 238 TOPs | 285 TOPs |
| メモリ容量 種類 | 8/16 GB GDDR6 | 10/20 GB GDDR6X | 24 GB GDDR6X |
| メモリバス幅 | 256-bit | 320-bit | 384-bit |
| メモリ速度 | 14 Gbps | 19 Gbps | 19.5 Gbps |
| メモリ帯域幅 | 448 Gbps | 760 Gbps | 936 Gbps |
| TDP | 220W | 320W | 350W |
| 価格(FE版 小売価格) | $499 US | $699 US | $1499 US |
| 発売日 | 2020/10 | 9月17日 | 9月24日 |
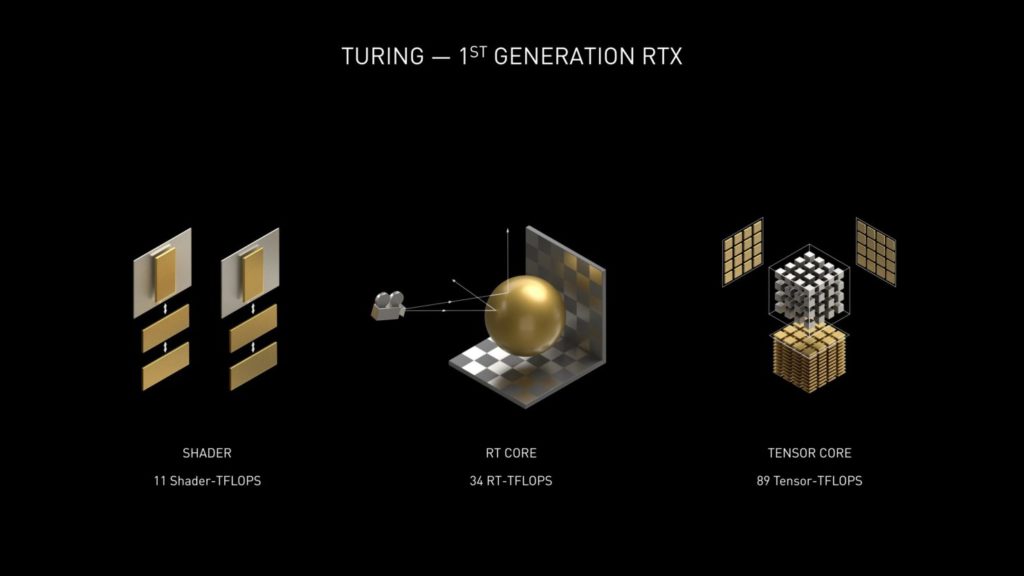
NVIDIA Ampere SM (Streaming Multiprocessor Design) - FP32の2倍のスループット
Ampere GPUを搭載したNVIDIA GeForce RTX 30シリーズのカードにも、先日Tony Tamasi氏が説明した真新しいSMデザインが搭載されています。以下は、SM Ampereアーキテクチャで何が新しくなったかの詳細だ。

Ampere 30シリーズSMの主な設計目標の1つは、FP32動作のスループットをTuring SMの2倍にすることでした。
この目標を達成するために、Ampere SMにはFP32とINT32オペレーションのための新しいデータパス設計が含まれています。
各パーティションの1つのデータパスは、1クロックあたり16個のFP32演算を実行できる16個のFP32 CUDAコアで構成されています。
もう1つのデータパスは、16個のFP32 CUDAコアと16個のINT32コアの両方で構成されています。
この新しいデザインの結果、各Ampere SMパーティションは、1クロックあたり32個のFP32演算、または1クロックあたり16個のFP32と16個のINT32演算のいずれかを実行することができます。
4つのSMパーティションを組み合わせた場合、1クロックあたり128個のFP32演算を実行することができ、これはTuring SMの2倍のFP32レート、または1クロックあたり64個のFP32と64個のINT32演算を実行することができます。
FP32の処理速度が2倍になることで、多くの一般的なグラフィックスや計算操作、アルゴリズムのパフォーマンスが向上します。
最近のシェーダのワークロードは通常、FFMA、浮動小数点加算(FADD)、浮動小数点乗算(FMUL)などの FP32 算術命令と、アドレス指定やデータ取得のための整数加算、浮動小数点比較、処理結果の min/max などのより単純な命令を組み合わせたものが混在しています。
性能向上は、命令の組み合わせによって、シェーダとアプリケーションレベルで異なります。レイトレーシングデノイジングシェーダは、FP32のスループットを2倍にすることで大きな利益を得ることができる良い例です。
数学のスループットを2倍にするには、それをサポートするデータパスを2倍にする必要があったため、Ampere SMはSMの共有メモリとL1キャッシュの性能も2倍にしました。(Turingでは64バイト/クロックに対してAmpere SMでは128バイト/クロック)。
GeForce RTX 3080 の総 L1 帯域幅は 219 GB/秒であるのに対し、GeForce RTX 2080 Super は 116 GB/秒である。
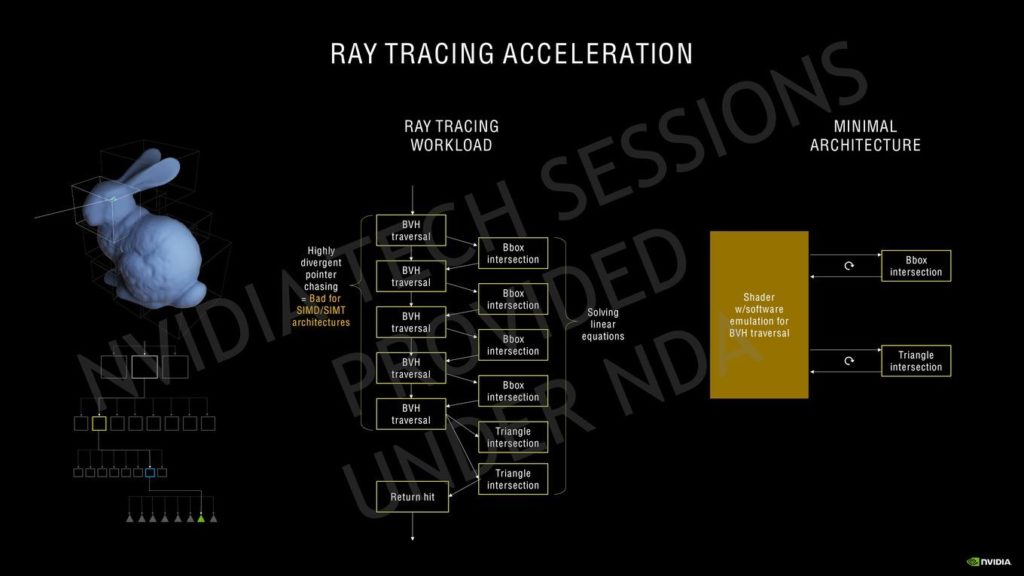
先行のNVIDIA GPUと同様に、Ampereは、グラフィックス処理クラスタ(GPC)、テクスチャ処理クラスタ(TPC)、ストリーミングマルチプロセッサ(SM)、ラスター演算子(ROPS)、およびメモリコントローラで構成されています。
GPC は、主要なグラフィックス処理ユニットのすべてが GPC 内に配置されている主要な高レベルハードウェアブロックです。
各GPCには専用のラスターエンジンが含まれており、現在では、NVIDIA Ampere Architecture GA10x GPUの新機能である2つのROPパーティション(各パーティションには8つのROPユニットが含まれています)も含まれています。
NVIDIA Ampereアーキテクチャの詳細については、近日中に発表されるNVIDIAのAmpereアーキテクチャホワイトペーパーを参照してください。
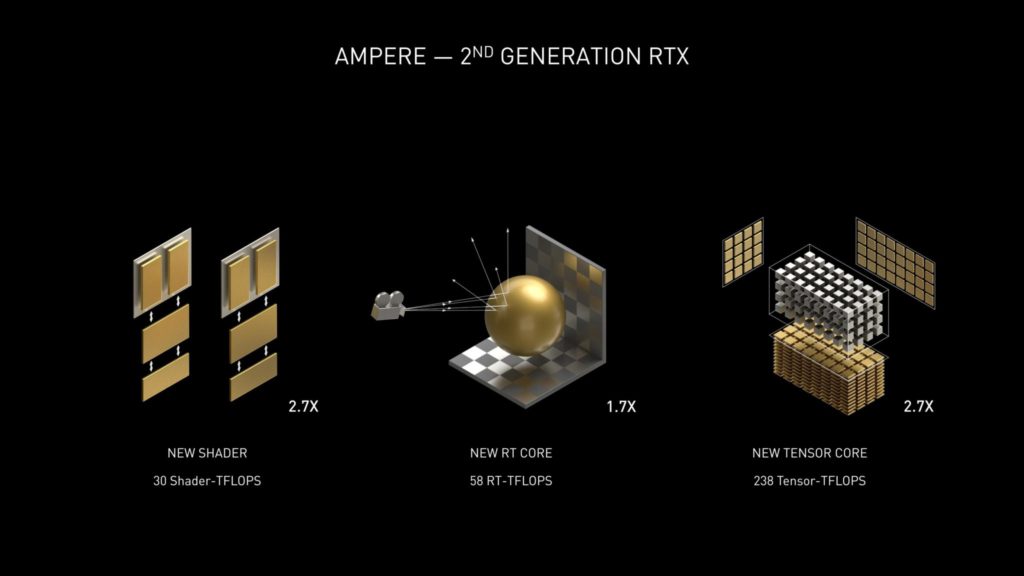
Ampere SMユニットをよく見ると、各ブロックは128個のFP32ユニットで構成されています。
しかし、2つのFP32データパスのうちの1つは、INT32演算を同時に実行することもできます。
Tensorコアは4つのユニットで構成されており、SMあたり4つのテクスチャユニットと1つのRTコアがあります。
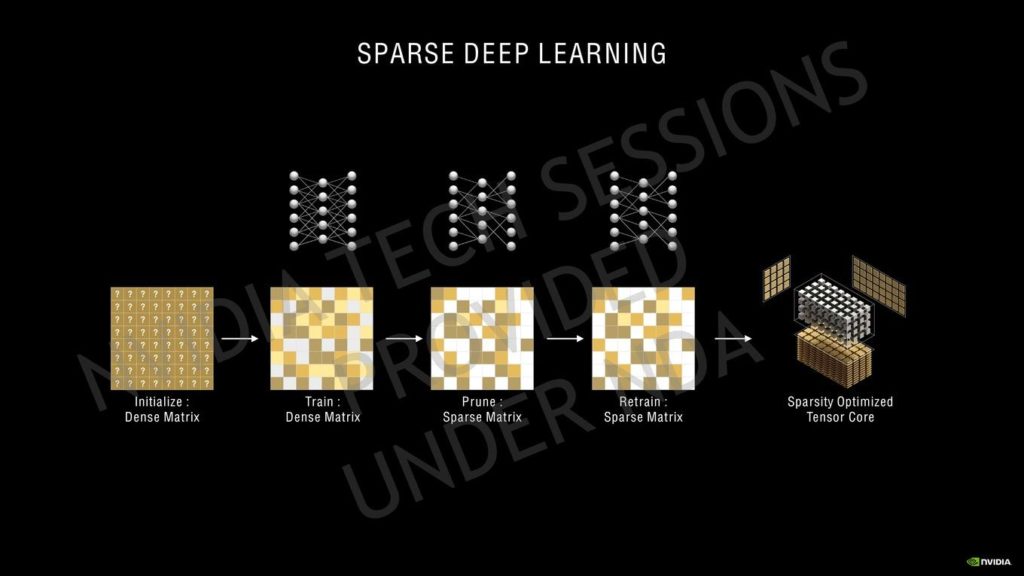
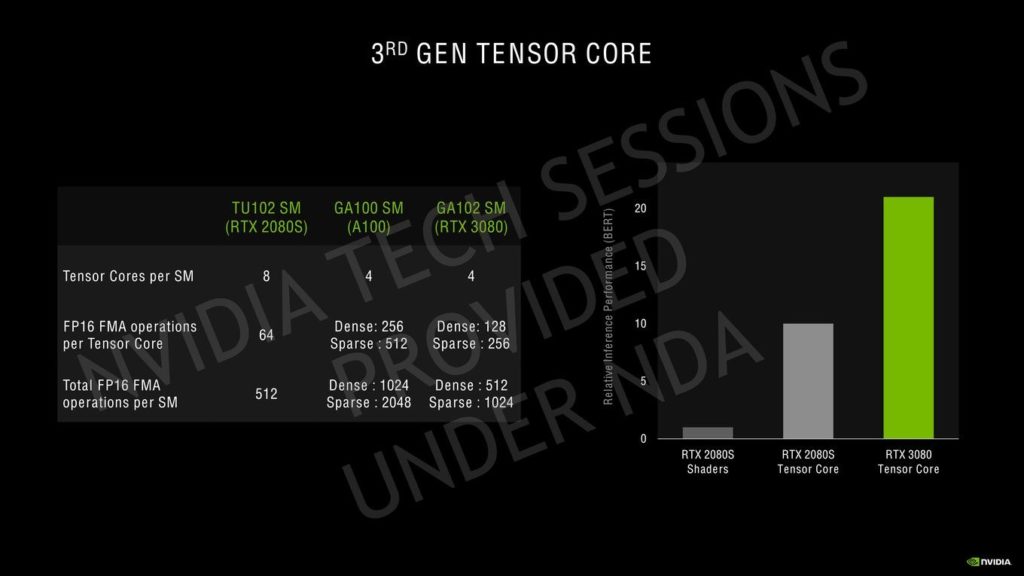







第3世代のTensorコアには、NVIDIAはAmpereのHPC GPUラインで使用したのと同じスパリティアーキテクチャを使用しています。
Ampereは、Turingの8個のTensorコア/SMに対し、4個のTensorコア/SMを特徴としていますが、これらは新しい第3世代設計に基づいているだけでなく、より大きなSMアレイでカウントが増加しています。
Ampere GPUは、INT16コア全体を利用してテンソルコアあたり128個のFP16 FMA演算を実行することができ、スパーシティを使用すると256個まで実行することができます。
SMあたりのFP16 FMA演算の合計は512と1024に増加します。これは、更新されたTensor設計による推論性能という点では、Turing GPUの2倍になる。
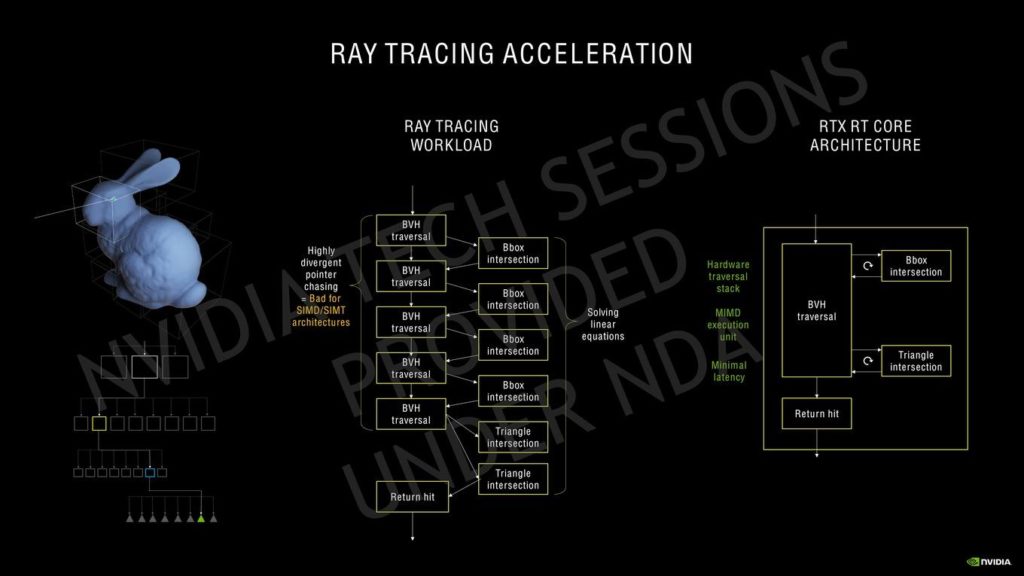
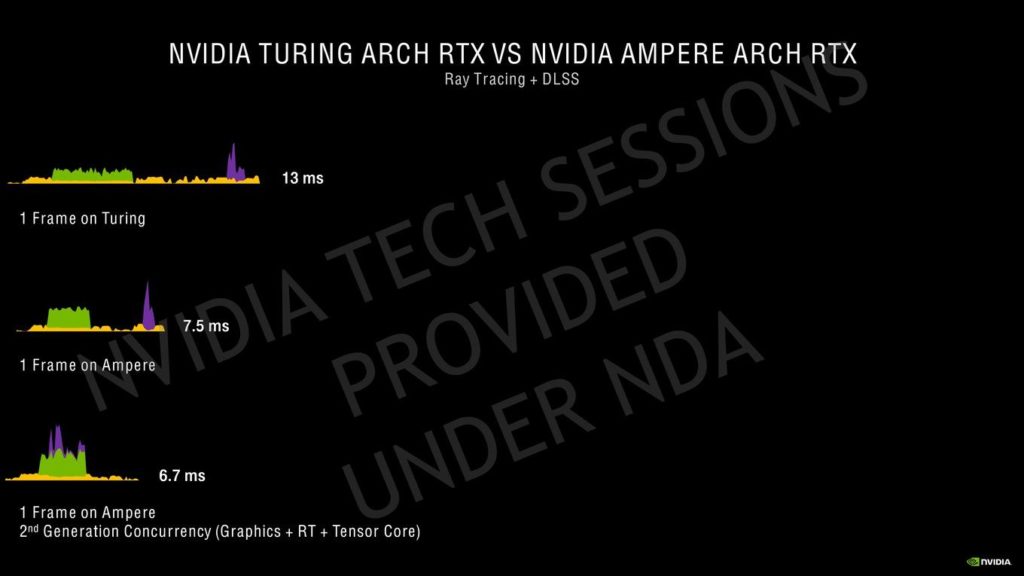
同じことがレイトレーシングコアにも当てはまり、2回目のイテレーションではTuringアーキテクチャと比較してレイの交差の数が2倍になりました。
SMの数が多いほどRTコアの数も多くなり、Ampereでのレイトレーシングアクセラレーションの全体的な性能に影響を与えます。
GDDR6X - NVIDIAのGeForce RTX 30シリーズグラフィックスカード専用に設計されたグラフィックスメモリの次の進化形
Micron GDDR6Xメモリは、多くの新機能を搭載しています。
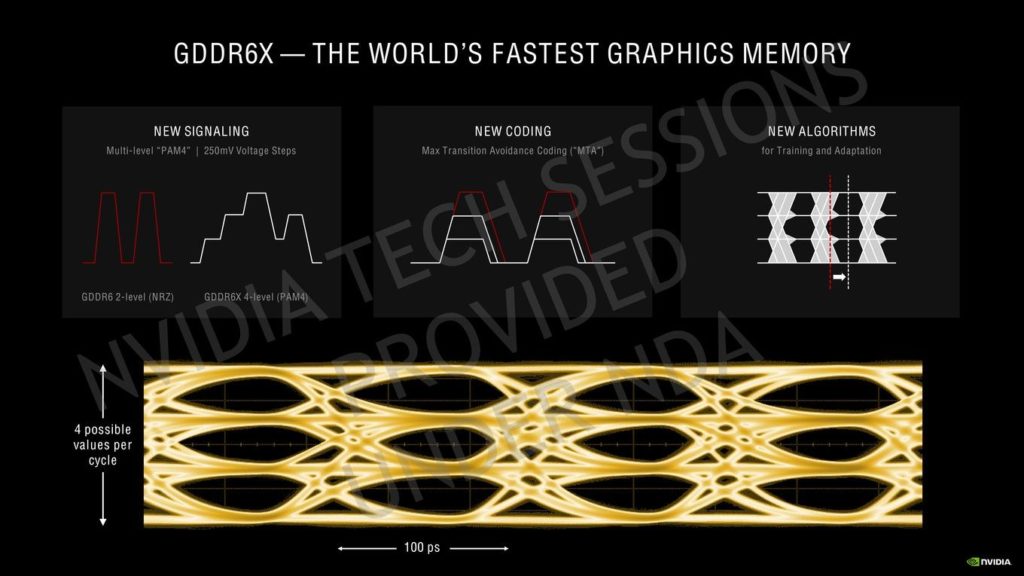
より高速で、I/Oデータレートが2倍になり、メモリダイにPAM4マルチレベルシグナリングを初めて実装しました。
Geforce RTX 3090クラスの製品では、MicronのGDDR6Xメモリは最大1TB/sの帯域幅を実現し、8Kなどの高忠実度解像度での次世代ゲーム体験に電力を供給するために使用されています。
新しいGDDR6X SGRAM
SGRAMのデータレートを2倍にし、1トランザクションあたりの消費電力を抑えながら、グラフィックスカード・アプリケーションのための1テラバイト/秒(TB/秒)のシステム・メモリ帯域幅の境界を打ち破ることを可能にします。
プロセッサと DRAM の間で、4 つの電圧レベルを使用して 1 インターフェースクロックあたり 2 ビットのデータをエンコードして転送する PAM4 エンコード信号を採用した初のディスクリート・グラフィックス・メモリ・デバイスです。
高速で安定した設計・動作が可能で、量産品を内蔵している。
前述の通り、GDDR6Xは新しいPAM4マルチレベルシグナリング技術を採用しており、データ転送速度を大幅に向上させ、I/Oレートを倍増させ、各メモリダイの能力を64GB/sから84GB/sに押し上げている。
また、MicronのGDDR6Xメモリダイは、PAM4シグナリングを搭載しながら量産可能な唯一のグラフィックスDRAMです。

興味深いのは、MicronのGDDR6Xメモリが最大21Gbpsの速度を叩き出せるのに対し、GeForce RTX 3090では19.5Gbpsの動作を見ることができたということだ。
AIBが利用できるようになれば、より高いビンディングダイを利用できる可能性がある。
Micronは、2021年には21GB/s以上の高速化を計画していることも確認しているが、それを利用するカードがあるかどうかは見守る必要があるだろう。
それは単に高速化された速度ではなく、MicronのGDDR6Xは、前世代のGDDR6メモリと比較して転送されたビットあたりの電力を15%低く抑えながら、より高い帯域幅を提供しています。
Micron GDDR6Xメモリ
| 特徴 | GDDR5 | GDDR5X | GDDR6 | GDDR6X |
| 集積度 | 512Mb から 8Gb | 8Gb | 8Gb, 16Gb | 8Gb, 16Gb |
| VDD 及び VDDQ | 1.5V及び 1.35V | 1.35V | 1.35V及び 1.25V | 1.35V及び 1.25V |
| VPP | N/A | 1.8V | 1.8V | 1.8V |
| データ レート | 8 Gb/s迄 | 12Gb/s迄 | 16 Gb/s迄 | 19 Gb/s, 21 Gb/s, >21 Gb/s |
| チャンネル数 | 1 | 1 | 2 | 2 |
| アクセス粒度 | 32 bytes | 64 bytes 2x 32 bytes in pseudo 32B mode | 2 ch x 32 bytes | 2 ch x 32 bytes |
| バースト長 | 8 | 16 / 8 | 16 | 8 in PAM4 mode 16 in RDQS mode |
| シグナリング | POD15/POD135 | POD135 | POD135 /POD125 | PAM4 POD135 /POD125 |
| パッケージ | BGA-170 14mm x 12mm 0.8mm ball pitch | BGA-190 14mm x 12mm 0.65mm ball pitch | BGA-180 14mm x 12mm 0.75mm ball pitch | BGA-180 14mm x 12mm 0.75mm ball pitch |
| I/O幅 | x32/x16 | x32/x16 | 2 ch x16/x8 | 2 ch x16/x8 |
| シグナル数 | 61 - 40 DQ, DBI, EDC - 15 CA - 6 CK, WCK | 61 - 40 DQ, DBI, EDC - 15 CA - 6 CK, WCK | 70 or 74 - 40 DQ, DBI, EDC - 24 CA - 6 or 10 CK, WCK | 70 or 74 - 40 DQ, DBI, EDC - 24 CA - 6 or 10 CK, WCK |
| PLL, DCC | PLL | PLL | PLL, DCC | DCC |
| CRC | CRC-8 | CRC-8 | 2x CRC-8 | 2x CRC-8 |
| VREFD | 外付、若しくは 2バイトごと内蔵 | 外付、若しくは 1バイトごと内蔵 | ピンごとに内蔵 | ピンごとに内蔵 ピンごとに 3サブレシーバー |
| Equalization | N/A | RX/TX | RX/TX | RX/TX |
| VREFC | 外付 | 外付、内臓 | 外付、内臓 | 外付、内臓 |
| セルフ リフレッシュ (SRF) | Yes Temp. Controlled SRF | Yes Temp. Controlled SRF Hibernate SRF | Yes Temp. Controlled SRF Hibernate SRF VDDQ-off | Yes Temp. Controlled SRF Hibernate SRF VDDQ-off |
| Scan | SEN | IEEE 1149.1 (JTAG) | IEEE 1149.1 (JTAG) | IEEE 1149.1 (JTAG) |
NVIDIA GeForce RTX 30シリーズ 冷却設計&サーマル
NVIDIAは、GeForce RTX 30シリーズグラフィックスカードのために、これまでで最高で最も強力なFounders Editionの冷却デザインを開発しました。
NVIDIAは、より高いパフォーマンスを実現するためには、新しい形の冷却ソリューションが必要であると説明しており、いくつかの新しい技術と既存の技術を利用することで、GPUを冷やしながら静かに動作させることができる次世代カード用のユニークな冷却ソリューションを用意しました。
Founders Editionの冷却は、フルアルミ合金製のヒートシンクを使用しており、ハイブリッドベーパーチャンバーと両面アキシャルテックファンを使用しています。
このヒートシンクにはナノカーボンコーティングが施されており、温度をコントロールしながら良い仕事をしてくれるはずです。

フィンやヒートパイプのデザインを全面に出しているだけではないところが面白い。
これは、オリジナルのFounders EditionのGeForce GTX 780以来、より大きなヒートシンク面積を利用した初めてのデザインです。
また、前面と底面に1つずつ配置されたユニークなファンも搭載されています。
このプッシュ&プルファン構成は、それが呼ばれているように、排気口の熱をはるかに効果的にプッシュすると言われています。
カード自体の背面からケース内に吹き出す空気がありますが、最新のCPUエアやリキッドクーラーはケース内から空気を排出するのに非常に良い仕事をしているので、それは心配の大きな原因になるべきではありません。
音響的には、新しいFounders Editionのデザインは、従来のデュアルアキシャルクーラーよりも静かでありながら、前世代のソリューションの約2倍の冷却性能を実現しています。
前述のNVLinkと電源設計の変更は、これまでで最大のフィンスタックを介してエアフローのためのより大きなスペースを作り出し、より大きなブラケット通気口は、個々の形状のシュラウドフィンと連動してエアフローを改善します。
実際、Founders Editionカードは、どこを見ても、エアフローを最大化し、温度を最小化し、可能な限りノイズを抑えながら最高レベルのパフォーマンスを可能にするように設計されています。
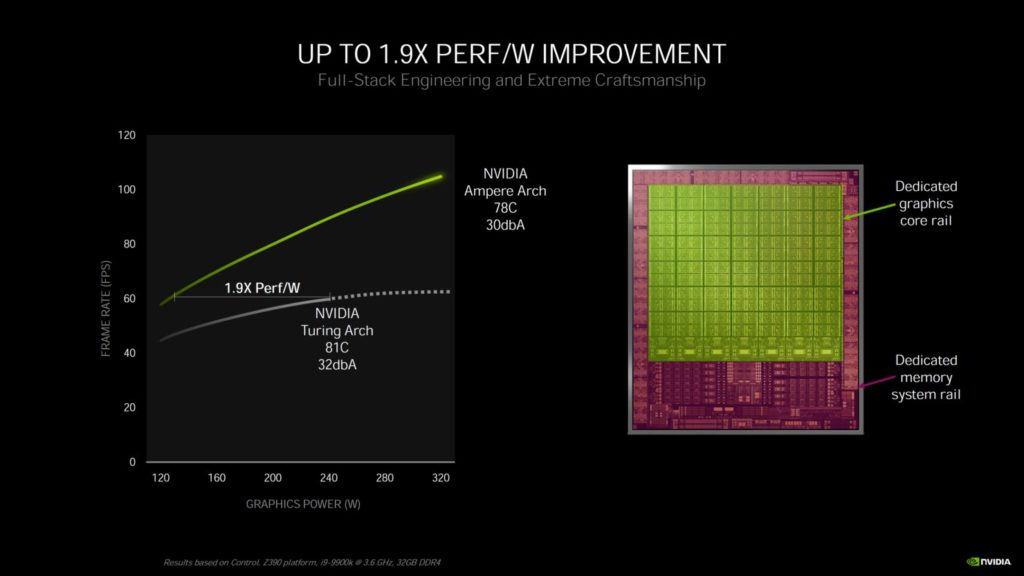
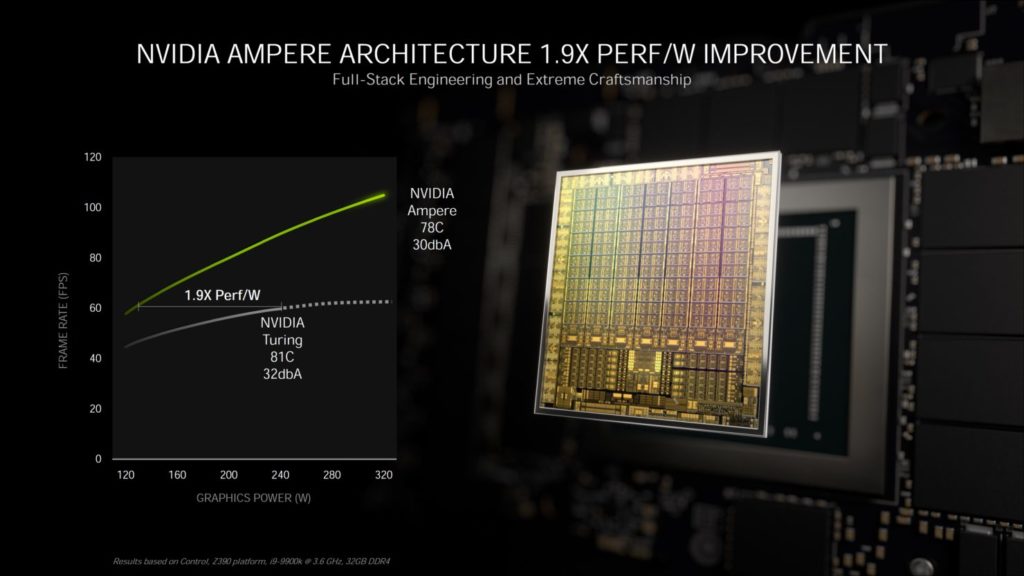
クーラーのノイズと性能の面では、GeForce RTX 3080は、ピーク時のTBPが320Wのときのピーク温度が78℃で動作し、ノイズ出力はわずか30dBAです。比較のために、Turing Founders Edition クーラーは、240W (RTX 2080 SUPER) の TBP を達成したときのピーク温度は 81℃で、ノイズ出力は 32dBA です。NVIDIA自身のテストでは、GeForce RTX 3080は、GPUの消費電力が310Wで、ピーク温度が76℃で、1920MHz付近で平均していることを明らかにしています。
これは、RTX 3080がTuring genの前身の60 FPSに対して、より涼しく静かでありながら100 FPS以上を提供できることから、NVIDIAがその1.9倍の効率性の数字を得ているところでもあります。
NVIDIA GeForce RTX 3090、RTX 3080、RTX 3070 ファウンダーズエディションギャラリー








NVIDIA GeForce RTX 3090 & RTX 3080 グラフィックカード PCB & 電源 - オーバークロックするように設計されています!
Founders EditionのGeForce RTX 3090グラフィックスカードの最大の変更点の一つは、PCB設計です。
GeForce RTX 3090 & GeForce RTX 3080は、我々が以前に消費者空間で見てきたものとは異なり、ユニークでコンパクトなPCBパッケージが付属しています。
しかし、コンパクトであるということは、カードがパンチを持っていないということではありません。NVIDIAが設計したこれらのコンパクトなPCBには、かなりの馬力があります。

PCBには20以上のパワーチョークが搭載されており、フラッグシップのRTX 20シリーズカードよりもプレミアムなデザインとなっています。
メモリが2つのフェーズから電力を受け取る間、GPUは18のフェーズから電力を供給されます。
NVIDIAは、このPCBを、ほとんどのユーザーがさらに高速なパフォーマンスを得るために活用することができる前例のないGPUオーバークロックのヘッドルームを持つオーバークロックの驚異として売り出しています。
しかし、先に指摘したように、Founders EditionのPCBはリファレンスデザインではなく、標準的な長方形のPCBが付属しています。ウォーターブロックメーカーもこれを確認しており、我々はここで報告した。

さらに、GeForce RTX 30 シリーズ Founders Edition カードには、12 ピン Micro-Fit 3.0 電源コネクタが搭載されます。
これらのコネクタは、カードが2x8ピンから1x12ピンのコネクタを同梱して出荷されるため、電源のアップグレードを必要としないので、互換性の問題なく最新のグラフィックスカードを動作させることができます。
PCB上の12ピンコネクタの配置にも注目してください。垂直に配置されており、PCBのデザインから判断すると、NVIDIAが標準的なデュアル8ピンデザインではなく、シングル12ピンプラグに移行した理由がわかります。
PCB上には何かをするためのスペースが限られているため、より小さくてコンパクトな電源入力が必要だったのです。
NVIDIA GeForce RTX 30シリーズの性能・発売・価格
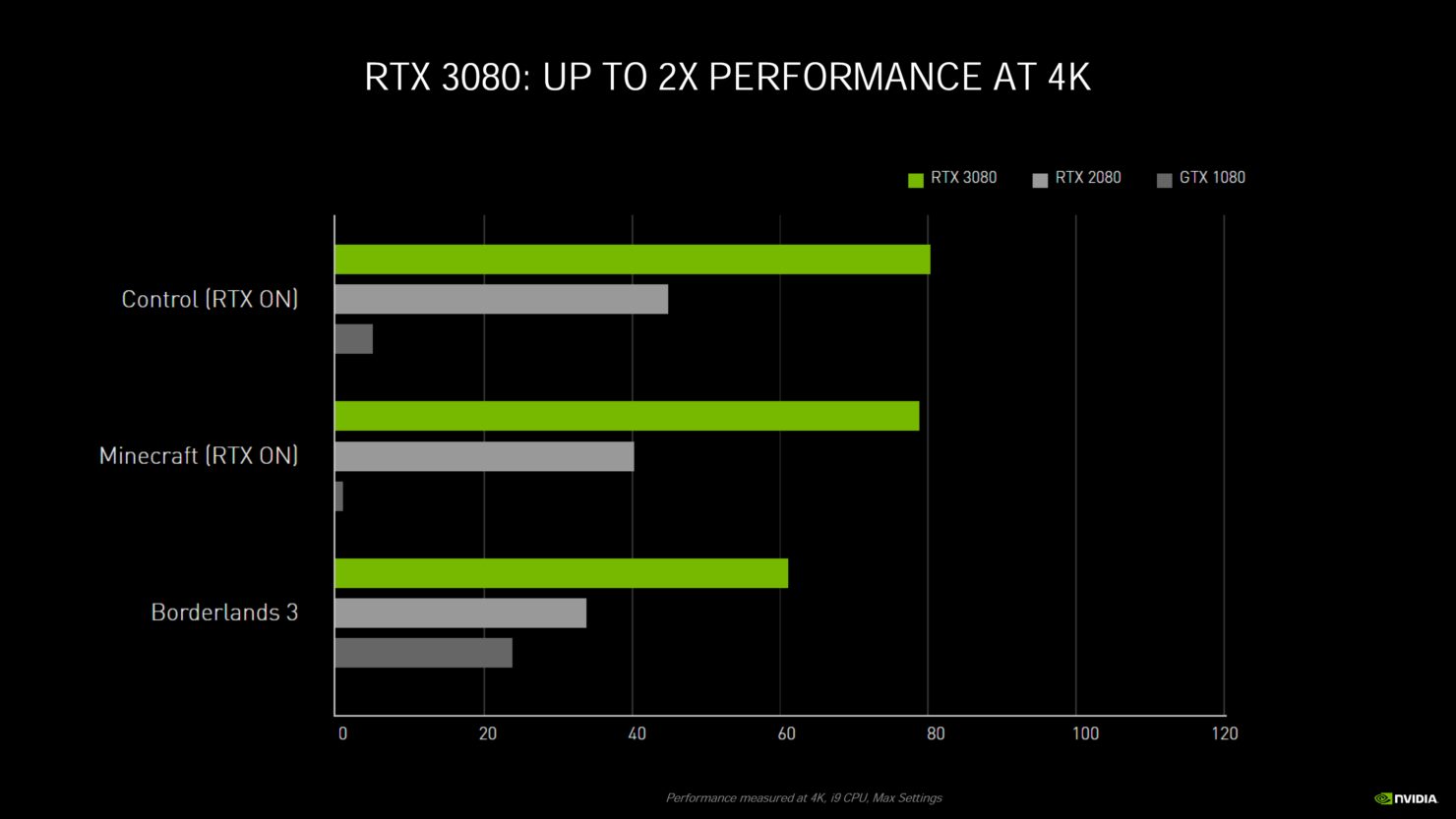
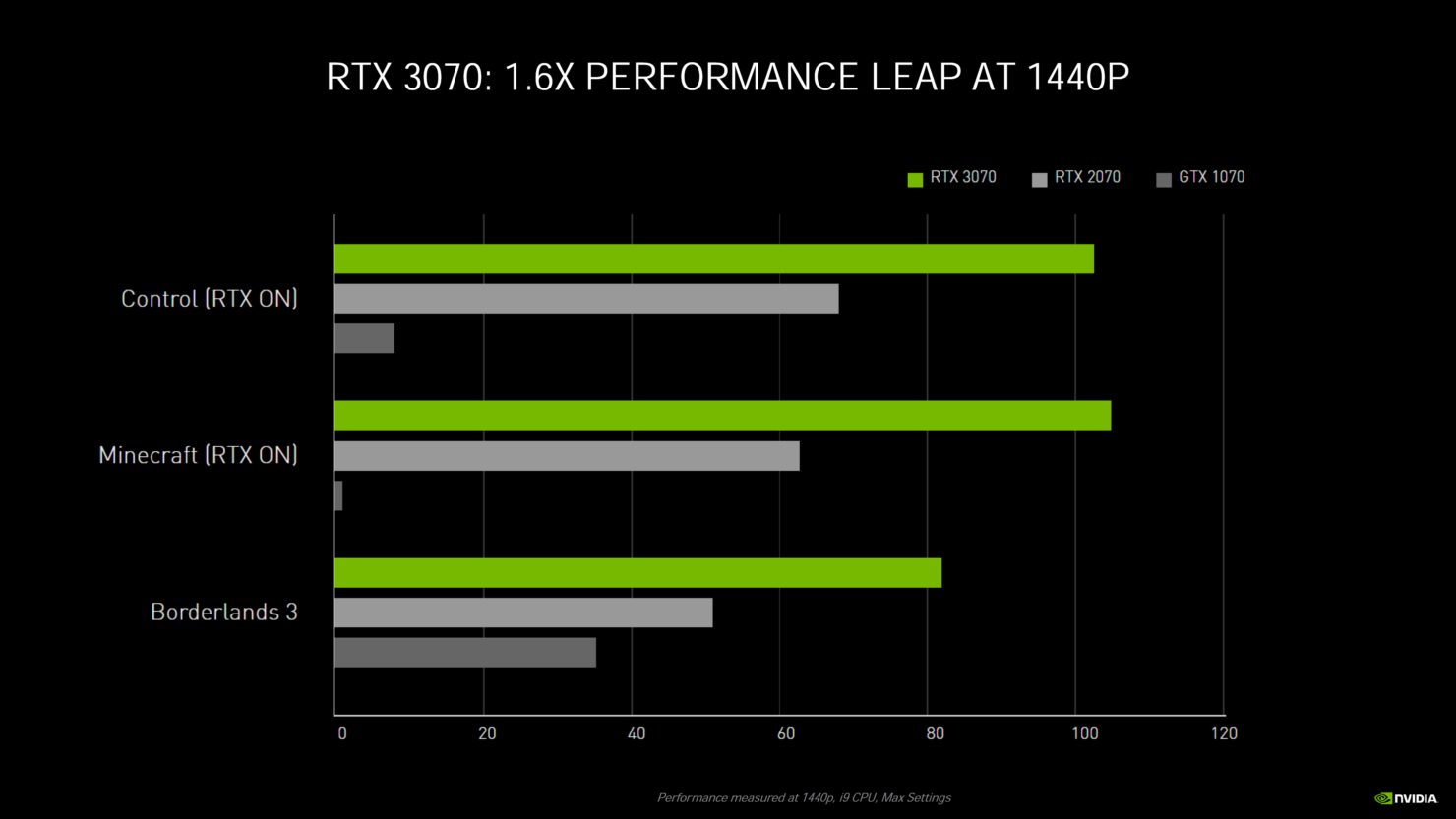
また、NVIDIAは、GeForce RTX 3090、GeForce RTX 3080、GeForce RTX 3070グラフィックスカードの追加のパフォーマンス番号を共有しています。
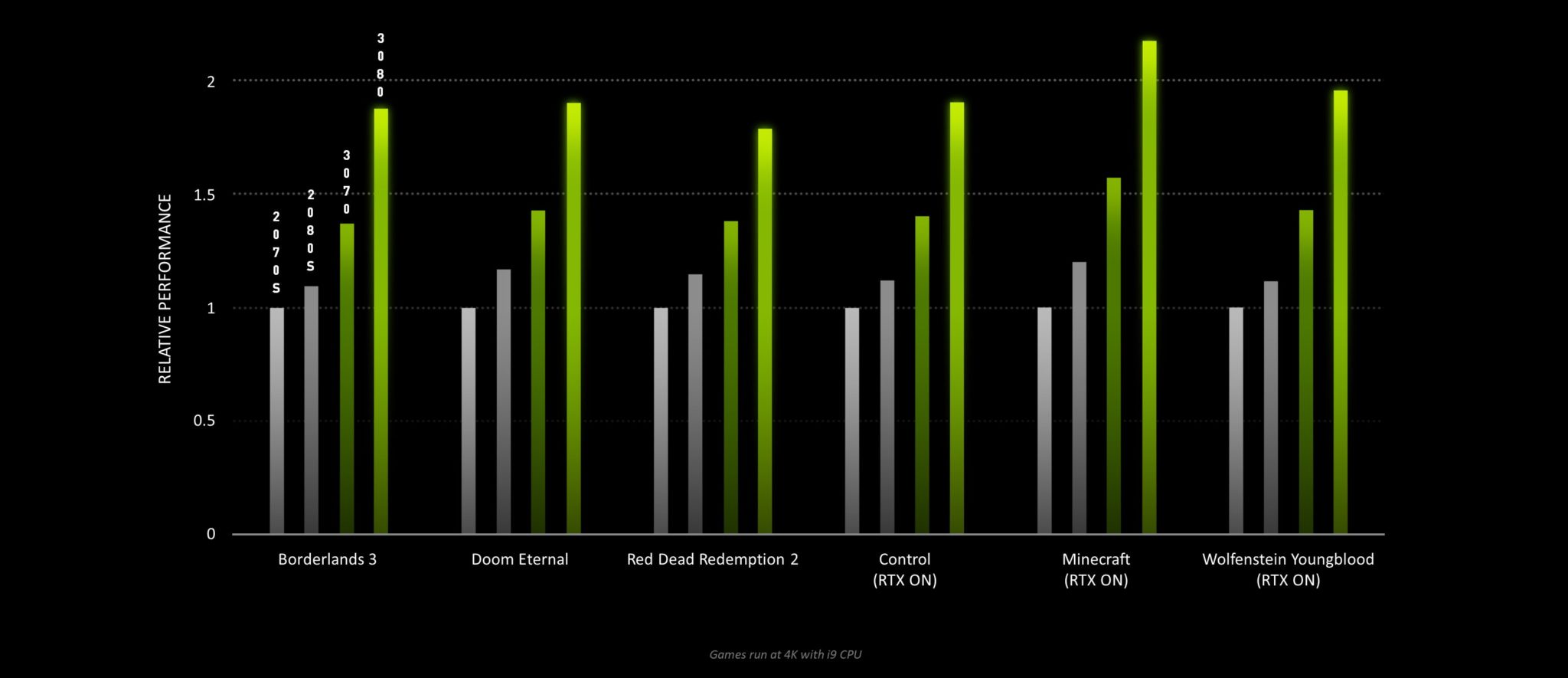
※ クリックすると別Window・タブで拡大します
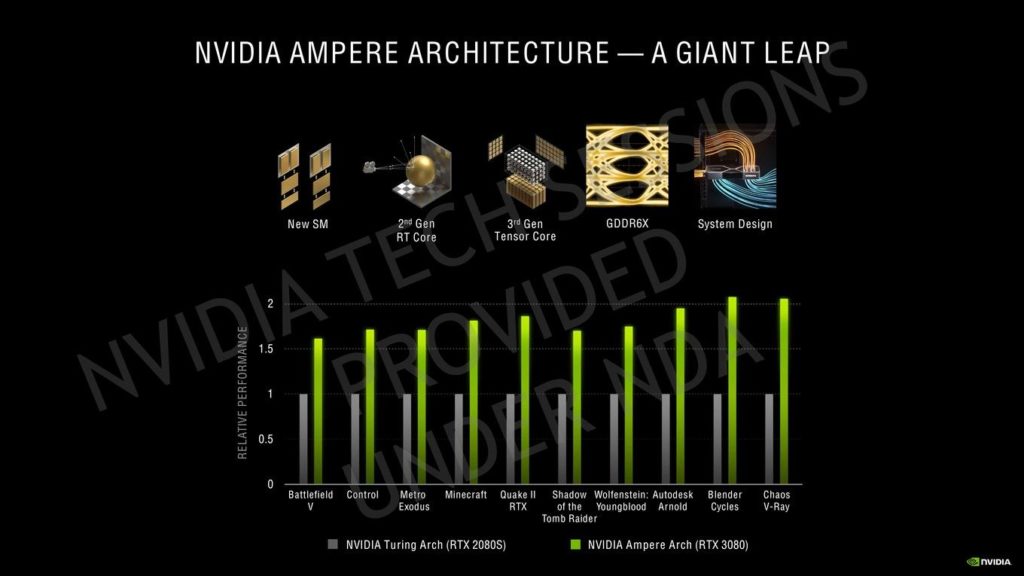
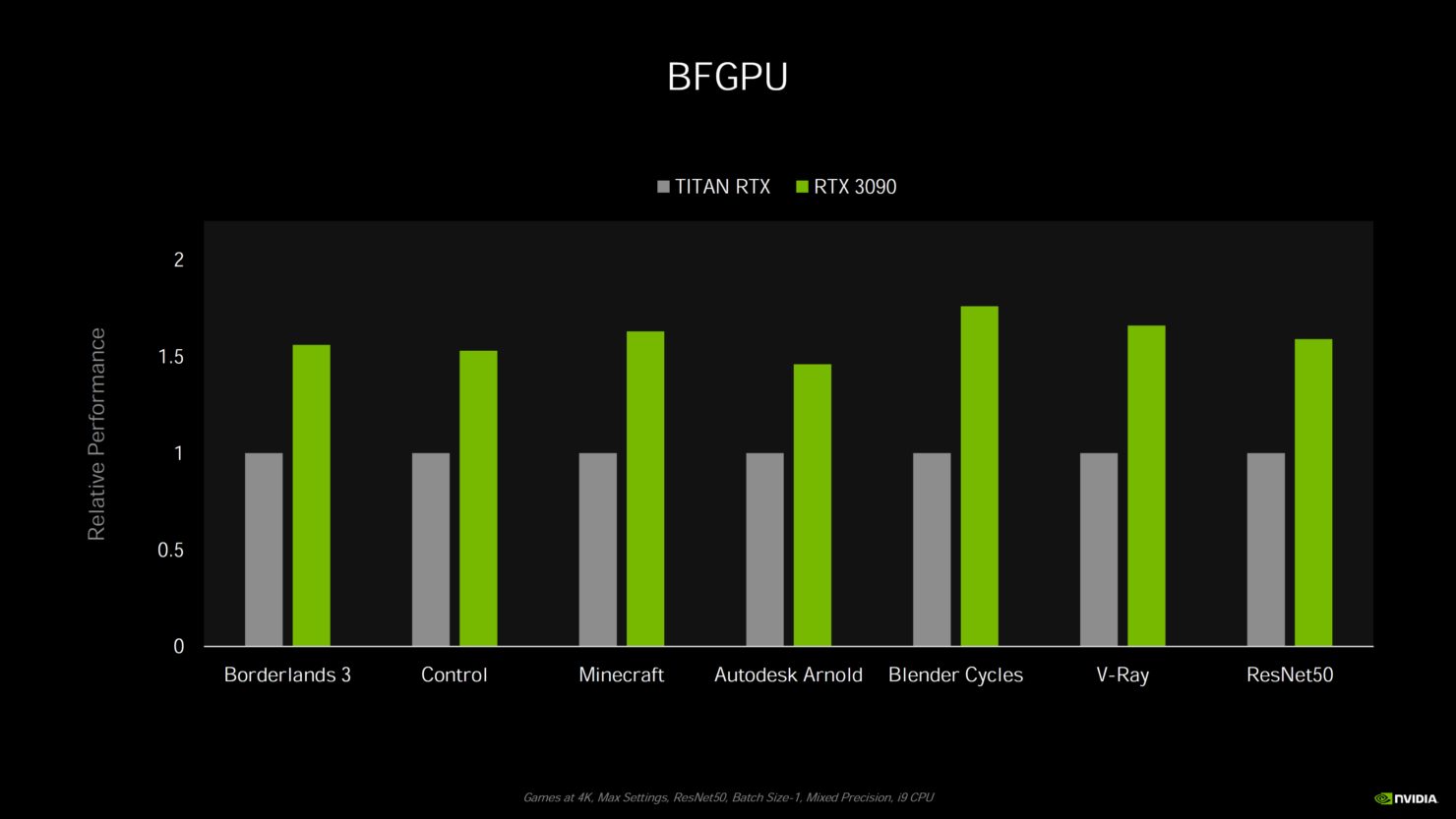
今NVIDIAが共有しているパフォーマンスの数字はありませんが、展示されているものから見ると、GeForce RTX 3070はRTX 2080 Tiよりも速く、RTX 3080はRTX 2080 Tiよりも少し先を行っており、RTX 3090はフルラインアップのスタックとしては非常に印象的なRTX 2080 Tiよりも50%ほど速くなっています。
他のニュースでは、NVIDIAはすでに「Doom Eternal」でRTX 3080の新しいパフォーマンスデモを披露しており、GeForce RTX 2080 Tiを絶対的に破壊しています。













発売日と価格については、NVIDIAは9月17日にGeForce RTX 3080を最初に発売し、続いて9月24日にGeForce RTX 3090、そして最後に10月にGeForce RTX 3070を発売すると発表している。
グラフィックカードの小売価格は1499ドル(RTX 3090)、699ドル(RT 3080)、499ドル(RTX 3070)。カスタムモデルは参考価格に固執するが、よりプレミアムなモデルはより高い価格が特徴となる。
解説:
DLSSで未来へ加速するGeforce
さて、すでに皆さんご存じの通り、Ampereが発表されました。
その性能は想像を絶するもので、トランジスタ当たりの性能の伸びが半端ないです。
どのくらいすさまじいかと言えば、RTX3070の場合、RTX2080Tiの93%のトランジスタ数でFP32演算性能で約1.45倍、ただし、ゲーム性能だとほぼ同等となっています。
CUDAコア数で比較するとRTX3070が5888CUDAコアに対してRTX2080Tiが4352CUDAコアですので、1コア当たりのトラジスタ数はかなり減少している計算になります。
にも拘わらず、演算性能がアップしているのはトランジスタ数が増えたことによって機能を細分化し、それによって何らかのブレークスルーが起きたと考えてよいでしょう。
「製造プロセスのハンデを設計でひっくり返す」、言葉にするのは簡単ですが、あのIntelですらも成しえなかったことをあっさりとやってのけるnVidiaは凄いの一言で、今回のAmpereの想像を絶する性能はもはや絶句レベルです。
※ ただし、Big Naviはまだ出ていませんので、確定ではありません。AMDの公称どおり、Navi10に対してワットパフォーマンスが+50%になり5120SPだとして、300W迄使うとしたら、39TLOPSになりますが・・・まさかなと思います。
計算式 9.75TFLOPS(Navi10)*1.5(W/Perf.)*2(SP数)*1.33333(TGP容量分)=38.99999TFLOPS
Geforceキラーとして、Big Naviや新たなる挑戦者としてIntelの単体GPU Xeが登場予定でしたが、このすさまじい性能を見ると、恐らく敵わないでしょう。
RTXやその他の技術も素晴らしいと思いますが、Geforceの性能を加速しているのはDLSSだと思います
RTX2080Tiは公称性能値13.8TFLOPSですが、RTXやDLSS込みで換算すると44TFLOPS相当になるといわれています。
RTX3090/3080もRTXやDLSS込みで性能を換算すると恐らく、実性能の3-7倍程度に跳ね上がると思います。
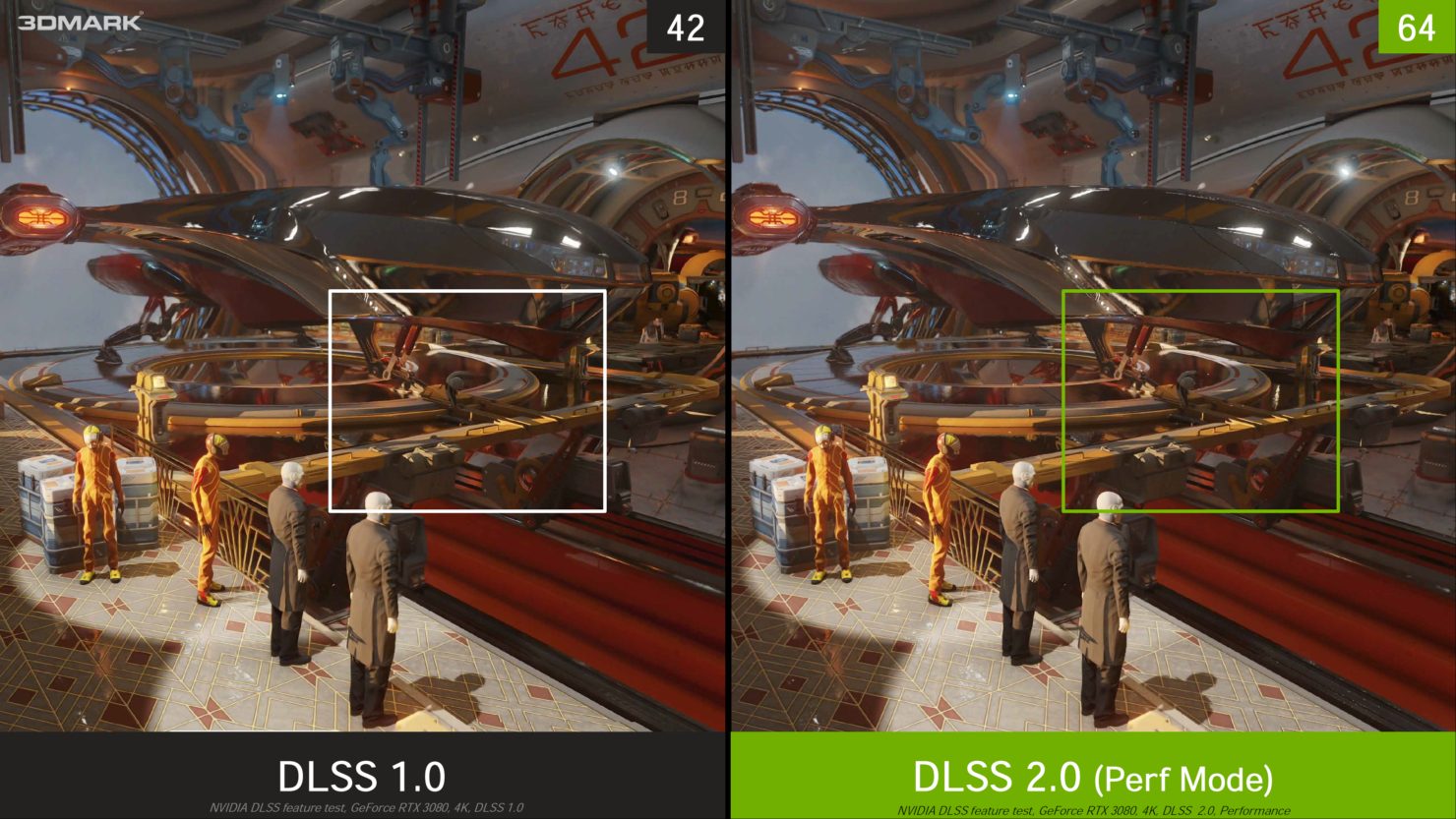
DLSSを用いてアップスケールした画像が元の品質に達しているかどうかに関しては諸説あるところですが、8Kと言う現在のGPUでは不可能な解像度で映像を作ろうとした場合、不可能を可能にする技術であるDLSSは現在の品質でもかなり存在価値が高いと思います。
DLSSはAI処理を使って論理的な処理能力の限界を超える技術です。
出た当初は品質などの様々な難点がありましたが、私が確認した限りではバージョンアップを経て、4Kまではほぼ問題の無い品質になったのではないかと思います。
ここまで来ると、残念なのはプロモーションです。
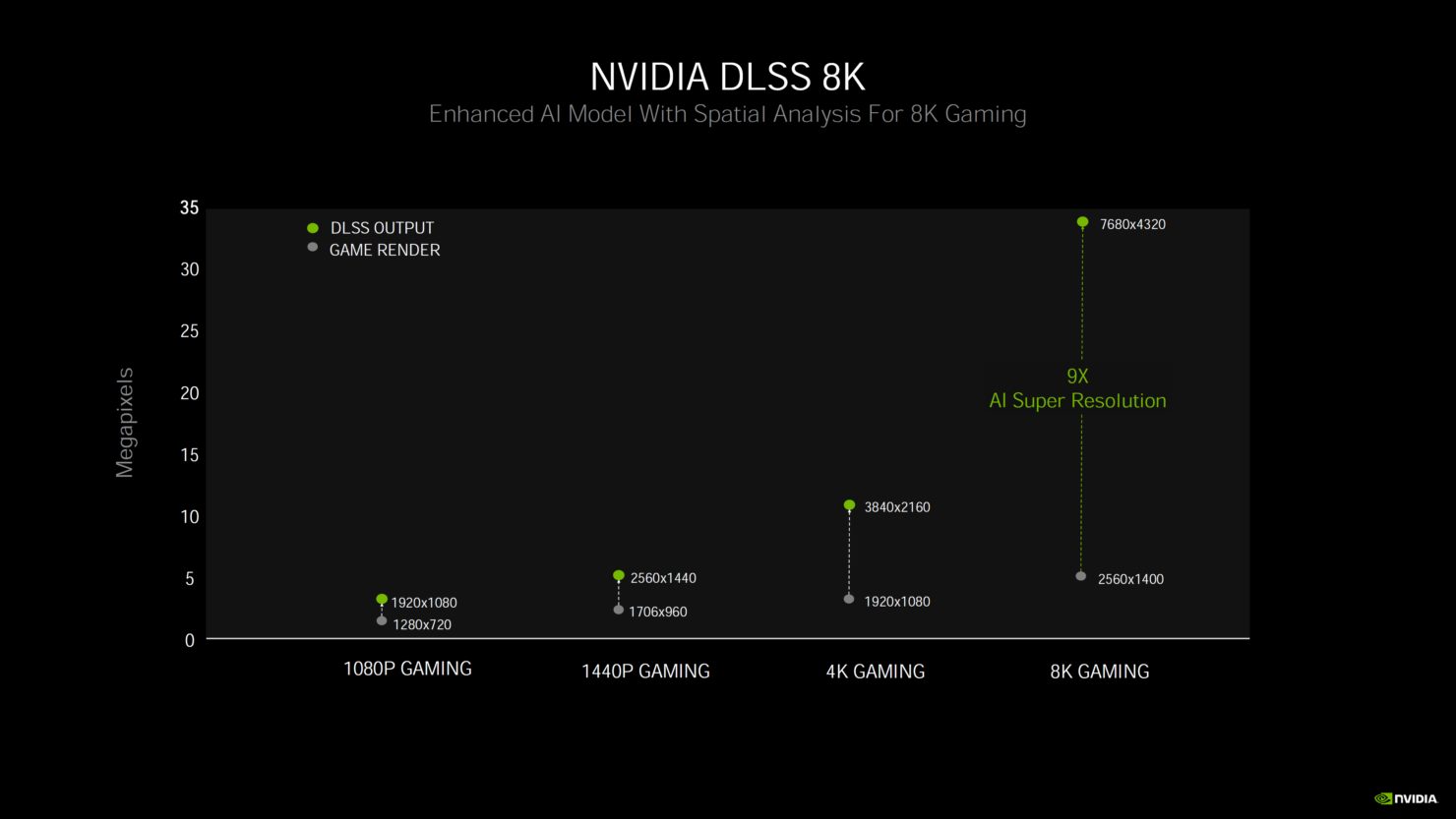
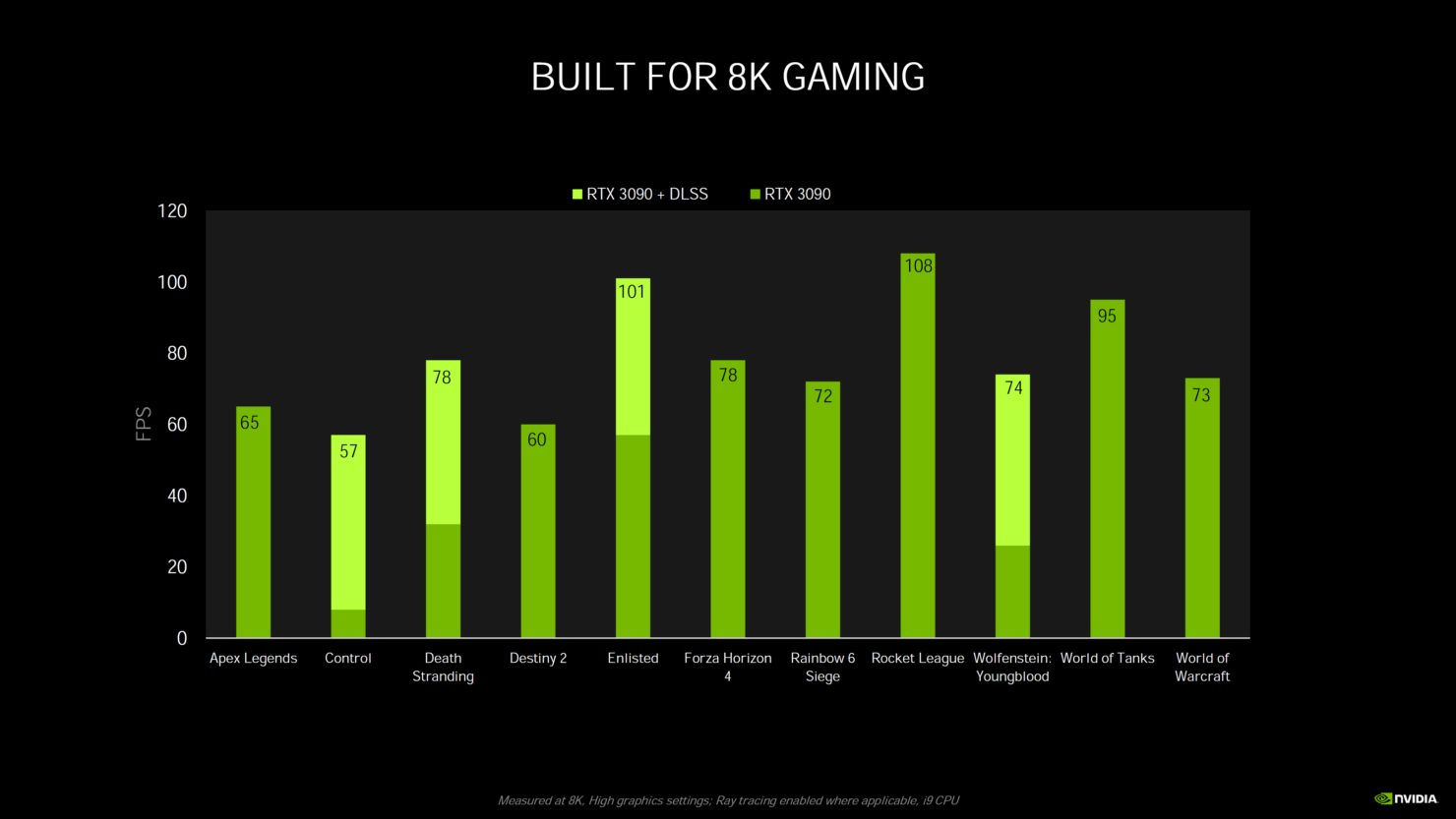
8KのPCモニターと言うのは現在ではほとんど存在していません。
RTX3090や3080の発売に合わせて、5K/6K/8Kのモニターが発売されればそれなりに盛り上がったのではないかと思います。
8Kと言うのはつい最近まで、HDMI端子を複数束ねて無理やり映像を出力していた出たばかりの解像度です。
RTX3000シリーズに関してはHDMI出力は8K対応のHDMI2.1になっていますが、それでも気軽に買える値段で8Kのモニターが購入できるわけではありません。
この点を考えても未来からやってきたGPUにふさわしい製品だと思います。