
NVIDIAの次世代GPUはまもなく発表され、GTCはオンラインのみのイベントに移行しましたが、グリーンジャイアントがこれまでで最大のGPUを発表するのを妨げていません。
数日前に未リリースの2つのGPUの仕様がリークされていましたが、Twitterの仲間W_At_Ar_Uによって新しいSKUが発見されたようです。最新のチップは、総コア数が約8Kコアの独自の獣です。
NVIDIAの次世代GPUのパフォーマンスと仕様のリーク-最大8000コアと48 GB HBM2eメモリを備えた究極のHPCパワーハウス
Ampereとコードネームが付けられたとされるNVIDIA次世代GPUアーキテクチャは、しばらくの間知られています。
HPCおよびクラウドデータセンターのトップ組織で使用される予定の同社の最新のTesla GPUをさらに強化します。
情報技術担当バイスプレジデントおよびインディアナ大学の最高情報責任者によると、今年の夏にビッグレッドスーパーコンピューターを導入すると、NVIDIAの次世代GPUが既存のVoltaベースのGPUに比べて75%のパフォーマンスを大幅に向上させることが明らかになりました 。
過去に聞いたことがありますが、GPUが最大50%のパフォーマンス向上と2倍の効率性を提供するという報告もありますが、これは信じられないほどの偉業です。

そこで、Geekbenchで発見された最新のGPUの仕様について説明します。また、以前にリークされたパーツと比較して、すべての製品から期待されるパフォーマンスの向上を確認します。
これらのGPUは2019年の10月と11月にずっとテストされたことに注意してください
彼らは数ヶ月間Geekbenchデータベースに隠れていますが、これらはまだ初期のサンプルであるため、仕様に間違いなく大きな変化が見られます。ここで注意すべきもう1つのことは、クロックが遅いことです。
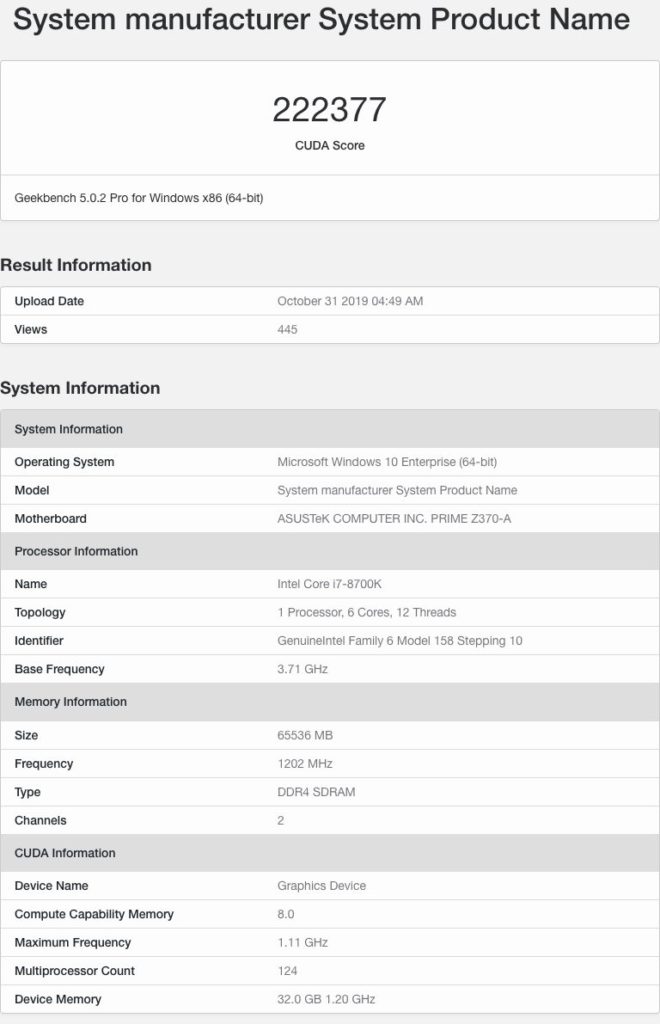
NVIDIAの次世代GPU#1の仕様とパフォーマンス
最初に話したGPUは、最近発見されたGPUです。
NVIDIAのプロフェッショナルGPUアーキテクチャには、ストリーミングマルチプロセッサごとに64 CUDAコア設計が付属しているため、このGPUは7936 CUDAコアに等しい124の合計SMカウントを備えています。
これは、Tesla V100の5120コアを超えるCUDAコアの55%の増加です。
GPUの最大クロック速度は1.1 GHzであり、この最終化されていないクロックで、約17.5〜18 TFLOPのFP32演算能力を発揮します。
1200 MHzで32 GBのHBM2eメモリクロッキングを搭載し、4096ビットのバスインターフェイスで動作します。
私がHBM2eに言及する理由は、それが最新の標準であり、NVIDIAが発売時にHPCパーツで最も高度なメモリ標準を利用することが知られているためです。
コアおよびメモリの仕様に加えて、GPUは32 MBのL2キャッシュをパックします。これは、わずか6 MBのL2キャッシュをパックするVolta GV100 GPUの5.33倍の増加です。
膨大な量のキャッシュを考えると、NVIDIAの次世代GPUでの長年の開発により、パフォーマンスが大幅に向上し、アーキテクチャが大幅に変更されることが予想されます。
パフォーマンスに関しては、Geekbench 5のOpenCLベンチマーク(CUDA)でGPUが222377ポイントを獲得しています。プラットフォームはCUDA 8.0を実行しており、テスト時にGPUが完全に最適化されていなかった可能性が高いです。
そうは言っても、このカードの仕様は文字通り非常識に見えるので、他の2つのバリエーションに取り掛かりましょう。
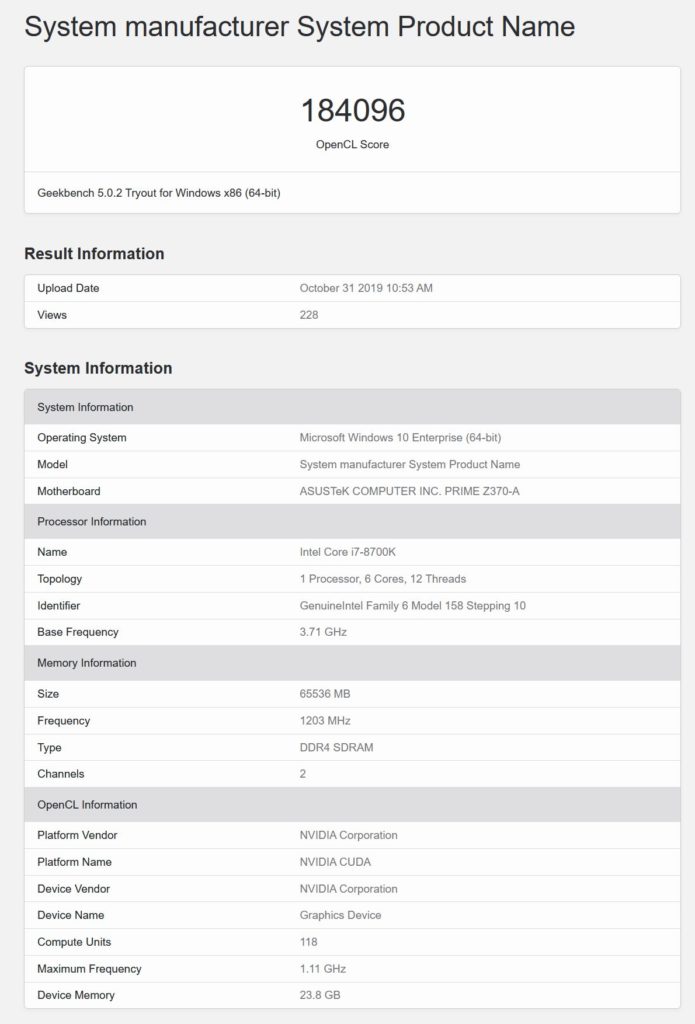
NVIDIAの次世代GPU#2仕様とパフォーマンス
2番目のGPUには、合計118個のSMまたは7552 CUDAコアが搭載されています。
これは、80個のSMと合計24 MBのL2キャッシュに5120個のCUDAコアが詰め込まれたTesla V100よりもCUDAコアが47.5%増加したことです。
また、このGPUは1.10 GHzの最大速度でクロックされ、1200 MHzのクロック速度で3072ビットのバスに沿って実行される24 GBのHBM2eメモリを備えています。
これらの速度では、このチップは約16.7 TFLOPの合計理論計算馬力を提供するはずですが、再び、クロック速度は間違いなく最終的に見えず、それより高くなる可能性があります。
For some context :
GV100 : 142837 (Open CL)
Tesla V100 : 154606 (Open CL)
Titan RTX : 132804 (Open CL)— _rogame (@_rogame) February 28, 2020
この特定のGPUは、OpenCLとCUDA Computeの両方のベンチマークでテストされました。
OpenCLベンチマークでは、チップは184096ポイントを獲得しましたが、CUDAベンチマークでは169368ポイントを獲得しました。
124パーツと118パーツの両方のSMパーツはCUDA 8.0上で実行されていましたが、Geekbench 5ベンチマークに対してこれらのGPUがまだ完全に最適化されていないことがわかります。
コア数にわずか5%の違いがあるにもかかわらず、両方の部分のスコアに大きな違いがあります。
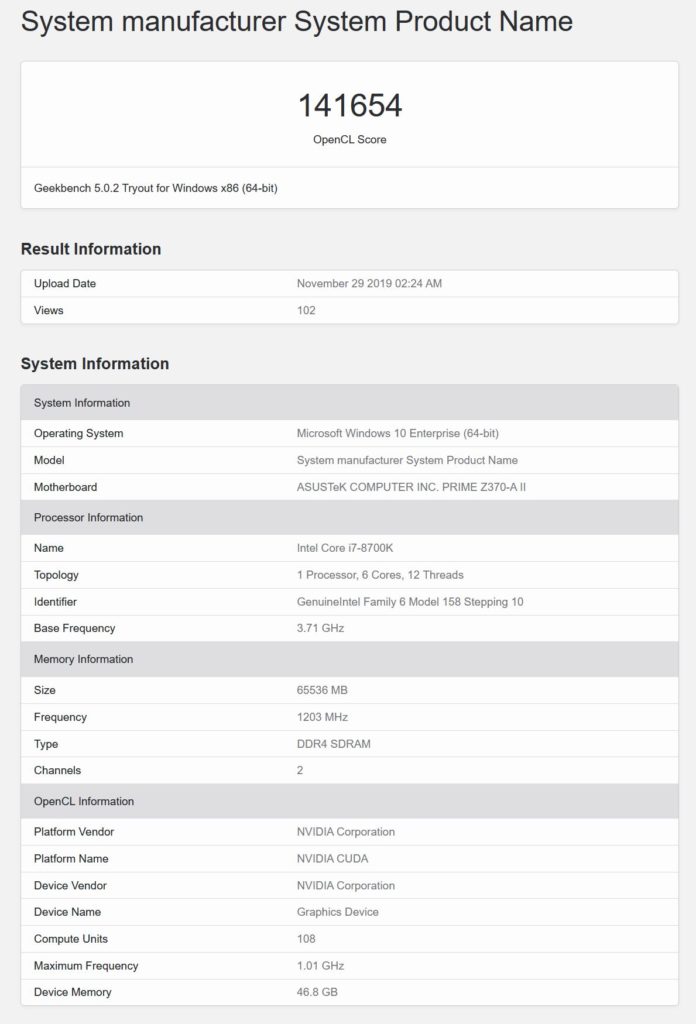
NVIDIAの次世代GPU#3仕様とパフォーマンス
最後に、108 SMまたは6912 CUDAコアバリアントがあり、1.01 GHzのクロック速度または3つすべてのGPUの中で最も遅いことが報告されています。 GPUは、Tesla V100よりもCUDAコア数が35%増加し、明らかに46.8 GBのHBM2eメモリを搭載しています。
これは、Geekbenchベンチマークが合計メモリをどのように認識するかに関するエラーである可能性があり、実際には48 GBである可能性があり、これはより理にかなっています。 このGPUはGeekbench 5(CUDA)ベンチマークで141654ポイントを獲得しますが、これもまたクロック速度が遅いため最終スコアではありません。
NVIDIA Teslaグラフィックカードの比較
| Tesla GPU カード名 | NVIDIA Tesla M2090 | NVIDIA Tesla K40 | NVIDIA Telsa K80 | NVIDIA Tesla P100 | NVIDIA Tesla V100 | NVIDIA Tesla Next-Gen #1 | NVIDIA Tesla Next-Gen #2 | NVIDIA Tesla Next-Gen #3 |
| GPU アーキ テクチャー | Fermi | Kepler | Maxwell | Pascal | Volta | Ampere? | Ampere? | Ampere? |
| 製造 プロセス | 40nm | 28nm | 28nm | 16nm | 12nm | 7nm? | 7nm? | 7nm? |
| GPU名 | GF110 | GK110 | GK210 x 2 | GP100 | GV100 | GA100? | GA100? | GA100? |
| ダイ サイズ | 520mm2 | 561mm2 | 561mm2 | 610mm2 | 815mm2 | 不明 | 不明 | 不明 |
| トランジスタ数 | 30億 トランジスタ | 70.8億 トランジスタ | 70.8億 トランジスタ | 150億 トランジスタ | 211億 トランジスタ | 不明 | 不明 | 不明 |
| CUDA コア数 | 512 Ccs (16 CUs) | 2880 Ccs (15 CUs) | 2496 CCs (13 CUs) x 2 | 3840 CCs | 5120 CCs | 6912 CCs | 7552 CCs | 7936 CCs |
| クロック | Up To 650 MHz | Up To 875 MHz | Up To 875 MHz | Up To 1480 MHz | Up To 1455 MHz | 1.08 GHz (Preliminary) | 1.11 GHz (Preliminary) | 1.11 GHz (Preliminary) |
| FP32 演算能力 | 1.33 TFLOPs | 4.29 TFLOPs | 8.74 TFLOPs | 10.6 TFLOPs | 15.0 TFLOPs | ~15 TFLOPs (Preliminary) | ~17 TFLOPs (Preliminary) | ~18 TFLOPs (Preliminary) |
| FP64 演算能力 | 0.66 TFLOPs | 1.43 TFLOPs | 2.91 TFLOPs | 5.30 TFLOPs | 7.50 TFLOPs | 不明 | 不明 | 不明 |
| VRAM 容量 | 6 GB | 12 GB | 12 GB x 2 | 16 GB | 16 GB | 48 GB | 24 GB | 32 GB |
| VRAM 種類 | GDDR5 | GDDR5 | GDDR5 | HBM2 | HBM2 | HBM2e | HBM2e | HBM2e |
| メモリ バス幅 | 384-bit | 384-bit | 384-bit x 2 | 4096-bit | 4096-bit | 4096-bit? | 3072-bit? | 4096-bit? |
| メモリ 速度 | 3.7 GHz | 6 GHz | 5 GHz | 737 MHz | 878 MHz | 1200 MHz | 1200 MHz | 1200 MHz |
| メモリ 帯域幅 | 177.6 GB/s | 288 GB/s | 240 GB/s | 720 GB/s | 900 GB/s | 1.2 TB/s? | 1.2 TB/s? | 1.2 TB/s? |
| 最大TDP | 250W | 300W | 235W | 300W | 300W | 不明 | 不明 | 不明 |
しかし、おもしろいのは、ローエンドのGPUがより多くのメモリ容量を備えていることで、NVIDIAは、特定のワークロードに対してより高いメモリ容量のローエンドGPUを搭載するか、各GPUが異なるメモリ構成を持ち、48 GB HBM2eがこの特定のGPU SKUの最高のメモリ構成になる可能性があります。
この仕様リークからわかるもう1つの最も興味深いことは、次世代のTeslaラインナップにはさまざまなGPU SKUがありますが、完全なGPUは間違いなく128 SMにパックされた8192 CUDAコアでピークになるはずです。
Volta GV100 GPUと同様に、5376 CCまたは84 SMを含むフルチップにもかかわらず、Tesla V100は5120 CUDAコア(80 SM)でピークに達したため、完全なファット(次世代)GPUは決して公開されません。
前回のインタビューで、NVIDIAのCEOであるJensen Huangは、次世代7nm GPUの注文の大部分がTSMCによって処理され、少量が生産のためにSamsungに送られることを確認していました。
最後に、ジェンセンは次世代7nm GPUの発売時期について尋ねられましたが、彼は現時点で日付を開示するのに都合のよい時間ではないと答えました。
NVIDIAのCFOであるColette Kressとの最近のインタビューから、彼らは7nm GPUの発表でみんなを驚かせたいと思っていることを知っていますが、そうするタイミングを待っています。
一方、AMDは、Arcturus GPUをベースとするRadeon Instinct Mi100 HPCアクセラレーターの発表も予定されています。これは、8192 SPを搭載し、最新の7nm GPUアーキテクチャに基づいていると伝えられています。
ただし、NVIDIAが過去に証明したように、より高度なノード(16nm対12nmおよび12nm対7nm)に基づく競合他社のGPUに対して超効率的かつ競争力のあるポイントまでアーキテクチャを最適化できることを証明しています。
NVIDIAは、次世代GPUとまったく新しいアーキテクチャを備えたAMDと同等のプロセスであるため、実際の破壊的なパフォーマンスが確認できます。
これらは間違いなくNVIDIAの次世代GPUの大きな仕様であり、3月22日に開催されるGTC 2020オンラインキーノートで、NVIDIAによる本格的な発表が期待できます。
解説:
nVidiaの次世代GPUに関するリーク情報を先日紹介しましたが、今度はTeslaとみられるGPUのリークがありました。
これがAmpereならばTesla A100となるはずです。
この次世代GPUはゲーム向けとしても使われるか?
皆さん興味があるのは次期GeforceがどうなるかであってQUADROやTeslaなんてどうでもよいというのが本音でしょう。(笑
機械学習/HPC向けとして出たGPUはVoltaのみであり、むしろVoltaが特殊だったと考えたほうが良いと思います。
これらのGPUはゲーム向けとしても出ると私は思います。
そう考える主な理由は性能向上の方法論がCUDAコアを増やすという力業によっているところです。
GPUのように似たような回路の集合体を並列に動作させて性能を稼ぐという世界において、数を増やすというのはどんな用途向けでも性能を稼ぐことができる万能の解決策であり、HPC向けに限らず、ゲーム向けにも降りてくるものと思います。
ここで問題になるのは、PS5やXbox Scarlettが大量のGDDR6を調達するというところですね。
メモリの容量が増えれば当然配線も増え、実装されるチップも増えコストに跳ね返ってきます。
今回のトップモデルは噂ではRTX2080Tiよりも若干安くなるといわれていますが、微妙なところではないでしょうか。
コスト増に直結するメモリのバス幅を増やすという力業に出るのは、もはやGDDR6のメモリ帯域では性能が稼げないところまで来ているということです。
いずれにしても3/22以降に公式で何らかの発表がある可能性は非常に高くなったといってもよいでしょう。