Nvidiaは、今後もGPUの性能を急速に向上させることを期待している。

OpenAIのトップであるサム・アルトマンがチップ・ベンチャーの設立を検討していると最初に聞いたとき、私たちは感心したが、既製のプロセッサを使用する代わりにカスタム・シリコンを採用する企業のもう1つの標準的なケースだと考えた。
しかし、AIチップのための工場網を構築するために5兆ドルから7兆ドルを調達すると報じられた潜在的投資家とのミーティングは、世界の半導体産業全体が年間1兆ドル程度と見積もられていることを考えると、極端な話である。エヌビディアのジェンセン・フアンは、AIのためだけの代替半導体サプライチェーンを構築するために、そこまでの投資は必要ないと考えている。
その代わり、業界はGPUアーキテクチャのイノベーションを継続し、性能を向上させ続ける必要がある。事実、フアン氏は、Nvidiaは過去10年間ですでにAIの性能を100万倍に向上させたと主張している。
「コンピュータがこれ以上速くなることはないと仮定すれば、14の異なる惑星と3つの異なる銀河、さらに4つの太陽が必要だという結論に達するかもしれません」とジェンセン・フアンは世界政府サミットで語った。
AIデータセンター用に十分なチップを製造するために数兆ドルを投資すれば、今後3~5年の間に不足の問題を解決できるのは確かだ。
しかしエヌビディアのトップは、AIのためだけに別の半導体供給産業を創設することは、ある時点でチップの供給過剰と大きな経済危機を招く可能性があるため、必ずしも最善のアイデアとは言えないかもしれないと考えている。
AIプロセッサーの不足は、アーキテクチャーの革新によってもいずれ解決され、AIを自社内で利用したい企業は、10億ドル規模のデータセンターを建設する必要はなくなるだろう。
「アーキテクチャの性能も同時に向上していることを忘れてはならない。「コンピュータが高速化し、必要な総量が少なくなることも想定しなければなりません。
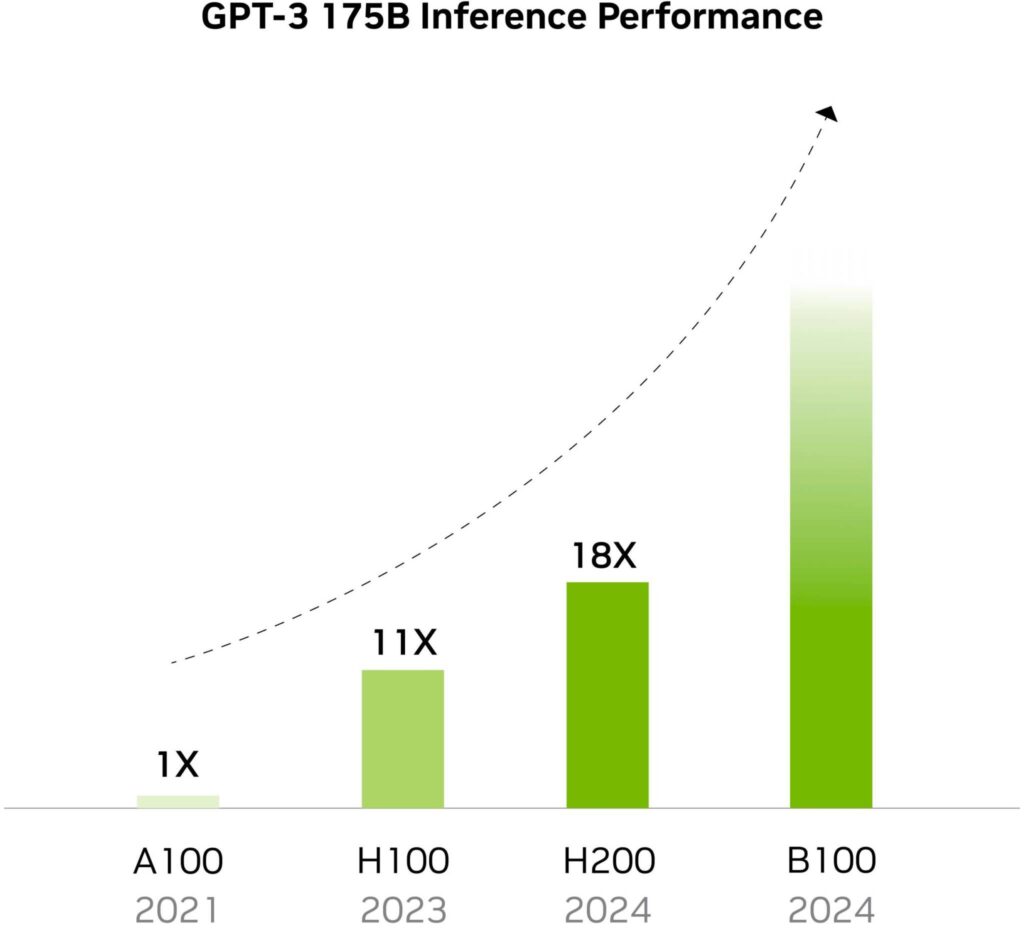
実際、AIやハイパフォーマンス・コンピューティング(HPC)の性能に関しては、NvidiaのGPUは非常に速く進化する。NvidiaのV100データセンターGPUの半精度計算性能は、2018年にはわずか125TFLOPSだったが、Nvidiaの最新のH200は1,979 FP16 TFLOPSを提供する。
「最も偉大な貢献のひとつは、イノベーションの速度です。
「私たちが行った最大の貢献の1つは、この10年間でコンピューティングとAIを100万倍進歩させたことです。
したがって、あなたが世界の動力源になると考えている需要が何であれ、(コンピュータが)それを(今後10年間で)100万倍高速化するという事実も考慮する必要があります。
解説:
nVIDIAのCEOがデータセンターに巨額の投資を続ける必要はないと主張。
理由はアーキテクチャーの刷新によって性能が飛躍的に向上しているからということです。
おそらく、nVIDIAのラボでは今後どのようにAI/ML性能を上げていくかということの方向性がおおよそ決まっているのでしょう。
それに沿った発言なのではないですかね。
nVIDIAの考える生成AIはゲームにおいてはキャラクターですらもリアルタイムで生成するというもののようです。
実際に10年間で100万倍に進歩させたということですので、あながち夢とも言い切れませんね。
実際、8bit optimizerのbitsandbytesを見ていると、去年の夏ごろに8bit演算に対応し、去年の末あたりから4bit演算に対応しており、急速に性能を上げています。
なぜ演算のbit数を下げているかというと、AIは精度の高い演算を数少なく行うよりも精度の低い演算を何度も行ったほうが良い学習結果が得られることが知られているからです。
こうした周辺ソフトウェアも急速に進歩しているので、今後も飛躍的に伸び続けるのでしょう。
ただし、多くの人や資金が集中しているのはすべてnVIDIA製品であり、AMDやIntelはこれからといったところです。
わたくしはROCmで画像生成AIをセットアップするお手伝いをしていますので、よくわかります。
おそらく、nVIDIA、intel、AMD三社の中でいちばんソフトの環境が整っていないのがAMDだと思います。
Intelはソフトウェアの開発能力が桁違いですから、早ければ2-3年、5年後にはnVIDIAとほぼ変わらない使い勝手を実現できる可能性はあると思います。
ただし、この話は今の単体GPUであるARCがGeforceの性能に追いつくのが大前提です。
そこはなかなか難しいかもしれません。
安定性はあと2年でどうにかなっても、性能でnVIDIAに追いつけるかな?と今のARCを見ていると思います。
AMDはROCmをコンシュマー製品にも広げることとRadeonのAI/ML性能を上げるのが先ですね。
現状でもそこそこ動きますが、AMDがコンシュマーでの動作を保証しないのはその品質に達していないということなのでしょう。
もしくは受けられる利益がないということなのかもしれません。なかなか厳しい話です。
先日WindowsとLinuxで画像生成AIの性能を比較する記事を上げましたが、Linux同士で比較してもことAI/MLに関してはnVIDIAのほうが三歩くらい先を行っていると言わざるを得ない状況です。(苦笑。
この状態でAMDを選ぶのは勇気を通り越して無謀と言わざるを得ません。
※ お断りしておきますが、ゲームではなく、AI/MLの話です。
現時点のAMDはRDNA4の上位モデルを放棄してMI300A/X(またはその後継製品)に全力投球しています。
わたくしなど大したレベルではありませんが、周辺を少しいじっているからこそ実感します。
AMDには早期にROCmをコンシュマーに開放してほしいですね。
[st_af id="7964"]