
Stability AIは、Intel Gaudi 2とNVIDIAのH100およびA100 GPUアクセラレータのAIベンチマーク対決を掲載した新しいブログ記事を発表した。
ベンチマークは、Intelのソリューションが大きな価値を提供し、NVIDIAの製品と比較して高速ですぐに利用可能なソリューションを求める顧客にとって、尊敬に値する選択肢であることを示している。
インテル対NVIDIAのAIアクセラレータ対決: Gaudi 2がStable DiffusionとLlama 2 LLMsでH100とA100に対して強力なパフォーマンスを発揮。
AI企業のStability AIは、多様なタスクを効率的に処理できるオープンモデルを作ってきた。
これをテストするため、Stability AIは、Stable Diffusion 3を含む同社の2つのモデルを使用し、NVIDIAとIntelの最も人気のあるAIアクセラレータ間でベンチマークを実施し、互いのパフォーマンスを確認した。
インテルのAIアクセラレーターGaudi 2は、非常に人気のあるテキストから画像へのモデルの次の章であるStability Diffusion 3で、いくつかの例外的な結果を提供しました。
このモデルは800Mから8Bパラメータまであり、2Bパラメータバージョンを使用してテストされました。
比較のため、インテルとNVIDIAのアクセラレーターを合計16台搭載した2ノードを使用し、バッチサイズはアクセラレーター1台につき16、最大バッチサイズは512に設定した。
その結果、Intel Gaudi 2はH100 80GB GPUに対して56%のスピードアップを、A100 80GB GPUに対しては2.43倍のスピードアップを実現した。
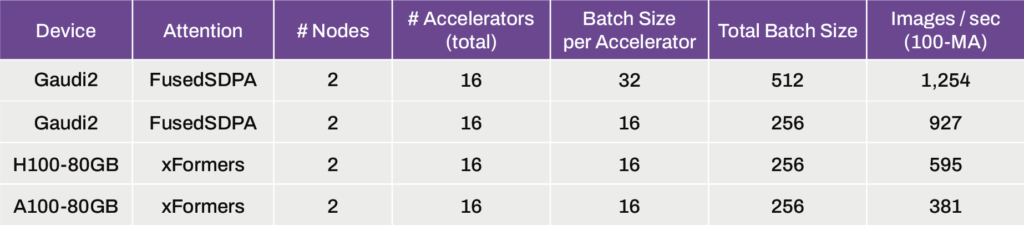
また、96GBのHBM容量により、インテルのGaudi 2は、アクセラレーターごとに32のバッチサイズ、合計512のバッチサイズに対応することができた。
これは、16バッチのGaudi 2アクセラレータの35%、H100 80GBの2.10倍、A100 80GBのAI GPUの3.26倍のスピードアップである。

Gaudi 2とA100 80 GB GPUの両方で32ノード(256アクセラレータ)にスケールアップすると、Intelソリューションでは3.16倍の向上が見られ、49.4画像/秒/デバイスを出力できるのに対し、A100ソリューションではわずか15.6画像/秒にとどまる。
トレーニング性能はGaudi 2 AIアクセラレータで優れているが、NVIDIAは、前年を通して大きな進歩を遂げたTensor-RT最適化のおかげで、推論において依然として王座を維持しているように見える。
A100 GPUは、Gaudi 2アクセラレータと同じStable Diffusion 3 8Bモデルの下で、これらの特定のワークロードにおいて最大40%高速に画像を生成すると言われている。
Stable Diffusion 3 8Bパラメータモデルを用いた推論テストにおいて、Gaudi 2チップは、ベースとなるPyTorchを用いたNvidia A100チップと同程度の推論速度を提供します。しかし、TensorRTの最適化により、A100チップはGaudi 2よりも40%高速に画像を生成しました。さらなる最適化により、Gaudi 2はこのモデルですぐにA100を上回ると予想しています。PyTorchをベースとしたSDXLモデルでの以前のテストでは、Gaudi 2は1024x1024の画像を30ステップで3.2秒で生成したのに対し、A100でのPyTorchでは3.6秒、A100でのTensorRTによる生成では2.7秒でした。
Gaudi 2の高いメモリ容量と高速インターコネクト、さらにその他の設計上の配慮により、この次世代メディアモデルを支えるDiffusion Transformerアーキテクチャを実行する上で競争力がある。
Stability AIより
最後に、LLaMA 2 70Bを微調整したStable Beluga 2.5 70Bの結果を示します。
PyTorchで動作させた場合、256基のIntel Gaudi 2 AIアクセラレータは平均116,777トークン/秒のスループットを達成した。
これは、TensorRTで動作するA100 80GBソリューションよりも約28%高速でした。
これはすべて、AIがいかに競争的な状況になりつつあるかを示すものであり、最も重要なのはハードウェアではなく、ソフトウェアと特定のアクセラレーターごとの最適化なのだ。
ハードウェアは不可欠だが、最新で最高のものを用意しても、それらのコア、メモリー、さまざまなAI専用アクセラレーターをすべて駆動する強固な基盤がなければ、この分野では厳しい時間を過ごすことになるだろう。

NVIDIAはこのことを長い間知っていたため、IntelとAMDはAI向けのソフトウェア・スイートを固め始めたばかりであり、緑の巨人に追いつくか、それとも迅速なソフトウェア・リリースでCUDA/Tensorアーキテクチャに取り組むことができるかはまだわからない。
これらのベンチマークは、IntelがNVIDIAの提供する製品に対抗するための代替ソリューションとしてだけでなく、競争力のあるソリューションとして、非常に現実的なソリューションになりつつあることを示しており、将来のGaudiとAI GPUの提供により、1つの企業に依存するのではなく、顧客が選択できる優れたソリューションを備えた、より強固なAI分野が期待できる。
解説:
IntelのAI/MLアクセラレーターGaudi2
ここでもnVIDIAのH100やA100より強力であるという話が出ています。
現在nVIDIAはAI/MLアクセラレーターの供給が需要に応えられておらず、競合製品に注目が集まっていますが、これもその一環でしょう。
どこのAI/ML関連企業、部門も自社の未来の業績をnVIDIA一社の供給能力に頼るのは危険だと考えているのだと思います。
nVIDIA製品は素晴らしいと思います。AMDやIntelがいくらnVIDIA製品より優れていると喧伝しても実際に使用するソフトウェア環境をそろえるとやはり差がついてしまうというのが実際のところではないでしょうか。
ホビーユーザー視点ですが、ROCm用のAI/MLフレームワークなどをビルドしている立場から言えば、「現時点では」nVIDIA製品と同等以上にはならないというのが実感です。
ROCmは確かに素晴らしい仕組みだと思いますし、Intelのipexも第一世代の製品用としてはこの上もなく優れていると思います。
しかし、競争相手として同等以上の使い勝手にならないのはちょっと厳しいのかなと思います。
何より、nVIDIAのH100やA00はプロダクトサイクル終盤であり、もう次の製品の話が出ています。
Blackwellに勝てるのかどうかで言えば難しいのかなと思います。
nVIDIAも競合相手が出てきたことによって、AI/MLアクセラレーターは2年更新から毎年更新になるといわれています。
そういったことを考えるとあと2-3年はnVIDIA製品と同等の性能と使い勝手を実現する製品は出てこないのかなと思います。
証券アナリストの業績予想も2024年もnVIDIA独り勝ちはほぼ確定しているとされています。
変化が起きるとしたら2025年以降でしょう。
もちろんわたくしの視点はあくまでも一般用のRDNA3とAda Lovelaceを比較したものなので単純にサーバーの世界でどうなのかということは語れないと思います。
しかし、明確な差があることは確かです。