AMDはまた、NvidiaがTensorRT-LLMで行ったテストと同様の状況を、サーバーのワークロードで典型的なレイテンシを考慮しながら行うことで、一歩先んじた。

AMDもNvidiaも、Instinct MI300XとH100(Hopper)GPUの性能差に関わるこの議論から手を引くつもりはない。
しかし、AMDは、TensorRT-LLMでのみ動作するFP8に対して、より一般的な選択肢であるvLLMを使用したFP16を比較しながら、いくつかの強力なポイントを指摘している。
レッドチームは今年12月初めにMI300Xグラフィックス・アクセラレーターを発表し、NvidiaのH100に対して最大1.6倍のリードを主張した。
2日前、Nvidiaは、H100とTensorRT-LLMを比較する際、AMDは自社の最適化を使用していないと反撃した。
その返答は、Llama 2 70Bチャットモデルを実行しながら、8ウェイのH100 GPUに対してシングルH100に達した。
続くベンチマーク結果とテストシナリオの戦争
この最新の回答でAMDは、Nvidiaが使用した推論ワークロードは選択されたものであると述べている。
さらにNvidiaは、オープンソースで広く使用されているvLLMではなく、H100上で自社開発のTensorRT-LLMを使用してベンチマークを行ったことを明らかにした。
さらに、NvidiaはAMDに対してvLLMのFP16パフォーマンスデータ型を使用し、DGX-H100とその結果を比較したが、DGX-H100はFP8データ型のTensorRT-LLMを使用し、これらの誤認されたとされる結果を表示した。
AMDは、テストではvLLMが広く使用されているためFP16データセットを使用し、vLLMはFP8をサポートしていないと強調した。
また、サーバーにはレイテンシーが存在するが、Nvidiaはそれを考慮する代わりにスループット性能を示したのであり、実際の状況をエミュレートしたわけではない、とAMDは指摘している。
AMDは、より多くの最適化とNvidiaのテスト方法によるレイテンシの考慮により、テスト結果を更新した。
AMDは、NvidiaのTensorRT-LLMを使用して3回の性能測定を行った。
最後の注目すべきテストでは、FP16データセットを使用して、TensorRT-LLMを使用したH100に対するMI300XとvLLMのレイテンシを測定した。
しかし、最初のテストでは、両方でvLLMを使用したため、FP16を使用した2つの比較が行われ、2番目のテストでは、TensorRT-LLMを比較しながら、vLLMを使用したMI300Xのパフォーマンスを比較した。
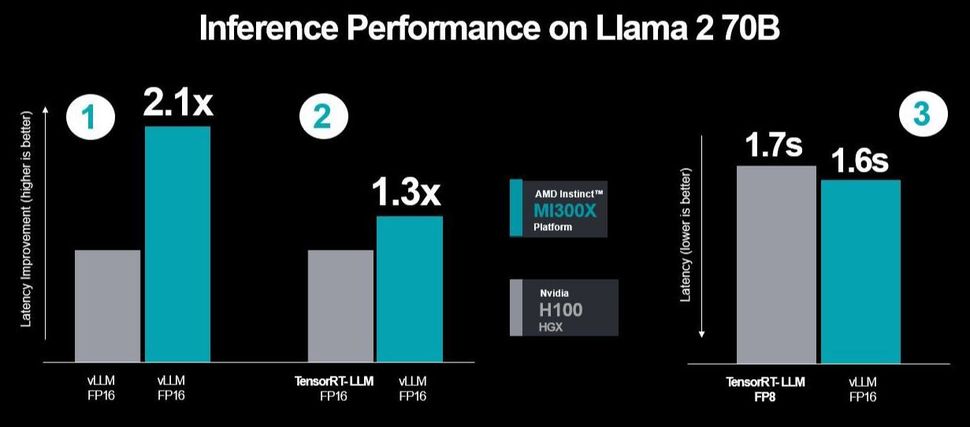
そこでAMDは、2番目と3番目のテストシナリオでNvidiaが行ったのと同じ選択されたテストシナリオを使用し、より高い性能とレイテンシの減少を示した。AMDは、両方でvLLMを実行しながら、H100と比較してより多くの最適化を追加し、性能を2.1倍向上させた。
Nvidiaがどのように対応するかは、今後の評価次第である。
しかし、そのためには業界がFP8を使用するTensorRT-LLMのクローズド・システムでFP16を捨て、実質的にvLLMを永久に捨てる必要があることも認める必要がある。
あるRedditorは、Nvidiaのプレミアムについて言及しながら、"TensorRT-LLMはロールスロイスに無料でついてくるものと同じように無料だ "と言ったことがある。
解説:
ドル箱のデータセンター向けAI/MLアクセラレーターを巡るAMDとnVIDIAの仁義なき戦い。
nVIDIAがAMDのMI300Xはそれほどの性能ではないと実例を出して言えば、AMDは最適化されたベンチマーク結果を出してきて反撃する。
目下、飛ぶように売れているデータセンター向けAI/MLアクセラレーターなだけに両社とも必死です。
一説によると、RDNA4の上位モデルがキャンセルされたのは生産のキャパをMI300A/Xに向けるためとも言われており、それが本当だとするならば複雑な気分です。
RDNA4の上位モデルを犠牲にしたかもしれないMI300A/Xが素晴らしい性能を発揮してい欲しいと思うと同時にRDNA4がROCmでサポートされるのかどうかを早く教えてほしいと思います。
RadeonでホビーAI/MLはかなり少数派だと思いますが、それでも今一番ホットな分野ですから、こうした活動も後押ししてほしいところです。
よろしくお願いします。