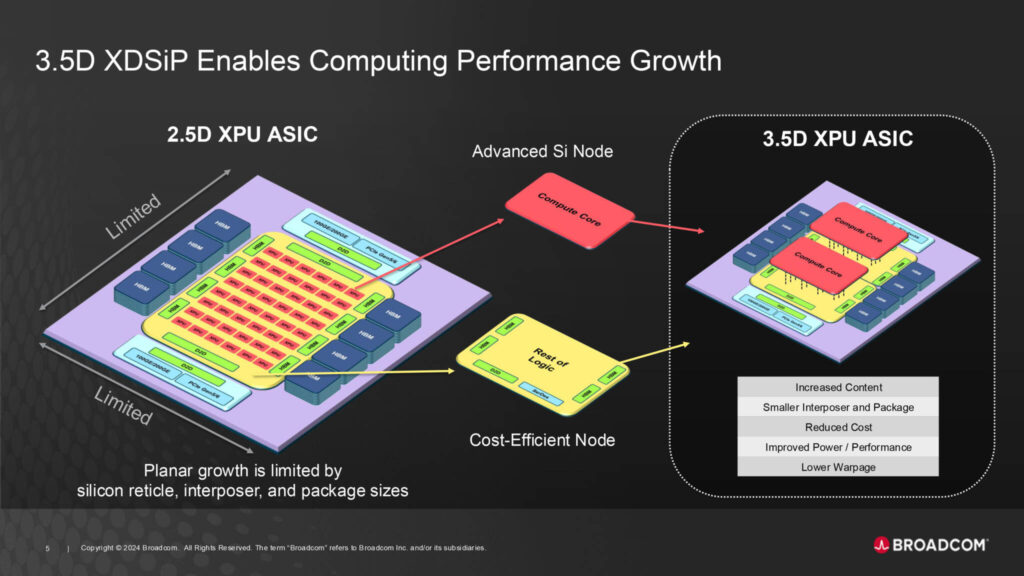
Broadcom は、性能と効率を大幅に向上させるカスタム コンピュート プラットフォームに特化した「最先端」の 3.5D XDSiP プラットフォーム テクノロジーを発表しました。
Broadcom の最新 3.5D XDSiP プラットフォームが、AI および HPC ワークロードに特化した大規模 AI XPU を実現
[プレス リリース]: Broadcom Inc.は本日、3.5D eXtreme Dimension System in Package (XDSiP) プラットフォーム技術の提供を発表し、コンシューマ AI の顧客が次世代カスタム アクセラレータ (XPU) を開発できるようにしました。
3.5D XDSiP は、6000 mm² を超えるシリコンと最大 12 個の高帯域幅メモリ (HBM) スタックを 1 つのパッケージ デバイスに統合し、AI 向けの高効率かつ低消費電力のコンピューティングを大規模に実現します。
Broadcomは、業界初のFace-to-Face (F2F) 3.5D XPUを開発し、発売することで、重要なマイルストーンを達成しました。
ジェネレーティブAIモデルのトレーニングに必要な膨大な計算能力は、10万から100万XPUの巨大なクラスタに依存している。
これらのXPUは、消費電力とコストを最小限に抑えながら、必要なパフォーマンスを達成するために、計算、メモリ、I/O機能をますます高度に統合する必要がある。
ムーアの法則やプロセス・スケーリングのような従来の方法では、このような要求に追いつくことは困難です。
そのため、次世代のXPUには、高度なシステム・イン・パッケージ(SiP)統合が不可欠となっている。
過去10年間、2500mm²までの複数のチップレットと8個までのHBMモジュールをインターポーザー上に集積する2.5D集積は、XPU開発にとって価値があることが証明されてきました。
しかし、ますます複雑化する新しいLLMが導入されるにつれて、そのトレーニングでは、サイズ、消費電力、コストを改善するために3Dシリコン積層が必要になります。
その結果、3D シリコン積層と 2.5D パッケージングを組み合わせた 3.5D 統合が、今後 10 年間の次世代 XPU の選択技術になる見込みです。
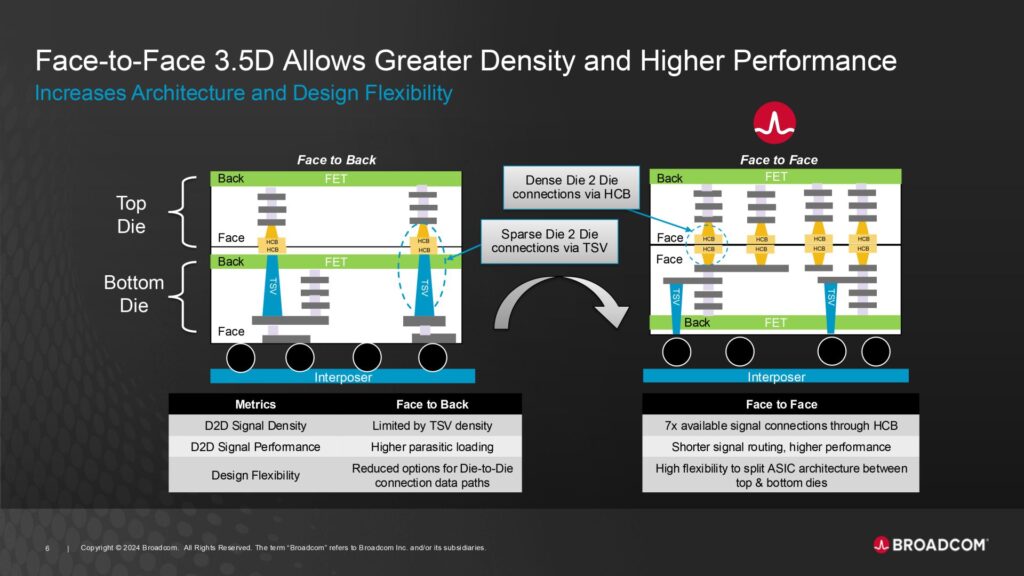
Broadcom の 3.5D XDSiP プラットフォームは、Face-to-Back (F2B) アプローチと比較して、相互接続密度と電力効率を大幅に改善します。
この革新的な F2F スタッキングは、トップ ダイとボトム ダイのトップ メタル層を直接接続し、電気的干渉を最小限に抑え、優れた機械的強度を備えた高密度で信頼性の高い接続を実現します。
Broadcom の 3.5D プラットフォームには、電源、クロック、および信号の相互接続のための 3D ダイ積層を効率的にコレクト バイ コンストラクションするための IP と独自の設計フローが含まれています。
Broadcom の 3.5D XDSiP の主な利点
- 相互接続密度の向上: F2B テクノロジと比較して、積層ダイ間の信号密度を 7 倍に高めます。
- 優れた電力効率: プレーナ型ダイ間 PHY の代わりに 3D HCB を使用することで、ダイ間インターフェイスの消費電力を 10 倍削減します。
- レイテンシの削減: 3Dスタック内のコンピュート、メモリ、I/Oコンポーネント間のレイテンシを最小化します。
- コンパクトなフォームファクタ: インターポーザとパッケージの小型化を可能にし、コスト削減とパッケージ反りの改善をもたらします。
Broadcom がリードする F2F 3.5D XPU は、TSMC の最先端プロセス ノードと 2.5D CoWoS パッケージング テクノロジーを活用して、4 つのコンピュート ダイ、1 つの I/O ダイ、6 つの HBM モジュールを統合しています。
業界標準のツールをベースに構築された Broadcom 独自の設計フローと自動化手法により、非常に複雑なチップであるにもかかわらず、ファーストパスで成功を収めることができました。
3.5D XDSiP は、高速 SerDes、HBM メモリ インターフェイス、ダイ間相互接続など、重要な IP ブロック全体で完全な機能と卓越した性能を実証しました。
この成果は、複雑な 3.5 次元集積回路の設計とテストにおける Broadcom の専門知識を裏付けるものです。
TSMCとBroadcomは過去数年にわたり緊密に協力し、TSMCの最先端ロジック・プロセスと3Dチップ積層技術をBroadcomの設計専門知識と融合させてきました。
このプラットフォームを製品化することで、AIのイノベーションを引き出し、将来の成長を可能にすることを楽しみにしています。
- TSMC 事業開発・グローバル営業担当副社長兼副COO ケビン・チャン博士
5 つ以上の 3.5D 製品を開発中で、Broadcomのコンシューマ AI 顧客の大半が 3.5D XDSiP プラットフォーム テクノロジーを採用し、2026 年 2 月から量産出荷を開始しています。
Broadcomの3.5Dカスタム コンピュート プラットフォームの詳細については、ここをクリックしてください。
解説:
BreadcomのAI向けXPU
知っている方も多いと思いますが、XPUとは様々な用途を想定したプロセッサの総称です。
CPU、GPUのみならず、近年ではNPU(ニューラル)、TPU(Tensor)、LPU(Langueage=LLM向け)様々な用途を想定したプロセッサが出ています。
これらの総称ということになります。
NVIIDAのGeforceではレンダリング処理にAIを適用するためにGPUという体裁を崩していませんが、その他のものの中にはすでに画像を処理する能力を潔く取っ払ったものもあります。
BroadcomのXPUはAI処理に特化し、GPU形式では近い将来に限界が来るとの考え方に立っています。
AI処理には
- サーバー向け=トレーニング
- エッジデバイス=推論
が主な用途と思います。
現状での一般消費者向けAIはGPUを使って一部トレーニングも行っていますが、LoRAのような低ランクの学習においてもかなりの時間がかかりますので、一般向けには学習は難しくなっていくかもしれません。
NVIDIAは現時点ではあくまでもレンダリングの中でAIを活用していく方針のため、こういったXPUのようなAI処理のみを行うプロセッサの活用には積極的ではないようです。
CPUにくっついているNPUのようなものもありますが、AI処理は現時点では一番効率が良いため、今後あらゆるところにAI用の演算ユニットが実装されていくことと思います。
今後どのようにわたくしたちのところに降りてくるかわかりませんが、BroadcomのXPUのような仕組みはNVIDIA製品のようにGPUの中のAI処理と対極にあるのは確かだと思います。