■事実
NVIDIAは3月11日、オープンモデルシリーズ「Nemotron 3」の新モデル「Nemotron 3 Super」を公開した。
Nemotron 3 Superは総パラメータ数1,200億(120B)、推論時のアクティブパラメータ数は120億(12B)のMoE(Mixture of Experts)モデルだ。
アーキテクチャにはMamba-Transformerのハイブリッド設計を採用している。Mambaレイヤーがシーケンス処理の大半を担い、Transformerレイヤーが高度な推論を処理する構造で、両者が相互補完的に動作する。
LatentMoE(潜在MoE)は今回初めて導入された新技術だ。トークン生成時に1つ分のコストで4人の専門エキスパートを起動することで、精度向上と演算効率を両立する。
MTP(Multi-Token Prediction)レイヤーにより複数トークンを同時予測でき、推論速度が大幅に向上する。NVIDIAはこれをネイティブの投機的デコードとも位置づけている。
コンテキストウィンドウは最大100万トークン(1Mトークン)をサポートする。
事前学習はNVFP4(NVIDIA独自の4ビット浮動小数点形式)で実施された。学習開始時から4ビット精度で訓練する方式で、後から量子化するアプローチとは設計思想が根本的に異なる。
学習は事前学習→SFT(Supervised Fine-Tuning)→強化学習(RL)の3フェーズで実施された。強化学習フェーズでは15以上のインタラクティブな環境を用いており、ソフトウェア開発エージェントやツール拡張型サーチなど、実際のエージェントタスクを模した動的シミュレーションループで訓練されている。
学習データは重複排除後の固有トークン10兆を含む計25兆トークン規模で、推論・コーディングに重点を置いた追加学習も含む。
前世代のNemotron Superモデルと比較して、スループットは最大5倍、精度は最大2倍向上したとNVIDIAは述べている。
同規模の競合モデルとの比較では、GPT-OSS-120Bに対して最大2.2倍、Qwen3.5-122Bに対して最大7.5倍のスループットを実現するとしている(入力8k/出力16kトークン設定)。
PinchBench(エージェントAIシステム向けベンチマーク)では85.6%のスコアを記録し、オープンモデル部門でトップとなった(グラフ参照)。
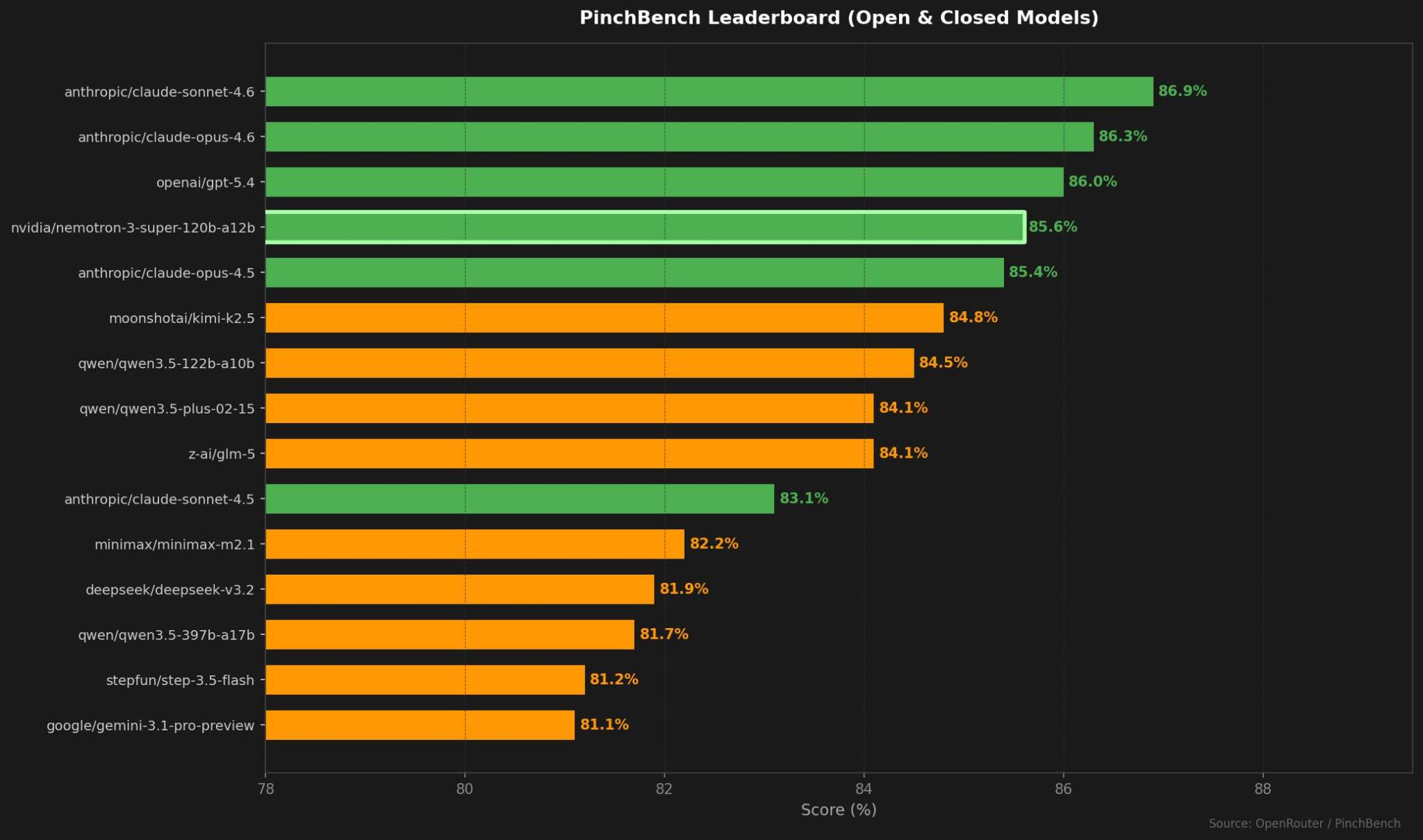{kind=link}
※ 画像をクリックすると別Window・タブで拡大します。
※上記グラフはOpenRouterのPinchBenchリーダーボードをもとに再構成。NVIDIA・Anthropic・OpenAIモデルを緑、その他を橙で色分け。NVIDIAモデルは枠線で強調。
Nemotron 3ファミリーのラインアップは、Nano(30B、2025年12月公開済み)・Super(120B、今回公開)・Ultra(500B規模、2026年後半公開予定)の3モデルで構成される。
主なターゲットユースケースとしてNVIDIAはソフトウェア開発エージェント、長文書分析、ツール呼び出し(ファンクションコーリング)、サイバーセキュリティのトリアージを挙げている。
公開されているリソースはモデルウェイト(NVFP4・FP8・BF16の3種)、学習データセット、学習レシピ、強化学習環境(NeMo Gym)、vLLM/SGLang/TensorRT LLM向けの各推論クックブックを含む。
アクセス手段はbuild.nvidia.com、Hugging Face、OpenRouter、Perplexityの4経路。
クラウド・推論パートナーとしてはGoogle Cloud Vertex AI、Oracle Cloud Infrastructure、CoreWeave、Together AI、Baseten、Cloudflare、DeepInfra、Fireworks AI、Modalが参画している。
オンプレミス・クラウド展開向けにNVIDIA NIM(NVIDIA Inference Microservice)としてもパッケージ化されており、DellはDell Enterprise Hubを通じたオンプレミス最適版の提供を進めている。
NVIDIA AI-Qリサーチエージェントにも採用され、DeepResearch BenchおよびDeepResearch Bench IIのリーダーボードで1位を獲得している。
今回のモデル公開はGTC 2026(3月16〜19日、サンノゼ)と同週に行われており、ハードウェアとモデルの両面を同時に世界へ示すタイミングをNVIDIAが意識していることがうかがえる。
■解説
正直、NVIDIAがオープンモデルでここまで本気を出してくるとは思っていませんでした。
Nemotron 3 Superのアーキテクチャで最も注目すべきなのはMambaレイヤーの役割です。
従来のTransformerはコンテキストウィンドウが大きくなるほど計算量が二乗で増えていく——これがLLMにおける「長文処理の限界」問題の本質でした。MambaのベースになるSSM(State Space Model)はシーケンス長に対して処理コストが線形にスケールするため、100万トークンという規模でも現実的なコストで動かすことができる。「理論上は大きいが実用は厳しい」という状況から、文字通り実用域に引き下ろしてくる構造的な変化です。
MoEと組み合わさることで、120Bの総パラメータを持ちながら推論時には12Bしか動かさない。コスト構造がほぼデンスモデルの10分の1という計算になりますから、推論費用の面では相当に有利になります。
一方でPinchBenchというベンチマークについては少し慎重に見た方がいいと思っています。
NVIDIAが特定のエージェントフレームワーク向けに設計したベンチマークであり、自社モデルが有利になるようタスク選択が行われた可能性は否定できません。「オープンモデル部門1位」という表現は、より正確には「NVIDIAが設定したベンチマーク上での1位」と読む必要があります。
ただし、OpenRouterのリーダーボードでも85.6%と上位に食い込んでいる点は見逃せません。第三者集計の汎用ベンチマークでclaude-opus-4.5(85.4%)とほぼ同等スコアを出しているのは素直に評価できます。ベンチマーク設計の恣意性を差し引いても、モデル自体の実力は本物と見ています。
マルチエージェントシステムでは複数のエージェントがコンテキストを受け渡すため、ラウンドごとにトークン数が爆発的に膨れ上がります。コードベース全体を一度にロードしてエンドツーエンドでデバッグする、数千ページの財務レポートを再推論なしに処理する——これらは従来のモデルにとって現実的ではなかったユースケースです。Mambaの長コンテキスト処理と高スループットはこの問題に直接刺さる設計になっています。
今回の公開範囲がモデルウェイトにとどまらず、学習データ・レシピ・強化学習環境まで含む点はこの業界では珍しい対応です。研究者や企業が自社ドメイン向けにファインチューニングする際の参入コストを大幅に下げることになる。「オープン」を謳うだけで実態は重みだけ、という「疑似オープン」とは一線を画しています。
ただし、ひとつ実用面で補足しておくと、Nemotron 3 Superを実際に動かすにはHGXクラスのマルチGPU環境が必要で、8GPU構成での推論が推奨されています。個人や中小企業が手元で動かすには現実的ではない。「オープン」といっても誰もがすぐ使えるモデルではなく、クラウド経由のAPIか、大型データセンターを持つ組織が実質的な対象になります。
そしてオープンソースである以上、利用責任はユーザー側に移る部分が増えることも忘れてはいけません。商業利用可能なNVIDIA Open Model Licenseが適用されますが、悪意ある利用に対するガードレールはNVIDIAがコントロールしきれない領域に広がります。便利さと責任の転嫁は、オープンモデル全般に共通する課題です。
個人的に注目しているのは2026年後半に控えているNemotron 3 Ultraです。
500B規模のモデルが同じMamba-MoEアーキテクチャで登場するとすれば、GPT-5クラスのプロプライエタリモデルとの直接比較になる。しかも「オープン」でアクセスできる形で、です。そこまで来ると、APIアクセスコストを根拠としたクローズドモデルの価格的優位がかなり揺らぐことになります。
NVIDIAがチップだけでなくモデルレイヤーでも影響力を持つ世界——インフラ、チップ、クラウド、モデル、アプリケーションの全レイヤーをNVIDIAが手がける未来は、AI産業の権力構造として相当に考えさせられるものがあります。