安定した拡散で最大70%のスピードアップ
Nvidiaは、AI/ML(人工知能/機械学習)およびLLM(大規模言語モデル)ツール群のさらなる改良に忙しく取り組んでいる。
最近追加されたのはTensorRTとTensorRT-LLMで、Stable DiffusionやLlama 2テキスト生成などのタスクを実行するために、コンシューマー向けGPUや多くの最高級グラフィックカードの性能を最適化するように設計されている。
私たちは、TensorRTを使用してNvidiaの最新GPUのいくつかをテストし、Stable Diffusionのパフォーマンスが最大70%向上することを確認しました。
TensorRTは現在、NvidiaのGithubページからダウンロード可能になっているはずだが、我々はこの初回調査のために早期アクセスした。
我々は、過去1年ほどの間にStable Diffusionで多くの動きを見てきた。私たちが最初に見たのはAutomatic1111のwebuiを使ったもので、当初はWindowsでNvidia GPUのみをサポートしていた。
それ以来、フォークや画像AI生成ツールの代替テキストの数は爆発的に増え、AMDとIntelの両社は、Nvidiaのパフォーマンスとの差をいくらか縮める、より細かく調整されたライブラリをリリースした。
最新のStable Diffusionベンチマークは、AMD RX 7800 XTとRX 7700 XTのレビューでご覧いただけます。
そして今、NvidiaはTensorRTで再び差を広げようとしている。
基本的な考え方は、AMDやインテルがすでに行っていることに似ている。
AIやMLのモデルや演算子のためのオープンフォーマットであるONNXを活用し、ベースとなるHugging Face安定拡散モデルをONNXフォーマットに変換する。
そこから、使用している特定のGPU用にパフォーマンスをさらに最適化することができます。
TensorRTのチューニングには数分(場合によってはそれ以上)かかりますが、いったん完了すれば、メモリ使用率の向上とともに、パフォーマンスが大幅に向上するはずです。
私たちは、Nvidiaの最新のRTX 40シリーズGPUをすべてチューニング・プロセスにかけました(最適なパフォーマンスを得るためには、それぞれ個別に行う必要があります)。
最新の最適化されたツールを使って多くのGPUを再テストしているため、Stable DiffusionでAMD、Intel、Nvidiaのパフォーマンスを比較する完全なアップデートの準備がまだ整っていません。
TensorRTの効果がNvidiaのすべてのRTXシリーズに適用されることを示すため、念のためRTX 30シリーズを1つ含み、近日中にRTX 20シリーズを1つ追加する予定です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
※ 画像をクリックすると別Window・タブで拡大します。
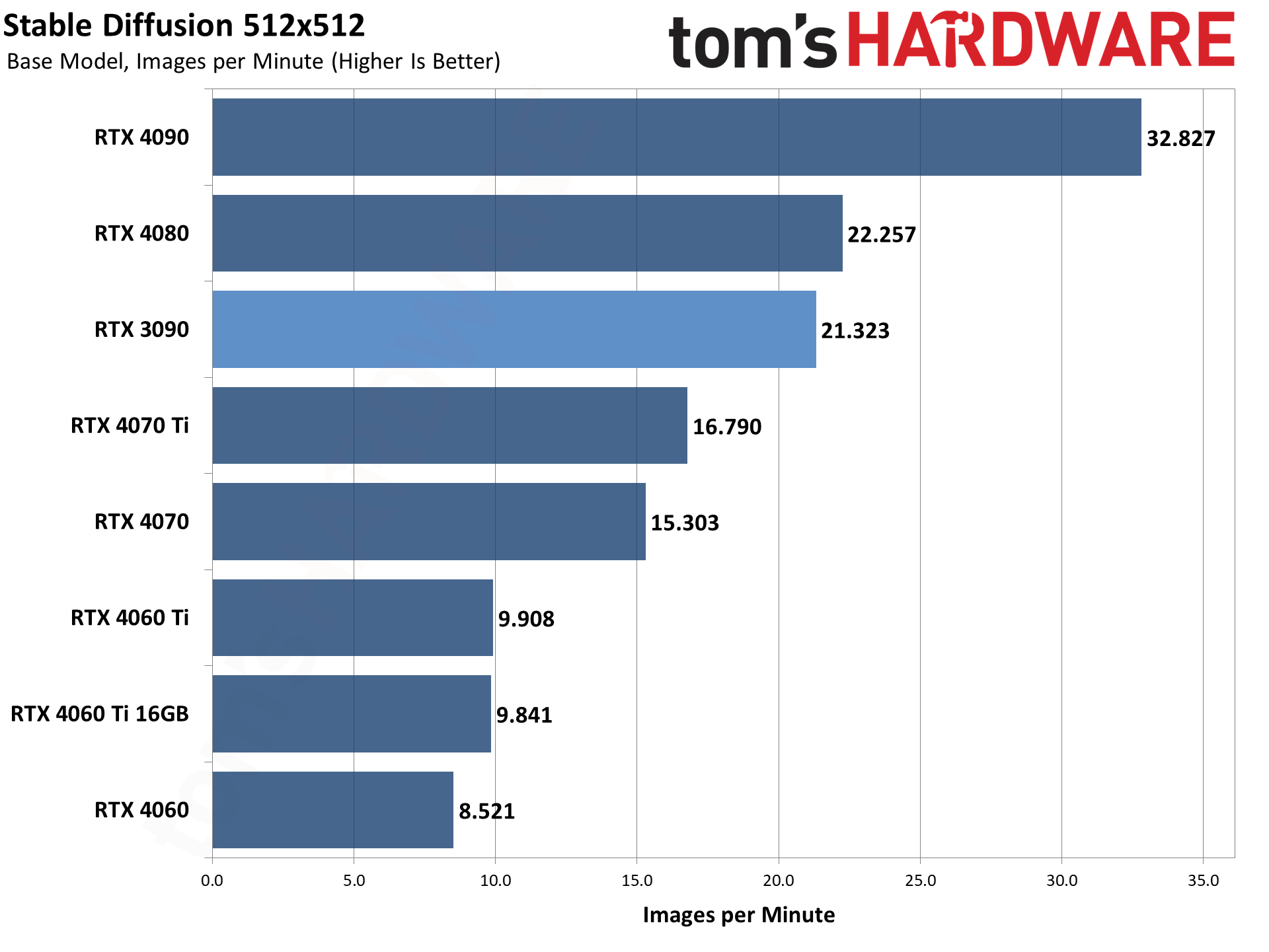
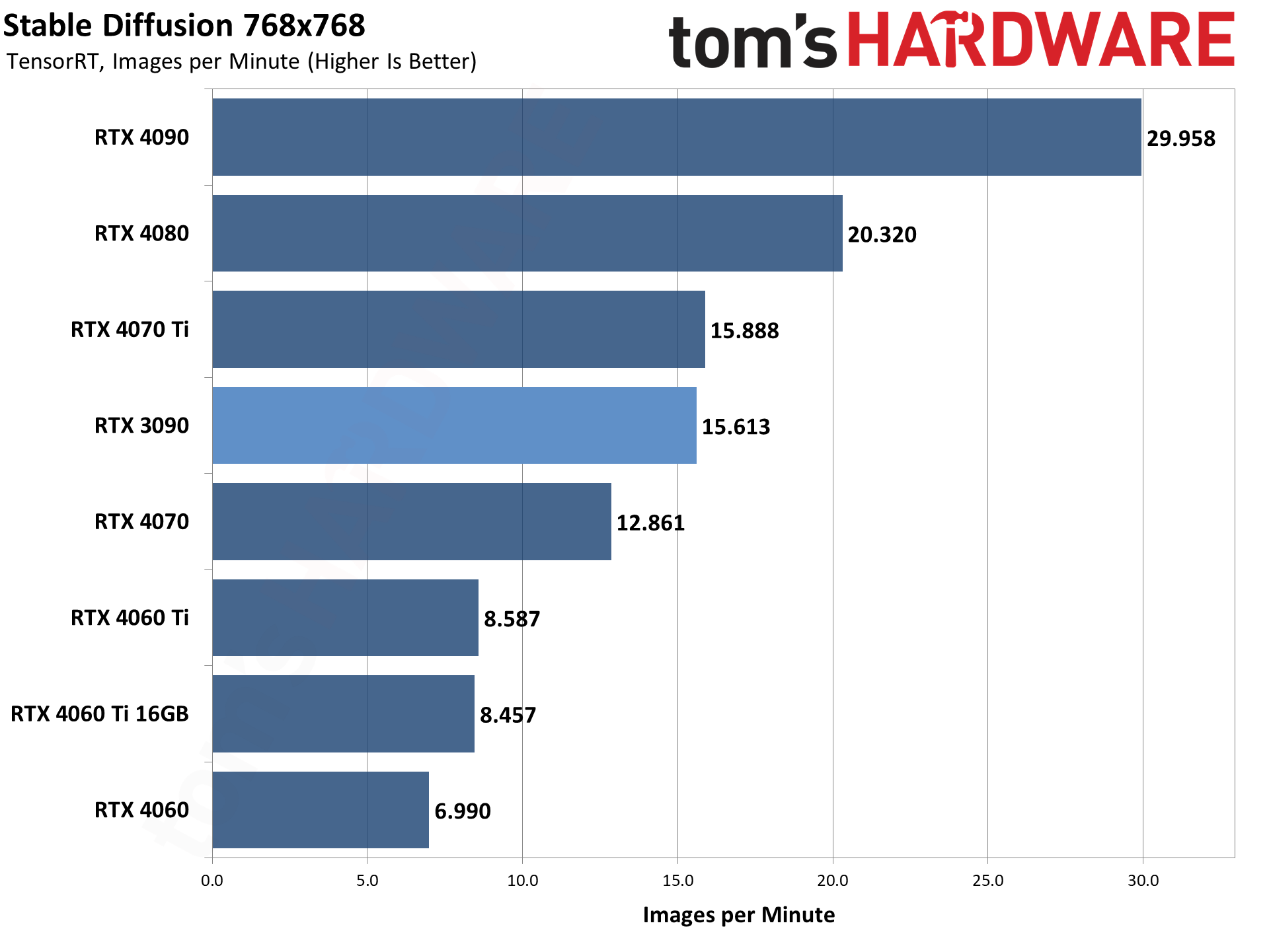
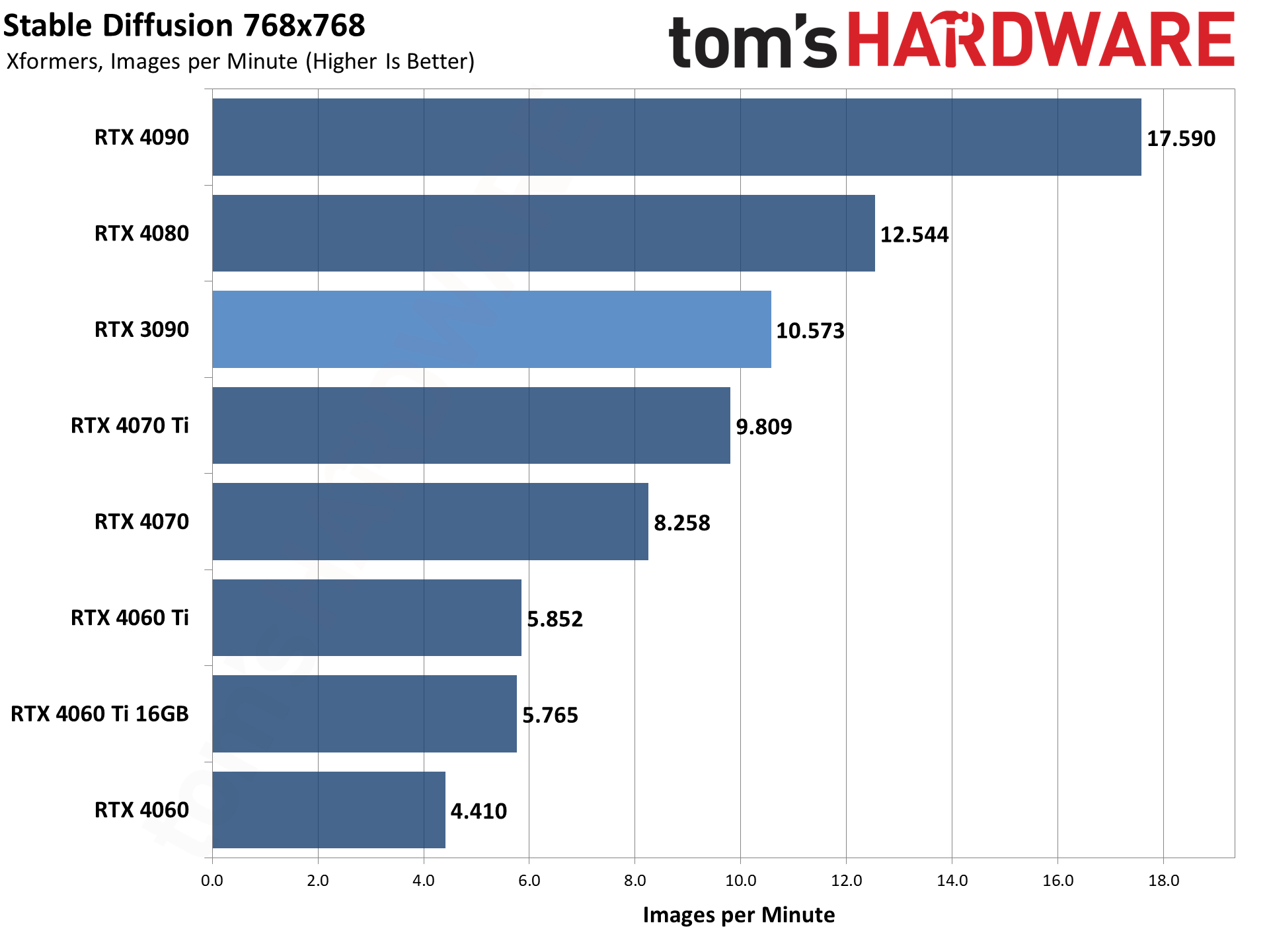
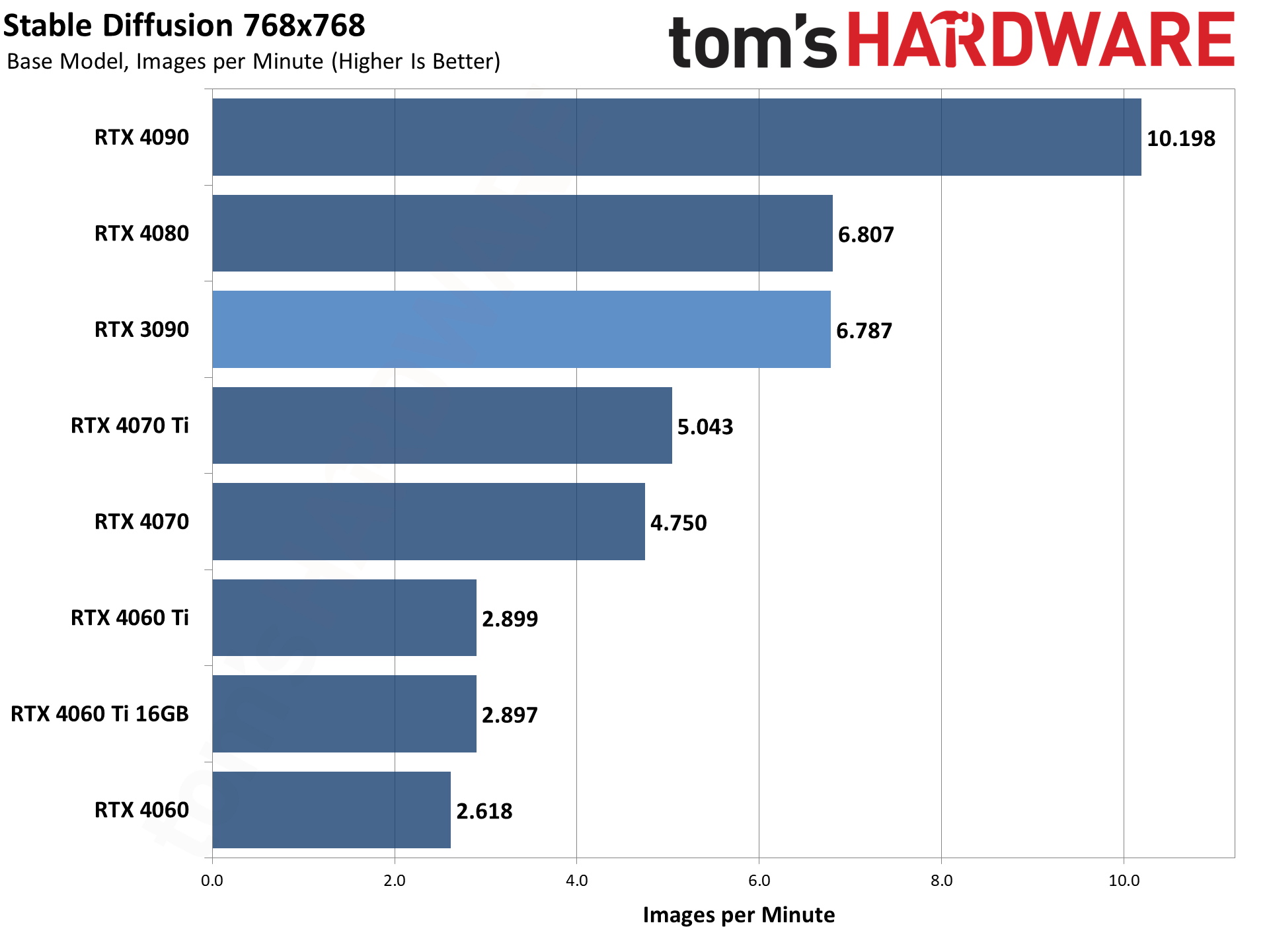
上記の各ギャラリーは、512×512と768×768で、Stable Diffusion 1.5のモデルを使用しています。
クリエイターコミュニティが一般的に1.5の結果を好んでいるようなので、2.1ではなく1.5を使用するように “回帰 “しましたが、一般的な結果は新しいトレーニングモデルでも同じはずです。
各GPUについて、最適なスループットを見つけるために、異なるバッチサイズとバッチ数を実行し、1回の実行で合計24枚の画像を生成しました。
その後、3回の実行のスループットを平均して全体のレートを決定しました。つまり、モデルフォーマットとGPUごとに合計72枚の画像が生成されました。
全体的なスループットには、さまざまな要因が絡んできます。
GPUの演算能力は、メモリ帯域幅と同様にかなり重要です。VRAM容量は、より大きな画像解像度のターゲットやバッチサイズを可能にする可能性があること以外は、あまり重要でない傾向がある。
つまり、8GBでは不可能なことが、24GBのVRAMでは可能になるということです。
L2キャッシュのサイズも関係してくるかもしれませんが、私たちはこれを直接モデル化しようとはしませんでした。
言えることは、基本的に同じスペックの4060 Ti 16GBと8GBカードは(16GBのカスタムモデルによりクロックが若干異なる)、ほぼ同じパフォーマンスと最適なバッチサイズだったということだ。
使用するモデル形式によって、相対的なパフォーマンスには若干の違いがあります。
ベースモデルは最も遅く、Xformersは512×512の画像で30~50パーセント、768×768の画像で50~100パーセント性能を向上させます。
TensorRTはさらに512×512で40~65パーセント、768×768で25~70パーセント性能を向上させます。
興味深いのは、XformersとTensorRTの両方で、(これまでにテストされたGPUで)最小の利益がすべてRTX 3090から得られていることです。
これは異なるアーキテクチャに基づく理にかなっている。RTX 4000シリーズには第4世代のTensorコアがあり、RTX 3000シリーズには第3世代のTensorコアがあり、RTX 20シリーズには第2世代のTensorコアがあります(Voltaアーキテクチャには第1世代のTensorがあります)。
つまり、新しいアーキテクチャの方がより高性能なはずだ。RTX 20シリーズが新しいGPUと比べてどのようにスケールするかは、(もう少ししたら……)見てみなければならないだろう。
私たちは、これを完全なNvidia対世界の性能比較にしようとしているわけではありませんが、例としてRX 7900 XTXの最新のテストでは、512×512で1分あたり約18~19枚の画像が最高で、768×768では1分あたり約5枚の画像が最高です。
我々は、最新のAutomatic1111 DirectMLブランチでAMD GPUの完全なテストに取り組んでおり、それが完了したら、安定した拡散の大要を更新する予定です。
また、IntelのArc A770は、512×512で15.5画像/分、768×768で4.7画像/分です。
では、TensorRTがこれほどまでにパフォーマンスを向上させることができるのは、一体何が起こっているからなのだろうか?
私はこのトピックについてNvidiaに話を聞いたが、それは主にリソースとモデルフォーマットの最適化についてだ。
ONNXはもともとフェイスブックとマイクロソフトによって開発されたが、Apacheライセンスモデルに基づいたオープンソースのイニシアチブである。
ONNXは、AIモデルを多種多様なバックエンドで使用できるように設計されている: PyTorch、OpenVINO、DirectML、TensorRTなどだ。
ONNXは、さまざまなAIモデルを共通に定義することができ、必要な組み込み演算子や標準データ型のセットとともに計算グラフモデルを提供します。
これにより、様々なAIアクセラレーション・フレームワーク間でモデルを簡単に転送することができる。
一方、TensorRTは、Nvidia GPU上でより高い性能を発揮するように設計されている。TensorRTを利用するためには、開発者は通常、モデルをTensorRTが期待する形式に直接記述するか、既存のモデルをその形式に変換する必要がある。
ONNXは、このプロセスを簡素化するのに役立ちます。そのため、AMD(DirectML)とIntel(OpenVINO)は、Stable DiffusionのチューニングされたブランチにONNXを採用しています。
最後に、TensorRTのオプションの1つは、モデルを使って最適なパスをチューニングできることだ。
今回のケースでは、512×512と768×768の画像をバッチ処理しています。
私たちが生成する一般的なTensorRTモデルは、動的な画像サイズが512×512から1024×1024、バッチサイズが1から8、最適な構成が512×512、バッチサイズが1かもしれません。
そこで、512x512x8や768x768x4などをターゲットにした別のTensorRTモデルを作ることができる。
そして、それぞれのGPUに最適な構成を見つけるために、これらすべてを行いました。
AMDのDirectMLフォークにも似たようなオプションがありますが、現時点ではいくつかの制限があります(例として、1つ以外のバッチサイズはできません)。
私たちは、AMDとIntelのモデルについてもさらなるチューニングを期待していますが、時間の経過とともに利益は先細りになると思われます。
TensorRTのアップデートは、もちろんStable Diffusionのためだけではない。Nvidiaは、TensorRTを使用したLlama 2 7B int4推論で測定された改善の詳細について、上記のスライドを共有した。これは、70億個のパラメータを持つテキスト生成ツールだ。
グラフが示すように、1つのテキストバッチを生成すると、そこそこの効果が得られるが、この場合のGPU(RTX 4090)はフル稼働していないようだ。
バッチサイズを4つに増やすと、全体のスループットが3.6倍向上し、バッチサイズを8つにすると4.4倍高速化する。
この場合、バッチサイズを大きくすることで、複数のテキスト回答を生成することができ、ユーザーは好みのものを選択することができる。
TesorRT-LLMはまだリリースされていないが、近い将来developer.nvidia.com(無料登録が必要)で入手できるようになるだろう。
最後に、LLMのAIに特化したアップデートの一環として、NvidiaはTensorRT-LLMツールの開発にも取り組んでいる。
このツールでは、Llama 2を基本モデルとして使用し、よりドメイン固有の最新の知識を得るためにローカルデータをインポートすることができる。
このツールで何ができるかの一例として、Nvidiaは最近のNvidiaのニュース記事30本をこのツールにインポートしており、Llama 2の基本モデルとこのローカルデータを使ったモデルの反応の違いを見ることができる。
基本モデルは、意味のある文章を生成する方法などに関するすべての情報を提供しますが、最近の出来事や発表に関する知識はありません。
この場合、『アランウェイク2』は公式な情報が発表されていないことになる。
しかし、更新されたローカルデータを使えば、より意味のある返答ができるようになる。
Nvidiaが提示したもうひとつの例は、このようなローカルデータと自分のメールやチャットの履歴を使うことだ。
そうすれば、”去年、クリスと私はどんな映画について話していましたか?”などと尋ねることができ、その答えを提供することができるだろう。
あなた自身の情報を使った、よりスマートな検索オプションになる可能性がある。
私たちの特定のサーバー(RTXカードが必要なので)で使えるかどうかを確認する必要があるが、これは私たち自身のHammerBotの潜在的なユースケースと見なさずにはいられない。
他のLLMと同様に、結果はトレーニングデータと質問によって少し質が変わる可能性がある。
Nvidiaはまた、RTX 2000シリーズGPUのサポートとネイティブなアーティファクト低減を備えたVideo Super Resolutionのアップデートも発表した。
後者は、1080pモニターで1080pストリームを見ている場合でも、VSRがノイズ除去や画像強調に役立つことを意味する。
VSR 1.5は、Nvidiaの最新ドライバで利用可能です。
ソース:Tom’s Hardware – Nvidia Boosts AI Performance With TensorRT
解説:
TensorRTで生成AIの性能を強化
さて、TensorRTの恩恵を受けるにはonnx形式に変換する必要があります。
記事中にもある通り既にAMDやIntelも同じ手法で自社製GPUの性能を強化してきました。
AI/MLのデファクトスタンダードであるnVIDIAですから、これからonnx形式のデータでの配布が流行る・・・と言いたいところですが、現実問題として流行はしないのではないかと思います。
もちろんですが、総ての学習済みモデルデータを自前で用意できる組織・企業・団体による利用においてはその限りではありません。
「出来る」と書いてあってもすべてにおいて「出来る」ことが保証されているわけではない。
人は「このようなことが可能ですよ」と書いてあると、自分のやりたいことは全て出来ると勝手に勘違いします。
これは認知バイアスの一種だと思います。
今までのonnx形式において、機材やバックエンドに応じた最適化を行いつつ変換というのはあったわけで、なぜそれが流行らなかったかと言うと、総てのデータが変換できるとは限らないからです。
途中で止まることもしばしばあります。
私がAMDの主張するDirectMLでのMS Oliveを使た高速化においてはデフォルトでインストールされる学習済みモデルデータしか変換できませんでした。
他のonnx形式においてもデータによっては正常に変換するにはスクリプトの書き換えが必要であり、pythonのプログラムの知識が無いと対応できないでしょう。
ホビー用途においてはこうしたことに労力を使うよりは実際にプロンプトでどのようなイラストを生成するかのノウハウをに時間をかけた方が建設的です。
また、AI/ML界隈においてはフレームワークも個別のプログラムも学習済みモデルデータもバージョンアップが頻繁であり、それに一々対応していては多大な労力がかかります。
Googleの出しているTensorFlowなどはWindowsへの対応はやめ、WindowsではWSL2上で使用するように告知しています。
圧倒的に人口が多いWindows+Geforceに対してすらもこの対応ですから、他のプラットフォームでは推して知るべしです。
よって、TensorRTに対応したonnx形式のモデルデータが流行るかどうかで言えば難しいのではないかと思います。
ただ、AI/ML世界のデファクトスタンダードであるnVIDIA製品ですから、流行る可能性は0ではないとだけは言っておきます。
ベンチマークや限られた状況の中で「うちではこのように出来て、高速化を実感できました」と言うことは出来ると思います。
しかし、それが一般に広く使われるかどうかと言うのは未知数ですし、技術を持っている個人・企業・団体はあまり気に留めません。
しかし、学習済みモデルデータを作成する人、使用する個人などではやはり、広く一般に手間をかけずに使えるのかどうか?と言うのが重要であり、そこが保証されない限りは流行するのは難しいでしょう。
VRAM6GBなどの貧弱な環境で使っている人も沢山いるわけですから。
当然ですが、この意見は個人のホビー使用と言う視点で書かれいます。