
中国企業DeepSeekが最新のR1 AIモデルで業界の常識を覆すことに成功したため、AI投資家、特にNVIDIAにとってはあまり良い日ではない。
DeepSeekのR1 AIモデルは、そのトレーニング効率によりAI市場を破壊することに成功した。
もしあなたが岩の下で暮らしていたり、なぜ今「AI市場」がパニックに陥っているのか理解できていないのであれば、この記事は間違いなくあなたのためのものだ。中国が、後ほど説明するが、かなり低い資金力で学習させたとされるAIモデルを発表したことで、過去1年間に目撃された「AIのスーパーサイクル」が誇張されすぎているのか、むしろ資金をつぎ込む価値がないのかという議論が巻き起こっている。
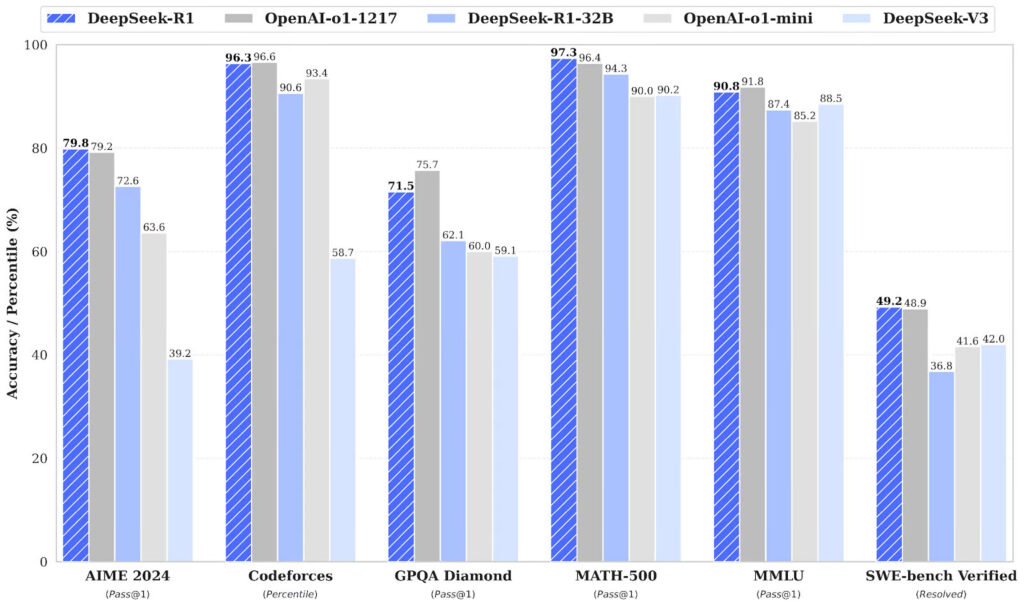
DeepSeek R1は、衝撃的と思われるかもしれない 「とされる 」トレーニング費用で、そこにあるトップエンドのLLMのいくつかと競争することができました。

まず、DeepSeek R1とは何なのか、他とどう違うのかについて説明しよう。R1は、他に類を見ないオープンソースのLLMモデルであり、他のどの代替案も行っていない実装に主に依存していると言われている。
技術的なことはあまり触れませんが、ここで注目すべき重要な点は、R1が「思考の連鎖」プロセスに依存していることです。
つまり、AIモデルにプロンプトが与えられると、最終的な答えに到達するまでのステップと結論を示し、そうすることで、ユーザーはLLMが最初にミスを犯した部分を診断することができます。
DeepSeek R1のもう一つの興味深い事実は、結果を達成するために「強化学習」を使用していることだ。これは機械学習の一種で、モデルが環境と相互作用し、「報酬ベースのプロセス 」を通じて決定を下す。
望ましい結果に到達すると、モデルは報酬が最大となるものを選ぶようにし、こうすることで望ましい結論が確実に達成される。
一方、GPTのo1では、教師あり学習法が中心で、膨大なテキストやコードのデータセットでモデルを訓練する必要があり、最終的にはより多くの資金を必要とする。
資金力といえば、市場ではDeepSeekのトレーニング費用について誤解が多い。というのも、噂されている「560万ドル」という数字はあくまで最終モデルを動かすための費用であり、総費用ではないからだ。
中国は最先端のAIコンピューティング・ハードウェアにアクセスすることを制限されているため、DeepSeekがそのAI兵器を公開することは賢明ではないだろう。
そのため、専門家の認識では、DeepSeekDeepSeekは競合他社と同等の能力を有しているが、今のところ公表されていない。
$NVDA – MUSK SUGGESTS DEEPSEEK ‘OBVIOUSLY’ HAS MORE NVIDIA GPUS THAN CLAIMED
Elon Musk and Alexandr Wang suggest DeepSeek has about 50,000 NVIDIA Hopper GPUs, not the 10,000 A100s they claim, due to U.S. export controls. Musk, with experience from xAI, agrees with Wang’s…
— *Walter Bloomberg (@DeItaone) January 27, 2025
OpenAIのGPT-o1と比較すると、R1はインプットとアウトプットのトークンで約5倍安くなることに成功している。
そのため、市場はこの展開を不安と驚きをもって受け止めている。
しかし、これにはかなり興味深いタッチがあり、次にDeepSeekの達成に人々が慌てないようにする方法について話す。
NVIDIAはAIコンピュート・リソースを販売することで、過去数四半期に巨大な収益を上げており、オープンAIを含むマグニフィセント7の主流企業は、DeepSeekと比較して優れた技術を利用できる。
DeepSeekが限られたコンピューティングでR1を訓練することに成功したことを考えると、強力なコンピューティング・パワーを持つ企業が市場に何をもたらすことができるかを想像してみると、この状況はAI市場の将来に対してより楽観的になる。
NVIDIAのCUDAとその周辺のエコシステムに競合するものはなく、AIが成長技術として台頭している世界では、我々はまだスタート地点に立ったばかりだと言っていいだろう。
DeepSeekの実装は、AIハイプの終わりを示すものではない。
DeepSeekのR1の後、チーム・グリーンが時価総額から3000億ドル以上を削ることに成功したように、市場はあまり楽観視していないが。
しかし、このポジティブな結果に人々が気づけば、塵も積もれば山となることだろう。
さらに、これはMeta、Google、Amazonのような企業がそれぞれのAIソリューションを加速させることを促すだろうし、Cantor Fitzgeraldのアナリストが言うように、DeepSeekの功績はむしろNVIDIAとAIの未来に対してより強気になるはずだ。
解説:
Deepseekが出てからNVIDIAの株価が落ちましたが、昨日回復しています。
答えはDeepseek R1はNVIDIAの中国向けモンキーモデルであるH800で動いていることが明らかになったからです。
結局すべてがNVIDIAの掌の上ということになります。
私もRadeonでいくつかの生成AIを動かしましたが、nVIDIA以外のGPUで機械学習環境を整備するのは簡単ではないです。
まず、pytorchやtensorflowにしても公式が対応するより先に使いたいと思ったら自力でコンパイルするしかありません。
また、周辺のモジュール、ちょっと前だとtritonやbitsandbytesなども自力で該当箇所を書き換えてコンパイルするしかない状況でした。
xformersは最近pytorchの中に同等の機能が取り込まれたようですが、最後までAMDでは動きませんでした。
今は多少マシになっていると思います。
環境を整備するのに多大な労力が必要な他社製のAIアクセラレーターより、いきなりプログラムしたり使ったりするところから始められるNVIDIAの製品だと比較にすらならないです。
IntelのoneAPIやAMDのROCmもNVIDIA互換を基本としています。
ROCm(HIP)は書き換えはわずかで済みますが、それでも思ったように普及が進まないのはやはり労力が必要となるからにほかなりません。
NVIDIA向けのバイナリをそのまま使えるZLUDAはやはり違法認定されてしまいましたからね。
今年から各社からAIハードウェアアクセラレーターが発売されますが、カギになるのはNVIDIA環境とどれくらい同じことができるかです。
そこが無理ならば普及させるのは並大抵ではないと思います。